Refine search
Actions for selected content:
63 results
5 - The ICC’s Track Record
-
- Book:
- Above the Law
- Published online:
- 20 November 2025
- Print publication:
- 31 December 2025, pp 196-228
-
- Chapter
- Export citation

A Hands-On Introduction to Data Science with Python
- Coming soon
-
- Expected online publication date:
- December 2025
- Print publication:
- 31 December 2025
-
- Textbook
- Export citation

A Hands-On Introduction to Data Science with R
- Coming soon
-
- Expected online publication date:
- December 2025
- Print publication:
- 31 December 2025
-
- Textbook
- Export citation
Comprehensive evaluation and exploration of elite resources of Shanlan upland rice for agronomic traits
-
- Journal:
- Plant Genetic Resources , First View
- Published online by Cambridge University Press:
- 21 November 2025, pp. 1-7
-
- Article
- Export citation
Introduction
-
- Book:
- Debts Unpaid
- Published online:
- 04 November 2025
- Print publication:
- 20 November 2025, pp 1-19
-
- Chapter
- Export citation
The Misuse of Normality Tests as Gatekeepers for Research in Prehospital and Disaster Medicine
-
- Journal:
- Prehospital and Disaster Medicine / Volume 40 / Issue 5 / October 2025
- Published online by Cambridge University Press:
- 05 November 2025, pp. 241-242
- Print publication:
- October 2025
-
- Article
-
- You have access
- HTML
- Export citation

Fundamentals of Turbulent Flows
-
- Published online:
- 09 January 2025
- Print publication:
- 12 December 2024
-
- Textbook
- Export citation
24 - Random Factors and Research Generalization
- from Part IV - Understanding What Your Data Are Telling You About Psychological Processes
-
-
- Book:
- Handbook of Research Methods in Social and Personality Psychology
- Published online:
- 12 December 2024
- Print publication:
- 19 December 2024, pp 602-621
-
- Chapter
- Export citation
5 - Reaping Rewards: Deterring Conflict and Gaining Influence
-
- Book:
- Influence without Arms
- Published online:
- 31 October 2024
- Print publication:
- 14 November 2024, pp 142-193
-
- Chapter
- Export citation
The statistical design and analysis of pandemic platform trials: Implications for the future
-
- Journal:
- Journal of Clinical and Translational Science / Volume 8 / Issue 1 / 2024
- Published online by Cambridge University Press:
- 15 October 2024, e155
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - The World of National Security Institutions
-
- Book:
- Bureaucracies at War
- Published online:
- 05 December 2024
- Print publication:
- 27 June 2024, pp 54-81
-
- Chapter
- Export citation
Are Archaeologists Talking About Looting? Reviewing Archaeological and Anthropological Conference Proceedings from 1899–2019
-
- Journal:
- International Journal of Cultural Property / Volume 30 / Issue 4 / November 2023
- Published online by Cambridge University Press:
- 14 May 2024, pp. 361-378
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Compressed earthen blocks using alluvial clays from Mbam: performance comparison using statistical analysis of cement vs heat-stabilized blocks
-
- Journal:
- Clay Minerals / Volume 59 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 24 April 2024, pp. 100-112
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Crystal Chemistry of Corrensite: A Review
-
- Journal:
- Clays and Clay Minerals / Volume 32 / Issue 5 / October 1984
- Published online by Cambridge University Press:
- 02 April 2024, pp. 391-399
-
- Article
- Export citation
Clays, Cations, and Geophysical Log Response of Gas-Producing and Nonproducing Zones in the Gammon Shale (Cretaceous), Southwestern North Dakota
-
- Journal:
- Clays and Clay Minerals / Volume 31 / Issue 2 / April 1983
- Published online by Cambridge University Press:
- 02 April 2024, pp. 122-128
-
- Article
- Export citation
Combining models to generate a consensus effective reproduction number R for the COVID-19 epidemic status in England
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 14 March 2024, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The effective reproduction number
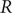 $ R $ was widely accepted as a key indicator during the early stages of the COVID-19 pandemic. In the UK, the
$ R $ was widely accepted as a key indicator during the early stages of the COVID-19 pandemic. In the UK, the 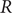 $ R $ value published on the UK Government Dashboard has been generated as a combined value from an ensemble of epidemiological models via a collaborative initiative between academia and government. In this paper, we outline this collaborative modelling approach and illustrate how, by using an established combination method, a combined
$ R $ value published on the UK Government Dashboard has been generated as a combined value from an ensemble of epidemiological models via a collaborative initiative between academia and government. In this paper, we outline this collaborative modelling approach and illustrate how, by using an established combination method, a combined 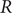 $ R $ estimate can be generated from an ensemble of epidemiological models. We analyse the
$ R $ estimate can be generated from an ensemble of epidemiological models. We analyse the 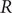 $ R $ values calculated for the period between April 2021 and December 2021, to show that this
$ R $ values calculated for the period between April 2021 and December 2021, to show that this 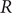 $ R $ is robust to different model weighting methods and ensemble sizes and that using heterogeneous data sources for validation increases its robustness and reduces the biases and limitations associated with a single source of data. We discuss how
$ R $ is robust to different model weighting methods and ensemble sizes and that using heterogeneous data sources for validation increases its robustness and reduces the biases and limitations associated with a single source of data. We discuss how 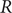 $ R $ can be generated from different data sources and show that it is a good summary indicator of the current dynamics in an epidemic.
$ R $ can be generated from different data sources and show that it is a good summary indicator of the current dynamics in an epidemic.
Discriminant Analysis of Clay Mineral Compositions
-
- Journal:
- Clays and Clay Minerals / Volume 52 / Issue 3 / June 2004
- Published online by Cambridge University Press:
- 01 January 2024, pp. 311-320
-
- Article
- Export citation
5 - Invocations for Counsel, the Rulings, and the Courts: A Statistical Analysis of the Corpus
-
- Book:
- Police Interrogation, Language, and the Law
- Published online:
- 23 December 2023
- Print publication:
- 21 December 2023, pp 116-135
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Diverse Science from VLT imagery and spectroscopy of PNe in the Galactic Bulge
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 19 / Issue S384 / December 2023
- Published online by Cambridge University Press:
- 06 October 2025, pp. 102-108
- Print publication:
- December 2023
-
- Article
-
- You have access
- Open access
- Export citation
21 - Meta-analysis: Assessing Heterogeneity Using Traditional and Contemporary Approaches
- from 3 - Methods for Understanding Consumer Psychology
-
-
- Book:
- The Cambridge Handbook of Consumer Psychology
- Published online:
- 30 March 2023
- Print publication:
- 06 April 2023, pp 572-603
-
- Chapter
- Export citation
