

1 The Case for String Diagrams
The Algebraic Structure of Programs
When learning a programming language, one of the most basic tasks is understanding how to correctly write programs in the language’s syntax. This syntax is often specified inductively, as a context-free grammar. For instance, the grammar shown in (1.1) defines the syntax of a very elementary imperative programming language, where variables  and natural numbers
and natural numbers  may occur:
may occur:
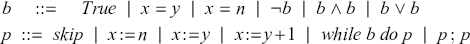 (1.1)
(1.1)
With the second row of the grammar, we can write arbitrary programs  featuring assignment of a value to a variable, while loops, and program concatenation. In particular, while loops will depend upon a Boolean expression
featuring assignment of a value to a variable, while loops, and program concatenation. In particular, while loops will depend upon a Boolean expression  , whose construction is dictated by the first row of the grammar. For practitioners, this information is essential to correctly write code in the given language: an interpreter will only execute programs that are written according to the grammar. For computer scientists, who are interested in formal analysis of programs, this information has deeper consequences: it gives us a powerful tool to prove mathematical properties of the language by induction over the syntax. This principle is a generalisation of how we usually reason about the natural numbers. Indeed, the set
, whose construction is dictated by the first row of the grammar. For practitioners, this information is essential to correctly write code in the given language: an interpreter will only execute programs that are written according to the grammar. For computer scientists, who are interested in formal analysis of programs, this information has deeper consequences: it gives us a powerful tool to prove mathematical properties of the language by induction over the syntax. This principle is a generalisation of how we usually reason about the natural numbers. Indeed, the set  of natural numbers can also be specified via a grammar:
of natural numbers can also be specified via a grammar:
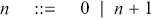 (1.2)
(1.2)
When proving properties of  by induction, what we are really doing is reasoning by case analysis on the clauses of grammar (1.2). For instance, suppose we wish to prove by induction that, for each
by induction, what we are really doing is reasoning by case analysis on the clauses of grammar (1.2). For instance, suppose we wish to prove by induction that, for each  ,
,  . In the base case, we assume that
. In the base case, we assume that  is
is  ; we can verify that
; we can verify that  . In the inductive step, we consider the case that
. In the inductive step, we consider the case that  is
is  for some
for some  . If we assume
. If we assume  , then we can show the statement for
, then we can show the statement for  , as follows:
, as follows:  .
.
In the same way, we can reason by induction on programs, whenever their syntax is specified by a grammar such as (1.1). For example, we can prove that a certain property  holds for any program
holds for any program  defined by (1.1), as follows: first, we need to show that
defined by (1.1), as follows: first, we need to show that  holds for skip,
holds for skip,  ,
,  , and
, and  . Then, assuming
. Then, assuming  holds for
holds for  , we show that it holds for while b to p. Finally, assuming
, we show that it holds for while b to p. Finally, assuming  holds for
holds for  and
and  , we show that it holds for
, we show that it holds for  .
.
This style of reasoning is extremely useful for several tasks. For instance, we may prove by induction important properties of our program, such as its correctness, safety, or liveness, as studied in the research area of formal verification. We may also define the semantics by induction, that is, assign programs their behaviour in a way that respects their structure. In programming language theory, there are usually two different ways of defining the semantics of a language: operational and denotational. The former specifies directly how to execute every expression, while the latter specifies what an expression means by assigning it a mathematical object that abstracts its intended behaviour. An inductively defined semantics is particularly important because it enables compositional (or modular) reasoning: the meaning of a complex program may be entirely understood in terms of the semantics of its more elementary expressions. For instance, if our semantics associates a function  to each program
to each program  , and associates to
, and associates to  the composite function
the composite function  , that means that the semantics of the expression
, that means that the semantics of the expression  exclusively depends on the semantics of the simpler expressions
exclusively depends on the semantics of the simpler expressions  and
and  .
.
Moreover, the description of a language as a syntax equipped with a compositional semantics informs us about the algebraic structures underpinning program behaviour. For instance, in any sensible semantics, the program constructs; and  of the grammar (1.1) acquire a monoid structure, with the binary operation; as its multiplication and the constant skip as its identity element. Indeed, the laws of monoids, namely that
of the grammar (1.1) acquire a monoid structure, with the binary operation; as its multiplication and the constant skip as its identity element. Indeed, the laws of monoids, namely that  (associativity) and
(associativity) and  (unitality), will usually hold for the semantics of these operations.
(unitality), will usually hold for the semantics of these operations.
Graphical Models of Computation
As we have seen, defining a formal language via an inductively defined syntax brings clear benefits. However, not all computational phenomena may be adequately captured via this kind of formalism. Think for instance about data flowing through a digital controller. In this model, information propagates through components in complex ways, requiring constraints on how resources are processed. For example, a gate may only receive a certain quantity of data at a time, or a deadlock could occur. Sophisticated forms of interaction, such as entanglement in quantum processes, or conditional (in)dependence between random variables in probabilistic systems, also require a language capable of capturing resource exchange between components in a clear and expressive manner.
Historically, scientists have adopted graphical formalisms to properly visualise and reason about these phenomena. Graphs provide a simple pictorial representation of how information flows through a component-based system, which would otherwise be difficult to encode into a conventional textual notation. Notable examples of these formalisms include electrical and digital circuits, quantum circuits, signal flow graphs (used in control theory), Petri nets (used in concurrency theory), probabilistic graphical models like Bayesian networks and factor graphs, and neural networks. (See Figure 1.1.)
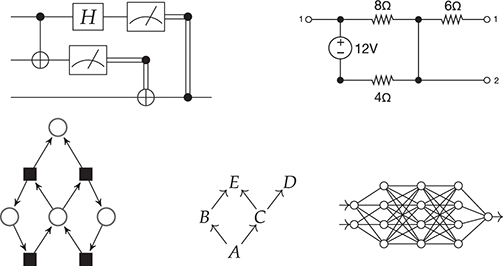
Figure 1.1 Some examples of graphical formalisms: a quantum circuit, an electric circuit, a Petri net, a Bayesian network, and a neural network.
On the other hand, graphical models have clear drawbacks compared to syntactically defined formal languages. Our ability to reason mathematically about combinatorial, graph-like structures is limited. We typically miss a formal theory of how to decompose these models into simpler components, and also of how to compose them together to create more complex models. In short, graphical models are often treated as monolithic rather than modular entities. In turn, this means that we cannot use induction on the model structure to prove their properties, as we would with a standard program syntax. Crucial features of program analysis, such as the definition of a compositional semantics, and the investigation of algebraic structures underpinning model behaviour, face significant obstacles when adapted to graphical formalisms.
String Diagrams: The Best of Both Worlds
String diagrams originate in the abstract mathematical framework of category theory, as a pictorial notation to describe the morphisms in a monoidal category. However, over the past three decades their use has expanded significantly in computer science and related fields, extending far beyond their initial purpose.
What makes string diagrams so appealing is their dual nature. Just like graphical models, they are a pictorial formalism: we can specify and reason about a string diagram as if it was a graph, with nodes and edges. However, just like programming languages, string diagrams may also be regarded as a formal syntax; we can think of them as made of elementary components (akin to the gates of a circuit, but a lot more general than that), composed via syntactically defined operations.
Remarkably, understanding string diagrams as syntactically defined objects does not require switching to a different (textual) formalism – the graphical representation itself is made of syntax (Figure 1.2). The theory of monoidal categories provides a rigorous formalisation of how to switch between the combinatorial and the syntactic perspective on string diagrams, as well as a rich framework to investigate their semantics and algebraic properties. Indeed, like programming languages, we can assign a semantics to string diagrams compositionally, as a functor between categories. This gives us a modular way to specify and reason about the behaviour of the models that they represent.
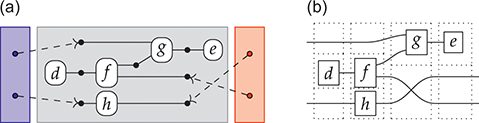
Figure 1.2 An example of a string diagram regarded as a (hyper)graph (a), with the side boxes signalling the interfaces for composing with other string diagrams, and the same string diagram regarded as a piece of syntax (b), with dotted boxes placed to emphasise where elementary components compose, vertically and horizontally.
String Diagrams in Contemporary Research
Thanks to their versatility, string diagrams are increasingly adopted as a reasoning tool by scientists across various research fields. We may identify two major trends in the use of string diagrams: as a way to reason about graphical models syntactically, and as a way to reason about (textual) formal languages in a more visual, resource-sensitive manner.
Within the first trend, string diagrammatic approaches have enabled the adoption of compositional semantics and algebraic reasoning for graphical formalisms that previously lacked these features. Examples include Petri nets [Reference Bonchi, Holland, Piedeleu, Sobociński and Zanasi16], linear dynamical systems [Reference Baez and Erbele6, Reference Bonchi, Sobociński and Zanasi20, Reference Fong, Sobociński and Rapisarda55], quantum circuits [Reference van de Wetering109], electrical circuits [Reference Boisseau, Sobociński and Kishida11], and Bayesian networks [Reference Fong51, Reference Fritz57, Reference Jacobs, Kissinger and Zanasi75], amongst others (see Figure 1.3). Besides providing a unifying mathematical perspective on these models, string diagrams have also demonstrated the ability to produce tangible outcomes, employable at industrial scale. A convincing example is the ZX-calculus, a diagrammatic language that generalises quantum circuits. It now serves as the basis for the development of state-of-the-art quantum circuit optimisation algorithms [Reference Duncan, Kissinger, Perdrix and Van De Wetering48], and is seeing widespread adoption by companies dealing with quantum computing.
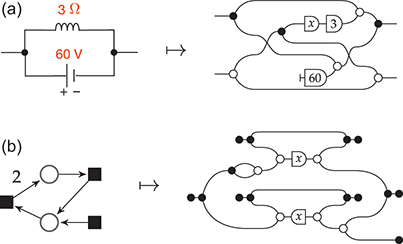
Figure 1.3 String diagrams representing the behaviour of an electrical circuit (a) and a Petri net (b). The abstract perspective offered by the diagrammatic approach reveals that seemingly very different phenomena may be captured via the same set of elementary components.
As examples of the second trend, string diagrams have been instrumental in the development of compilers [Reference Muroya and Dan95] for higher-order functional languages, and in a provably sound algorithm for reverse-mode automatic differentiation [Reference Alvarez-Picallo, Ghica, Sprunger, Zanasi, Klin and Pimentel3]. In both these examples, string diagrams serve as an intermediate formalism that sits between high-level programming languages and lower-level implementations. As the former, they can be manipulated syntactically. As the latter, they explicitly represent information propagation and other structural properties of systems (see Figure 1.4).

Figure 1.4 A major appeal of string diagrams is resource sensitivity: they uncover any implicit assumption on how resources are handled during a computation. For instance, in these string diagrams resources  and
and  are being fed to processes
are being fed to processes  and
and  . Suppose applying
. Suppose applying  to
to  is an expensive computation. In the scenario where
is an expensive computation. In the scenario where  receives the value
receives the value  twice, we are able to distinguish the case where we duplicate
twice, we are able to distinguish the case where we duplicate  and then feed it to
and then feed it to  (a), and the more efficient way, where we duplicate
(a), and the more efficient way, where we duplicate  (b). Note that traditional algebraic syntax would represent both cases as the same term,
(b). Note that traditional algebraic syntax would represent both cases as the same term,  .
.
Outline
This introduction provides a basic overview of string diagrams and their applications. Section 2 introduces the formal syntax (for the most common variant) of string diagrams, the rules to manipulate them, and equational theories. Section 3 shows how string diagrams may also be thought of as certain (hyper)graphs, thus providing an equivalent combinatorial perspective on these objects. In Section 4, we consider other flavours of string diagrams, which correspond to a different syntax and can be manipulated in more permissive or restrictive ways. Section 5 explains how to assign semantics to string diagrams; we cover common examples of semantics and their equational properties. Section 6 contains pointers to different trends that we do not cover in detail in this introduction. Finally, Section 7 is a non-exhaustive list of applications of string diagrams, both inside and outside of computer science.
The use of category theory is kept to a bare minimum, and we have prioritised intuition over technicalities whenever possible. For the reader’s convenience, we have included an appendix containing the most rudimentary definitions of category theory. However, it should not be treated as an introduction to the topic, for which we recommend [Reference Leinster86].
2 String Diagrams as Syntax
We have seen a couple of examples, (1.1) and (1.2), of how to specify expressions of a formal language via a grammar. In order to generalise this technique to diagrammatic expressions, it is best viewed through the lens of abstract algebra. From an algebraic viewpoint, a grammar is a means of presenting the signature of our language: the list of operations which we may use as the building blocks to construct more complex expressions. Each operation comes with its type, which remained implicit in (1.1) and (1.2). For instance, we may regard  (program composition) in (1.1) as a binary operation, which takes as inputs two programs
(program composition) in (1.1) as a binary operation, which takes as inputs two programs  and
and  as arguments and returns as output a program
as arguments and returns as output a program  as value. The type of this operation is thus
as value. The type of this operation is thus  . Analogously,
. Analogously,  ,
,  ,
,  , and
, and  may be seen as constants (operations with no inputs) of type
may be seen as constants (operations with no inputs) of type  , and the while loop yields an operation of type
, and the while loop yields an operation of type  : given a Boolean expression
: given a Boolean expression  and a program
and a program  , we obtain a program while b do p.
, we obtain a program while b do p.
This example suggests that, more generally, a signature  should consist of two pieces of information: a set
should consist of two pieces of information: a set  of generating operations, and a set
of generating operations, and a set  of generating objects (e.g.
of generating objects (e.g.  ,
,  ), which may be used to indicate the type of operations. Once we fix
), which may be used to indicate the type of operations. Once we fix  , we may construct the expressions over
, we may construct the expressions over  the same way we would build the valid programs out of the grammar (1.1). In algebra, such expressions are called
the same way we would build the valid programs out of the grammar (1.1). In algebra, such expressions are called  -terms.
-terms.
This process works in a fairly similar way for string diagrams, with some key differences. String diagrams will be built from signatures, except that now the type of operations may feature multiple outputs as well as multiple inputs, as displayed pictorially in (2.1). We will also see that variables, usually a building block of  -terms, are not a native concept, but rather something that may be encoded in the diagrammatic representation. More on this point in Example 2.14, and Remarks 2.15 and 5.2.
-terms, are not a native concept, but rather something that may be encoded in the diagrammatic representation. More on this point in Example 2.14, and Remarks 2.15 and 5.2.
Signatures
A string diagrammatic syntax may be specified starting from a signature  , with a set
, with a set  of generating objects and a set
of generating objects and a set  of generating operations. We will refer to either simply as generators when it is clear from the context whether we mean a generating object or operation. Each generating operation
of generating operations. We will refer to either simply as generators when it is clear from the context whether we mean a generating object or operation. Each generating operation  has a type
has a type  , where
, where  (the set of words on alphabet
(the set of words on alphabet  ) is called the arity, and
) is called the arity, and  the co-arity of
the co-arity of  . Pictorially, an operation
. Pictorially, an operation  with arity
with arity  and co-arity
and co-arity  will be represented as
will be represented as
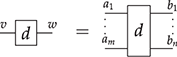
or simply  when we do not need to name the list of generating objects in the arity and co-arity.
when we do not need to name the list of generating objects in the arity and co-arity.
Example 2.1. We may form a signature  where
where  and
and  We may think of string diagrams on
We may think of string diagrams on  as operations of a simple stack machine which can perform simple arithmetic on integers.
as operations of a simple stack machine which can perform simple arithmetic on integers.
Terms
Terms are generated by combining the generators of the signature in a certain way. Once again, let us look first at how terms would be specified in traditional algebra. One would start with a set  of variables and a signature
of variables and a signature  of operations, and define terms inductively as follows:
of operations, and define terms inductively as follows:
For each
 , is a term.
, is a term.For each
, say of arity , if are terms, then is a term.






For string diagrammatic syntax, terms are generated in a similar fashion, with two important differences: (i) it is a variable-free approach, and (ii) the way operations in  are combined in the inductive step depends on the richness of the graphical structure we want to express.
are combined in the inductive step depends on the richness of the graphical structure we want to express.
A standard choice for string diagrams is to rely on symmetric monoidal structure. This means that the generating operations in  will be augmented with some ‘built-in’ operations (‘identity’, ‘symmetry’, and ‘null’), and combined via two forms of composition (‘sequential’ and ‘parallel’). As a preliminary intuition, we may think of the built-in operations as the minimal structure needed to express graphical manipulations of terms, such as ‘stretching’ a wire or crossing two wires. Fixing a signature
will be augmented with some ‘built-in’ operations (‘identity’, ‘symmetry’, and ‘null’), and combined via two forms of composition (‘sequential’ and ‘parallel’). As a preliminary intuition, we may think of the built-in operations as the minimal structure needed to express graphical manipulations of terms, such as ‘stretching’ a wire or crossing two wires. Fixing a signature  , the
, the  -terms are generated by a few simple derivation rules or term formation rules: these are written in the form
-terms are generated by a few simple derivation rules or term formation rules: these are written in the form
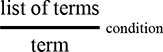
Here, we may regard the list of terms above the line as hypotheses needed to form the term in conclusion of the rule, below the line, provided that the side-condition is satisfied. For symmetric monoidal diagrams, the rules are as follows.
1. First, we have that every generating operation in
yields a term:
2. Next, each built-in operation (from left to right below: identity, symmetry, and null) also yields a term:
3. For the inductive step, a new term may be built by combining two terms, either sequentially (left) or in parallel (right). Note that, for sequential composition, the output of the leftmost term needs to match the input of the rightmost term. For parallel composition, there is no such requirement, and the resulting term has input (output) the concatenation of the words forming the inputs (outputs) of the starting terms.




Using the composition rules, we can define by induction ‘identities’ and ‘symmetries’ for arbitrary words  in
in  .
.

Varying the set of built-in terms (second clause) and the ways of combining terms (last two clauses) will capture structures different from symmetric monoidal, as illustrated in Section 4.
Another important point: notice that null, the identity over the empty word  is not depicted (or is depicted as the empty diagram), which is shown in the preceding as an empty dotted box. Furthermore, since the type of terms is a pair of words over some generating alphabet, they can have the empty word
is not depicted (or is depicted as the empty diagram), which is shown in the preceding as an empty dotted box. Furthermore, since the type of terms is a pair of words over some generating alphabet, they can have the empty word  as arity or co-arity. A term of type
as arity or co-arity. A term of type  , sometimes called a state, has an empty left boundary,
, sometimes called a state, has an empty left boundary,
while a term of type  , sometimes called an effect, has an empty right boundary,
, sometimes called an effect, has an empty right boundary,
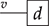
Consequently, a term of type  , which is sometimes called a scalar, or a closed term, by analogy with the corresponding algebraic notion of terms containing no free variables, has no boundary at all; it is thus depicted as just a box, with no wires:
, which is sometimes called a scalar, or a closed term, by analogy with the corresponding algebraic notion of terms containing no free variables, has no boundary at all; it is thus depicted as just a box, with no wires:
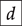
The names ‘state’, ‘effect’, and ‘scalar’ originate from the role played by string diagrams of this type in quantum theory [Reference Coecke and Kissinger35].
From Terms to String Diagrams
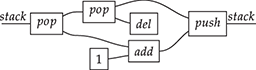
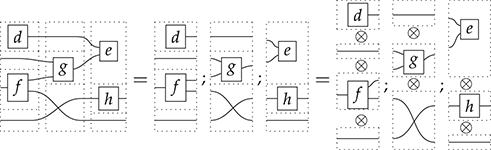
Terms are not quite the same as string diagrams. As soon as we consider more elaborate terms, we realise that the preceding definition requires us to decorate pictures with extra notation to keep track of the order in which we have applied the different forms of composition. For instance, (2.2) is a term from the signature in Example 2.1.
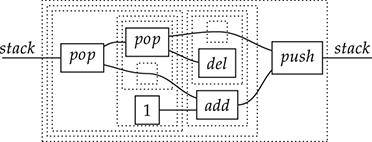
It denotes a very simple protocol, which pops two values of the stack, deletes the second one, and increments the first by one, before pushing it back onto the stack. We have only kept outer object labels for readability. Its full derivation tree is given in Figure 2.1. Notice that a bracketing by dotted frames fully specifies the corresponding derivation tree.
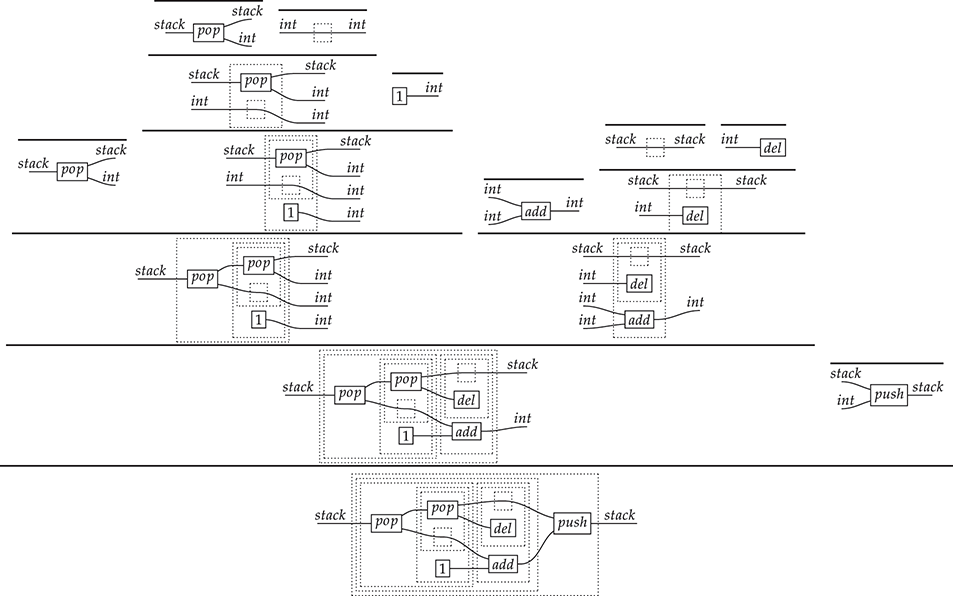
Figure 2.1 An example derivation tree.
This example makes apparent that  -terms come with lots of extra information on how the graphical representation has been put together: the dotted boxes keep track of the order in which sequential and parallel composition have been applied. The move to string diagrams allows us to abstract away this information and focus solely on how the term components are wired together. More formally, a string diagram on
-terms come with lots of extra information on how the graphical representation has been put together: the dotted boxes keep track of the order in which sequential and parallel composition have been applied. The move to string diagrams allows us to abstract away this information and focus solely on how the term components are wired together. More formally, a string diagram on  is defined as an equivalence class of
is defined as an equivalence class of  -terms, where the quotient is taken with respect to the reflexive, symmetric, and transitive closure of the following equations (where object labels are omitted for readability, and
-terms, where the quotient is taken with respect to the reflexive, symmetric, and transitive closure of the following equations (where object labels are omitted for readability, and  ,
,  range over
range over  -terms of the appropriate arity/co-arity):
-terms of the appropriate arity/co-arity):
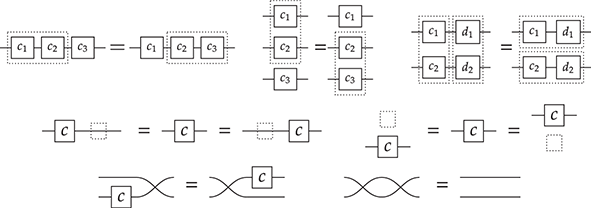
If we think of the dotted frames as two-dimensional brackets, these laws tell us that the specific bracketing of a term does not matter. This is similar to how, in algebra,  for an associative operation, justifying the use of the unbracketed expression
for an associative operation, justifying the use of the unbracketed expression  . In fact, there’s an even better notation: when dealing with a single associative binary operation, we can simply forget it and write any product as a concatenation,
. In fact, there’s an even better notation: when dealing with a single associative binary operation, we can simply forget it and write any product as a concatenation,  ! This is a simple instance of the same key insight that allows us to draw string diagrams. It is helpful to think of these diagrammatic rules as a higher-dimensional version of associativity.Footnote 1 The rightmost identity of the first line in (2.3) is the interchange law, which concerns the interplay between the two forms of composition: we can take the parallel composition of two sequentially composed terms, or vice versa, and the resulting string diagram will be the same. The remaining axioms of the first two lines encode the associativity and unitality of the two forms of composition. The last line contains two axioms involving wire crossings
! This is a simple instance of the same key insight that allows us to draw string diagrams. It is helpful to think of these diagrammatic rules as a higher-dimensional version of associativity.Footnote 1 The rightmost identity of the first line in (2.3) is the interchange law, which concerns the interplay between the two forms of composition: we can take the parallel composition of two sequentially composed terms, or vice versa, and the resulting string diagram will be the same. The remaining axioms of the first two lines encode the associativity and unitality of the two forms of composition. The last line contains two axioms involving wire crossings 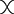 : the first, called the naturality of , tells us that boxes can be pulled across wires; the second, that the wire crossing is self-inverse. As a result, wires can be entangled or disentangled as long as we do not modify how the boxes are connected. We call these axioms the laws of symmetric monoidal categories (SMC).
: the first, called the naturality of , tells us that boxes can be pulled across wires; the second, that the wire crossing is self-inverse. As a result, wires can be entangled or disentangled as long as we do not modify how the boxes are connected. We call these axioms the laws of symmetric monoidal categories (SMC).
Thanks to the laws of SMC, we can safely remove the brackets from the term in (2.2) to obtain the corresponding string diagram:
This representation is now unambiguous because the axioms in (2.3) imply that any way of placing dotted frames around components of (2.4) leads to equivalent  -terms. For instance, the following two bracketed terms are equivalent as string diagrams:
-terms. For instance, the following two bracketed terms are equivalent as string diagrams:

There is an important subtlety: if, formally, a string diagram is an equivalence class of terms quotiented by the laws of (2.3), there is not a unique way to depict a string diagram. In other words, the graphical representation (even without dotted frames) sits in between terms and string diagrams, as it does not distinguish certain equivalent terms. In some cases the depiction absorbs the laws of SMC, for example, for the two sides of the interchange law:
In other cases, the way we draw them distinguishes string diagrams that are equivalent under the laws of (2.3). Consider, for example,
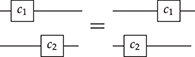
This equality can be seen as an instance of the interchange law (2.5) with identity wires or as a consequence of the unitality of identity wires, which allows us to stretch wires as much as we like.
A related point is that string diagrams do not distinguish different ways of braiding wires, even if our drawings do:
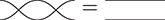
The laws of (2.3) guarantee that any two string diagrams made entirely of wire crossings over the same number of wires are equal when they define the same permutation of the wires. If the other rules are two-dimensional versions of associativity, the wire-crossing axioms are two-dimensional generalisations of commutativity. In ordinary algebra, when we have a commutative and associative binary operation, we can write products using any ordering of its elements:  . For string diagrams, the vertical juxtaposition of boxes is not strictly commutative; nevertheless, we are allowed to move boxes across wires, which is the next best thing:
. For string diagrams, the vertical juxtaposition of boxes is not strictly commutative; nevertheless, we are allowed to move boxes across wires, which is the next best thing:
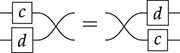
(We invite the reader to show this as their first exercise in diagrammatic reasoning.) Furthermore, we need to keep track of how boxes are wired, but only the specific permutation of the wires matters, not how we have constructed it. Coming back to our stack-machine example, the following are equivalent string diagrams:
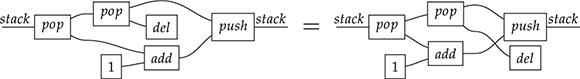
While this situation may appear slightly confusing at first, these examples show that in practice the distinction between string diagrams (as equivalence classes) and how we depict them is harmless. The topological moves that are captured by the equations of (2.3) are designed to be intuitive. They are often summarised by the following slogan: only the connectivity matters. The rule of thumb is that any deformation that preserves the connectivity between the boxes and does not require us to bend the wires backwards will give two equivalent string diagrams.
Finally, keep in mind that the connection points from which we attach wires to boxes are ordered, so that the following two string diagrams are not equivalent:
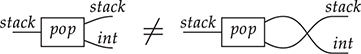
Definition 2.2 (String diagrams over Σ). String diagrams over  are
are  -terms quotiented by the equations in (2.3).
-terms quotiented by the equations in (2.3).
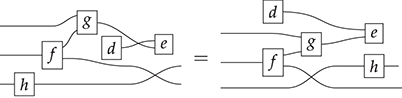
Example 2.3. Following the preceding discussion, the reader should convince themselves that the following two (unframed) terms depict the same string diagram:
(Free) Symmetric Monoidal Categories
In algebra, the collection of terms obtained from a signature, without any additional operations or equations, is often called the free structure over that signature. The diagrammatic language of string diagrams comes with an associated notion of free structure: the free symmetric monoidal category (SMC) over a given signature.Footnote 2
At this point, the more mathematically inclined reader might object that we still have not defined rigorously what an SMC is. Somewhat circularly, we could say that an SMC is a structure in which we can interpret string diagrams! Less tautologically, it is a category with an additional operation – the monoidal product – on objects and morphisms that satisfies the laws shown in (2.3). To state them without string diagrams, we need to introduce explicit notation for composition and the monoidal product. We do so in the following definition. Note that we assume basic knowledge of what a category is. The definition, along with related notions, can be found in the Appendix.
Definition 2.4. A (strict) symmetric monoidal category  is a category
is a category  equipped with a distinguished object
equipped with a distinguished object  , a binary operation
, a binary operation  on objects, an operation of type
on objects, an operation of type  on morphisms which we also write as
on morphisms which we also write as  , such that
, such that  and
and
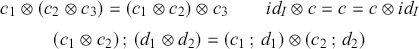
and a family of morphisms  for any two objects
for any two objects  , such that
, such that
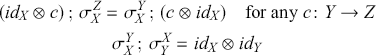
Observe that these are exactly the laws shown in (2.3) in symbolic form: we can simply replace ‘  ’ by vertical composition and ‘ ; ’ by horizontal composition.
’ by vertical composition and ‘ ; ’ by horizontal composition.
It is possible to translate any string diagrams into symbolic notation. For instance, the diagram of Example 2.3 can be written as  . This expression can be obtained by successively decomposing the diagrams into horizontal and vertical layers as follows:
. This expression can be obtained by successively decomposing the diagrams into horizontal and vertical layers as follows:
As for string diagrams, there are multiple ways to write a given morphism in symbolic notation. In fact, because string diagrams absorb some of the laws of SMCs into the notation, there are usually more ways of writing a given morphism in symbolic notation than there are diagrammatic representations for it.
Remark 2.5 (On strictness). The last definition is not the one that the reader is likely to encounter in the literature when looking up the term ‘symmetric monoidal category’. It defines what is called a strict monoidal category; the usual notion is more general and allows for the equalities to be replaced by isomorphisms. We will not give a rigorous definition of this more general notion and refer the reader to any standard textbook on category theory for a general introduction to SMCs [Reference Mac Lane89: chapter XI]. Our approach is nevertheless theoretically motivated by the following fundamental result: every SMC is equivalent (in a sense that we will not cover here in detail, but do recall in the Appendix, at Definition A.7) to a strict SMC. This fact is what allows us to draw string diagrams. It is known as the coherence theorem for SMCs. Put differently, the coherence theorem allows us to forget explicit symbols for ‘  ’ and ‘
’ and ‘  ’, replacing them by vertical juxtaposition and horizontal composition without any brackets to denote the order of application.Footnote 3 Once again, the reader is invited to think about this as a two-dimensional generalisation of well-known facts about monoids: just like we can we can simply concatenate elements of a monoid and omit the symbol for the multiplication and the parentheses to bracket its application, we can use string diagrams to represent morphisms of a SMC. It is then natural that more composition operations require more dimensions to represent. In fact, some of the earliest appearances of string diagramsFootnote 4 occurred to construct free SMCs with additional structure and prove a coherence theorem for them [Reference Maxwell Kelly, Kelly, Laplaza, Lewis and Lane79; Reference Maxwell Kelly and Laplaza80].
’, replacing them by vertical juxtaposition and horizontal composition without any brackets to denote the order of application.Footnote 3 Once again, the reader is invited to think about this as a two-dimensional generalisation of well-known facts about monoids: just like we can we can simply concatenate elements of a monoid and omit the symbol for the multiplication and the parentheses to bracket its application, we can use string diagrams to represent morphisms of a SMC. It is then natural that more composition operations require more dimensions to represent. In fact, some of the earliest appearances of string diagramsFootnote 4 occurred to construct free SMCs with additional structure and prove a coherence theorem for them [Reference Maxwell Kelly, Kelly, Laplaza, Lewis and Lane79; Reference Maxwell Kelly and Laplaza80].
Definition 2.6 (Free SMC on a signature Σ). The symmetric monoidal category  is formed by letting objects be elements of
is formed by letting objects be elements of  and morphisms be string diagrams over
and morphisms be string diagrams over  , that is,
, that is,  -terms quotiented by (2.3). The monoidal product is defined as word concatenation on objects. Composition and product of string diagrams are defined respectively by sequential and parallel composition of (some arbitrary representative of each equivalence class of)
-terms quotiented by (2.3). The monoidal product is defined as word concatenation on objects. Composition and product of string diagrams are defined respectively by sequential and parallel composition of (some arbitrary representative of each equivalence class of)  -terms.
-terms.
Example 2.7 (Free SMC over a single object). The free SMC over the signature  is easy to describe explicitly. Its string diagrams are generated by horizontal and vertical compositions of
is easy to describe explicitly. Its string diagrams are generated by horizontal and vertical compositions of
(where we omit labels for the single generating object  ), modulo the laws of SMCs. Here are a few examples:
), modulo the laws of SMCs. Here are a few examples:
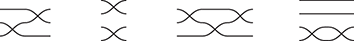
In other words, they are permutations of the wires! If we write  for the concatenation of
for the concatenation of  bullets, a string diagram
bullets, a string diagram  is a permutation of
is a permutation of  elements, and there are no diagrams
elements, and there are no diagrams  for
for  .
.
Free SMCs on a single generating object (and arbitrary generating operations) are usually called PROPs (Product and Permutation categories) [Reference Mac Lane88]. The PROP of permutations, which we just described, is the ‘simplest’ possible PROP. More formally, it is the initial object in the category of PROPs. Sometimes, the notion of a ‘coloured’ PROP is encountered: this is nothing but a (strict) SMC whose set of objects is freely generated from any set of generating objects, instead of just a single generating object as in the case of plain PROPs.
When we encounter PROPs, we will use natural numbers as objects, since all objects are of the form  , and write the type of a string diagram
, and write the type of a string diagram  simply as
simply as  .
.
Symmetric Monoidal Functors
Whenever we define a new mathematical structure, it is good practice to introduce a corresponding notion of mapping between them. For SMCs, this is the notion of a symmetric monoidal functor. We will need it when giving string diagrams a semantic interpretation in Section 5.
Definition 2.8. Let  and
and  be two SMCs. A (strict) symmetric monoidal functor
be two SMCs. A (strict) symmetric monoidal functor  is a mapping from objects of
is a mapping from objects of  to those of
to those of  that satisfies
that satisfies
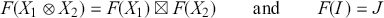
and a mapping from morphisms of  to those of
to those of  that satisfies
that satisfies
In this introduction, for pedagogical reasons, we will mostly use strict monoidal functors, that is, functors that preserve the monoidal structure on the nose. The reader should know that it is possible, and sometimes necessary, to relax this requirement, replacing the equalities  and
and  by isomorphisms (which then have to satisfy certain compatibility conditions). See [Reference Mac Lane89] for a standard treatment and [Reference Selinger106] for the connections with string diagrams.
by isomorphisms (which then have to satisfy certain compatibility conditions). See [Reference Mac Lane89] for a standard treatment and [Reference Selinger106] for the connections with string diagrams.
If we have two such functors  and
and  that are inverses to each other –
that are inverses to each other –  and
and  are identity functors – we say that the two SMCs are isomorphic. We will also use the notion equivalence of SMCs. This is a more relaxed notion than that of isomorphism, where
are identity functors – we say that the two SMCs are isomorphic. We will also use the notion equivalence of SMCs. This is a more relaxed notion than that of isomorphism, where  and
and  are merely isomorphic to identity functors. It is more appropriate in some cases, in particular when the categories involved are not strict monoidal (see Remark 2.5, for example). We will not dwell on equivalences of categories much in this Element, but refer the reader to Definition A.7 and Remark A.8 in the Appendix.
are merely isomorphic to identity functors. It is more appropriate in some cases, in particular when the categories involved are not strict monoidal (see Remark 2.5, for example). We will not dwell on equivalences of categories much in this Element, but refer the reader to Definition A.7 and Remark A.8 in the Appendix.
Remark 2.9 (On functors from free SMCs). When defining a functor  out of a free SMC
out of a free SMC  , there is a clear recipe to follow: we only need to specify to which object we want to map elements of
, there is a clear recipe to follow: we only need to specify to which object we want to map elements of  , and to which morphism
, and to which morphism  we want to map each element of
we want to map each element of  of
of  . This is because of the universal property of free constructions: if we have a mapping from the set of generating operations of some signature
. This is because of the universal property of free constructions: if we have a mapping from the set of generating operations of some signature  to morphisms of some SMC
to morphisms of some SMC  , there is a unique way of extending this mapping to a symmetric monoidal functor
, there is a unique way of extending this mapping to a symmetric monoidal functor  . This observation will come in handy when defining the semantics of string diagrammatic theories, in Section 5.
. This observation will come in handy when defining the semantics of string diagrammatic theories, in Section 5.
Example 2.10. In Example 2.7, we saw that the morphisms/string diagrams of the free SMC over a single object looked a lot like permutations. There is a way of making this precise, by establishing an isomorphism between this SMC and another whose morphisms are permutations of finite sets. Let  be the category whose objects are natural numbers, and morphisms
be the category whose objects are natural numbers, and morphisms  are permutations of
are permutations of  . We can equip it with a monoidal product, given by addition on objects, and on morphisms
. We can equip it with a monoidal product, given by addition on objects, and on morphisms  and
and  by
by  if
if  and
and  otherwise. The unit of the monoidal structure is the number
otherwise. The unit of the monoidal structure is the number  and the symmetry is the permutation over two elements, which we write as
and the symmetry is the permutation over two elements, which we write as  , given by
, given by  and
and  . The isomorphism is straightforward. In one direction, let
. The isomorphism is straightforward. In one direction, let  be given by
be given by  on objects and
on objects and  . This is enough to describe
. This is enough to describe  fully because all string diagrams of
fully because all string diagrams of  are vertical or horizontal composites of and
are vertical or horizontal composites of and  has to preserve these two forms of composition, by Definition 2.8. Furthermore, the required properties are immediately satisfied. To build its inverse, we need to know that we can factor any permutation into a composition of adjacent transpositions (this fact is fairly intuitive and usually covered in introductory algebra courses, so we will not prove it here). Then, notice that the transposition
has to preserve these two forms of composition, by Definition 2.8. Furthermore, the required properties are immediately satisfied. To build its inverse, we need to know that we can factor any permutation into a composition of adjacent transpositions (this fact is fairly intuitive and usually covered in introductory algebra courses, so we will not prove it here). Then, notice that the transposition  over
over  elements should clearly be mapped to the string diagram that is the identity everywhere and at the
elements should clearly be mapped to the string diagram that is the identity everywhere and at the  -th and
-th and  -th wires. Call this diagram
-th wires. Call this diagram  . Then, let
. Then, let  be given by
be given by  on objects and on morphisms by
on objects and on morphisms by  where
where  is a decomposition of
is a decomposition of  into adjacent transpositions. One can check that this is well-defined and satisfies all the equations of Definition 2.8. Moreover the two are inverses of each other. For example, to see that
into adjacent transpositions. One can check that this is well-defined and satisfies all the equations of Definition 2.8. Moreover the two are inverses of each other. For example, to see that  it is sufficient to check that equality for . It holds clearly as
it is sufficient to check that equality for . It holds clearly as  . The other direction is a bit more lengthy, but without any major difficulties.
. The other direction is a bit more lengthy, but without any major difficulties.
Thus  gives a semantic account of the free SMC over a single object. Conversely, the latter can be seen as diagrammatic syntax for the former.
gives a semantic account of the free SMC over a single object. Conversely, the latter can be seen as diagrammatic syntax for the former.
In fact, this SMC is also equivalent to the non-strict SMC of finite sets and bijections between them, with the disjoint sum as monoidal product. The equivalence is also straightforward to establish, but requires us to fix a total ordering on every finite set.
This example is just a taster of an idea that we will develop further in Section 5, dedicated to the semantics – that is, the interpretation – of string diagrams.
2.1 Adding Equations
The equations shown in (2.3) only capture a very basic notion of equivalence between string diagrams. When describing computational processes for example, it is useful to include more equations, specific to the domain of interest. In string diagram theory, these additional equations are encapsulated in the notion of symmetric monoidal theory. More formally, a symmetric monoidal theory – or simply theory when no ambiguity can arise – is a pair  , where
, where  is a signature and
is a signature and  is a set of equalities
is a set of equalities  between string diagrams of the same type over
between string diagrams of the same type over  . We write
. We write  for the smallest congruence relation (w.r.t. sequential and parallel composition) containing
for the smallest congruence relation (w.r.t. sequential and parallel composition) containing  . We will see many examples of symmetric monoidal theories in Section 2.2.
. We will see many examples of symmetric monoidal theories in Section 2.2.
Remark 2.11 (Equations and diagrammatic rewriting). It might be helpful to see equations as two-way rewriting rules that can be applied in an arbitrary context. More precisely, assume that we have some equation of the form  , where
, where  have the same type; to apply it in context, we need to identify
have the same type; to apply it in context, we need to identify  in a larger string diagram
in a larger string diagram  , that is, find
, that is, find  and
and  such that
such that

and simply replace  by
by  , forming the new diagram
, forming the new diagram
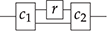
. This is just the diagrammatic version of standard algebraic reasoning. We can summarise this process as follows:
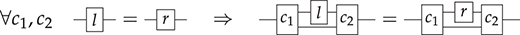
For example,

where the context is
We will come back to this point, in the context of graph-rewriting, in Section 6.1.
In the same way that string diagrams corresponded to a free structure, the free symmetric monoidal category (SMC) over  , quotienting by further equations also determines a free structure: given a signature
, quotienting by further equations also determines a free structure: given a signature  and a theory
and a theory  , we can form the free SMC
, we can form the free SMC  obtained by quotienting the free SMC
obtained by quotienting the free SMC  by the equivalence relation over string diagrams given by
by the equivalence relation over string diagrams given by  .
.
Definition 2.12 (Free SMC over a theory (Σ,E)). The symmetric monoidal category  is formed by letting objects be elements of
is formed by letting objects be elements of  and morphisms be equivalence classes of string diagrams over
and morphisms be equivalence classes of string diagrams over  quotiented by
quotiented by  . The monoidal product is defined as word concatenation on objects; composition and product of morphisms are defined respectively by sequential and parallel composition of arbitrary representatives of each equivalence class.
. The monoidal product is defined as word concatenation on objects; composition and product of morphisms are defined respectively by sequential and parallel composition of arbitrary representatives of each equivalence class.
2.2 Common Equational Theories
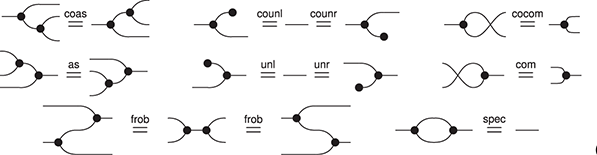
Some theories occur frequently in the literature. Many authors assume familiarity with the axioms hiding behind the words ‘monoids’, ‘comonoids’, ‘bimonoids/bialgebras’, or ‘Frobenius monoid/algebra’, and how all of these theories relate to one another. For this reason it is valuable to know them well, especially when trying to distinguish routine moves from key steps in diagrammatic proofs. This section describes a few of the most commonly found examples.
Example 2.13 (Monoids). Let us begin with the deceptively easy example of monoids. Many readers will undoubtedly be familiar with the algebraic theory of monoids, which can be presented by two generating operations, say  of arity
of arity  and
and  of arity
of arity  (in other words, a constant) satisfying the following three axioms:
(in other words, a constant) satisfying the following three axioms:

Analogously, the symmetric monoidal theory of monoids can be presented by a signature
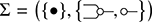
, based on a single object-type  , a multiplication
, a multiplication
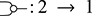
, and a unit
, and three axioms, for associativity and (two-sided) unitality:

Observe that we have just replaced variables with wires and algebraic operations with diagrammatic generators. As in ordinary algebra, two terms/diagrams are equal if one can be obtained from the other by applying some sequence of these three equations (recall Remark 2.11).
We can also present commutative monoids in the same way. Recall that commutative monoids are those that satisfy  ; diagrammatically, we can present the corresponding symmetric monoidal theory with the same signature and a single additional equality (note the use of the symmetry
; diagrammatically, we can present the corresponding symmetric monoidal theory with the same signature and a single additional equality (note the use of the symmetry
):
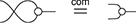
Of course, in the presence of commutativity, each of the unitality laws are derivable from the other. In the usual algebraic theory of monoids we would show this as follows: if  , then
, then  where the last step is right-unitality. The corresponding diagrammatic proof is very similar, with one additional step:
where the last step is right-unitality. The corresponding diagrammatic proof is very similar, with one additional step:
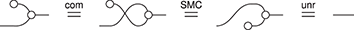
The second equality is a simple instance of the bottom left axiom of (2.3), for a string diagram with no wires on the left (that is, of type  for some
for some  ).
).
This makes an important point: two theories  and
and  might present the same structure, in the sense that the corresponding free SMCs
might present the same structure, in the sense that the corresponding free SMCs  and
and  might be isomorphic. It is also a good place to mention that theories do not have to be minimal in any way; they can contain axioms that are derivable from the others. There are various reasons one might prefer a theory that contains redundant axioms: to highlight some of the symmetries, to avoid having to re-derive some equalities as a lemma later on, and others.
might be isomorphic. It is also a good place to mention that theories do not have to be minimal in any way; they can contain axioms that are derivable from the others. There are various reasons one might prefer a theory that contains redundant axioms: to highlight some of the symmetries, to avoid having to re-derive some equalities as a lemma later on, and others.
When dealing with monoids, there are several straightforward syntactic simplifications that the reader is likely to encounter in the literature. First, a simple observation: in standard algebraic syntax, the associativity axiom  implies that any two ways of applying monoid multiplication to the same list of elements are all equal. Therefore it is unambiguous to introduce a generalised monoid operation for any finite arity, for example
implies that any two ways of applying monoid multiplication to the same list of elements are all equal. Therefore it is unambiguous to introduce a generalised monoid operation for any finite arity, for example  , to denote all possible ways of applying
, to denote all possible ways of applying  to these three elements, and avoid a flurry of parentheses. (Note that, with this syntactic sugar, the unit
to these three elements, and avoid a flurry of parentheses. (Note that, with this syntactic sugar, the unit  denotes the application of
denotes the application of  to zero elements.) The same trick works for an associative
to zero elements.) The same trick works for an associative
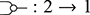
: we can define a generalised  -ary operation as a dot with
-ary operation as a dot with  -many wires
-many wires
as syntactic sugar to denote multiple applications of

. For this reason, the reader might also encounter diagrammatic proofs that identify different ways of applying a monoid operation to the same list of elements, much like a practitioner well-versed in ordinary algebra will usually omit parentheses where they can do so unambiguously.
Example 2.14 (Comonoids). Unlike algebraic syntax, string diagrams allow for operations with co-arity different from  , manifested by multiple (or no) right boundary wires. It is therefore possible to flip the generators and axioms of the theory of monoids to obtain the symmetric monoidal theory of comonoids! Unsurprisingly, it is represented by a signature with a single object (which we therefore omit in diagrams), two generators, called comultiplication and counit,
, manifested by multiple (or no) right boundary wires. It is therefore possible to flip the generators and axioms of the theory of monoids to obtain the symmetric monoidal theory of comonoids! Unsurprisingly, it is represented by a signature with a single object (which we therefore omit in diagrams), two generators, called comultiplication and counit,

and the following three axioms:

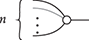
called coassociativity and counitality. As one can see immediately, string diagrams for comonoids are just the mirrored version of those for monoids. Therefore, any diagrammatic statement involving only comonoids can be proved by simply flipping the corresponding proof about monoids along the vertical axis. For example, as we did for monoids, it is possible to reason silently modulo coassociativity and introduce syntactic sugar for a generalised comultiplication node with co-arity  for any natural number:
for any natural number:
A comonoid is furthemore cocommutative if
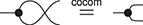
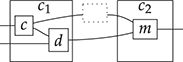
As we will see, distinguished cocommutative comonoid structures play a special role in many theories: for example, they can be used to represent a form of copying and discarding, which allows us to interpret the wires of our diagrams as variables in standard algebraic syntax. The comultiplication allows us to reference a variable multiple times and the counit gives us the right to omit some variable in a string diagram. Following this intuition, we may, for instance, depict the term  in the context given by variables
in the context given by variables  , as follows:
, as follows:
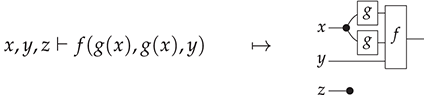
For this reason, from the diagrammatic perspective, algebraic theories (or Lawvere theories, their categorical cousins, see [Reference Hyland, Power, Cardelli, Fiore and Winskel74]) always carry a chosen cocommutative comonoid structure [Reference Bonchi, Sobociński and Zanasi23], even though this structure does not appear in the usual symbolic notation for variables (which relies instead on an infinite supply of unique names to serve as identifiers for variables). We will come back to this point in Remark 5.2.
Remark 2.15 (Symmetric monoidal theories and linearity). Much like monoids in ordinary algebra, monoids or comonoids in symmetric monoidal theories can have additional properties. We have already encountered commutative monoids and cocommutative comonoids. However, the analogy between symmetric monoidal theories and algebraic theories hides an important subtlety: if, in the former, the wires play the role of variables, they have to be used precisely once. Unlike variables in ordinary algebra, we cannot use wires more than once or omit to use them at all! This restriction – termed resource-sensitivity – is an important feature of diagrammatic syntax. Properties that do not involve multiple uses of variables can be specified completely analogously, as we saw for commutativity. Axioms that use each variable precisely once on each side of the equality sign are called linear axioms. Non-linear axioms cannot be translated directly in the diagrammatic context, however. For example, it makes no sense to refer to the symmetric monoidal theory of idempotent monoids: those monoids that satisfy  . Indeed, to even state the idempotency axiom one requires the ability to duplicate wires. As we will see, idempotency can also be expressed diagrammatically, but as a property of a more complex algebraic structure than a monoid; it can be stated as a property of a bimonoid, which is our next example. This example is an instance of a more general pattern that allows us recover the resource-insensitivity of ordinary algebraic syntax. We will explore this correspondence more systematically in Section 4.2.5.
. Indeed, to even state the idempotency axiom one requires the ability to duplicate wires. As we will see, idempotency can also be expressed diagrammatically, but as a property of a more complex algebraic structure than a monoid; it can be stated as a property of a bimonoid, which is our next example. This example is an instance of a more general pattern that allows us recover the resource-insensitivity of ordinary algebraic syntax. We will explore this correspondence more systematically in Section 4.2.5.
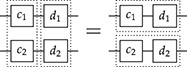
The respective theories of monoids and comonoids can interact in different ways, as the next two examples illustrate. By ‘interact’ in this context, we mean that there are different equations that one can impose when considering a signature that contains both the generators of monoids and those of comonoids with their respective theories.
Example 2.16 (Co/commutative bimonoids). One possible theory axiomatises a structure called a bimonoid. It is presented by the generators of monoids and comonoids

together with their respective axioms, and the following additional four equations:
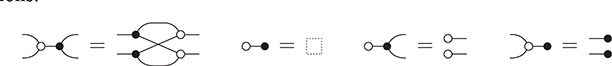
Intuitively, these equalities can be seen as instances of the same general principle: whenever one of the monoid generators is composed horizontally with one of the comonoid generators, they pass through one another, producing multiple copies of each other. This is a two-dimensional form of distributivity. For example, when the unit meets the comultiplication, the latter duplicates the former; when the multiplication meets the comultiplication, they duplicate each other (notice how this requires the symmetry, the ability to cross wires). Using the generalised monoid and comonoid operations introduced in the previous examples, we can formulate a generalised bimonoid axiom scheme that captures all four axioms (and more):
Then, the four defining axioms can be recovered for the particular cases where the number of wires on each side is zero or two.
As we have already mentioned in Example 2.14, comonoids can mimic the multiple use of variables in ordinary algebra. Thus, in the context of bimonoids, we can state ordinary equations that involve more or less than one occurrence of the same variable. For example, a bimonoid is idempotent when it satisfies the following additional equality, which clearly translates the usual  into a diagrammatic axiom:
into a diagrammatic axiom:
Example 2.17 (Frobenius monoids). Bimonoids are not the only way that monoids and comonoids can interact – there is another structure that frequently appears in the literature, under the name of Frobenius monoid, or Frobenius algebra.Footnote 5 This structure is presented by the generators of monoids and comonoids. We will write them using nodes of the same colour, as this is how Frobenius monoids tend to appear in the literature, and this will allow us to distinguish them from bimonoids in the rest of the Element:

together with their respective axioms, and the following additional axiom, called Frobenius’ law:
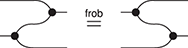
This equality provides an alternative way for the multiplication and comultiplication of the monoid and comonoid structures to interact: unlike the case of bimonoids, this time they do not duplicate each other, but simply slide past one another, on either side. This is a fundamental difference which, in fact, turns out to be incompatible with the bimonoid axioms. We will examine this incompatibility more closely in Section 4.2.10.
The reader might encounter other versions of this axiom in the literature, such as:
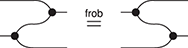
In the presence of the other axioms (namely counitality and coassociativity), these two equalities are derivable from (2.7). To get a feel for diagrammatic reasoning, let us prove it:
At first, the string diagram novice may find it difficult to internalise all the laws that make up a theory such as that of Frobenius monoids. When proving some equality, it is not always clear which axiom to apply at which point to reach the desired goal and it is easy to get overwhelmed by all the choices available. However, in some nice cases, as we saw for (co)monoids, there are high-level principles that allow us to simplify reasoning and see more clearly the key steps ahead. For example, reasoning up to associativity becomes second nature after enough practice and one no longer sees two different composites of (co)multiplication as different objects.
In the same way, the Frobenius law can be thought of as a form of two-dimensional associativity; it simplifies reasoning about complex composites of monoid and comonoid operations even further and allows us to identify at a glance when any two string diagrams for this theory are equal. To explain this, it is helpful to think of string diagrams for the theory of Frobenius monoids as (undirected) graphs, whose vertices are any of the black dots, and edges are wires. We say that a string diagram is connected if there is a path between any two vertices in the corresponding graph. It turns out that, for Frobenius monoids, any connected string diagram composed out of (finitely many)

,

,

, or

using vertical or horizontal composition (without wire crossings) is equal to one of the following form [Reference Heunen and Vicary73: section 5.2.1]:
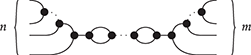
where we use an ellipsis to represent an arbitrarily large composite following the same pattern. In other words, the only relevant structure for a connected string diagram in the theory of Frobenius monoids is the number of left and right wires it has, and how many paths there are from any left leg to any right leg (how many loops it has in the normal form just depicted). This observation is sometimes called the spider theorem and justifies introducing generalised vertices we call spiders as syntactic sugar:
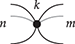
where the natural number  represents the number of inner loops in the normal form just depicted. All the laws of Frobenius monoids can now be summarised into a single convenient axiom scheme:
represents the number of inner loops in the normal form just depicted. All the laws of Frobenius monoids can now be summarised into a single convenient axiom scheme:
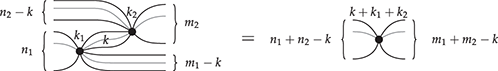
where  is the number of middle wires that connect the two spiders on the left-hand side of the equality. As a result, we need only keep track of the number of open wires and loops for any complicated string diagram; this greatly reduces the mental load of reasoning about this theory.
is the number of middle wires that connect the two spiders on the left-hand side of the equality. As a result, we need only keep track of the number of open wires and loops for any complicated string diagram; this greatly reduces the mental load of reasoning about this theory.
Frobenius monoids that satisfy the following idempotency axiom occur frequently in the literature:

In this case, the Frobenius monoid is called special (or sometimes, separable). The normal form given by the spider theorem simplifies even further in this case, since we can now forget about the inner loops:

The only relevant structure of any connected string diagram in the theory of special Frobenius monoids is the number of its left and right wires. We can thus introduce the same syntactic sugar, omitting the number of loops above the spider. The spider fusion scheme also simplifies further, as we no longer need to keep track of the number of legs that connect the two fusing spiders.
Example 2.18 (Special and commutative Frobenius monoids). The commutative and special Frobenius monoids are very common in the literature, as they are an algebraic structure one finds naturally when reasoning about relations (as we will see when we study the semantics of string diagrams in Section 5). We summarise here the full equational theory for future reference:
In what follows, we will refer to this theory as  .
.
When adding commutativity in the picture, the spider theorem still holds and includes string diagrams composed out of (finitely many) , , , and wire crossings, using vertical or horizontal composition. Any string diagram in the free SMC over the theory of commutative and special Frobenius monoids is fully determined by a list of spiders, and to where each of their respective legs are connected on the left and on the right boundary. In other words, string diagrams with  left wires and
left wires and  right wires are in one-to-one correspondence with maps
right wires are in one-to-one correspondence with maps  for some
for some  . This result will be the basis of a concrete description of the free SMC on the theory of a special commutative Frobenius monoid in Example 5.11.
. This result will be the basis of a concrete description of the free SMC on the theory of a special commutative Frobenius monoid in Example 5.11.
Example 2.19. A special Frobenius monoid that moreover satisfies the following axiom is sometimes called extra-special:
This means that we can forget about networks of black nodes without any dangling wires – they can always be eliminated. In this case, string diagrams with  left wires and
left wires and  right wires in the (free SMC over the) theory of a commutative extra-special Frobenius monoid are in one-to-one correspondence with partitions of
right wires in the (free SMC over the) theory of a commutative extra-special Frobenius monoid are in one-to-one correspondence with partitions of  . Intriguingly, one may think of (2.9) as a ‘garbage collector’; in the relational interpretation of string diagrams, it allows us to capture equivalence relations, as it eliminates empty equivalence classes. We will come back to the case of extra-special commutative Frobenius monoids in Example 5.12.
. Intriguingly, one may think of (2.9) as a ‘garbage collector’; in the relational interpretation of string diagrams, it allows us to capture equivalence relations, as it eliminates empty equivalence classes. We will come back to the case of extra-special commutative Frobenius monoids in Example 5.12.
The reader will frequently encounter the theories we covered here as the building blocks of more complex diagrammatic calculi, designed to capture different kinds of phenomena. For example, the ZX-calculus, a theory that generalises quantum circuits (see Section 7), contains not one, but two special commutative Frobenius monoids, often denoted by a red and a green dot respectively. They interact together to form two bimonoids: the green monoid with the red comonoid forms a bimonoid, and so does the red monoid with the green comonoid. At first, this seems like a lot of structure to absorb, but quickly, one learns to use the spider theorem to think of monochromatic string diagrams, so that most of the complexity comes from the interaction of the two colours. And even then, the generalised bimonoid law we saw in Example 2.16 helps a lot. In fact, modern presentations of the ZX-calculus prefer to give the theory using spiders of arbitrary arity and co-arity as operations and the spider fusion rules as axioms. Strikingly, very similar equational theories can be found ubiquitously in a number of different applications, across different fields of science: it appears there is something fundamental to the interaction of monoid–comonoid pairs in the way we model computational phenomena. We will see several example applications in Section 7.
Remark 2.20 (Distributive Laws). It is noteworthy that both the equations of bimonoids (Example 2.16) and of Frobenius monoids (Example 2.17) describe the interaction of a monoid and a comonoid, even though they do it in different ways. A way to put it is in terms of factorisations: the bimonoid laws allow us to factorise any string diagram as one where all the comonoid generators precede the monoid generators, as in (2.6); conversely, the Frobenius laws yield a monoid-followed-by-comonoid factorisation, as in the spider theorem. More abstractly, the two equational theories can be described as different specifications of a distributive law involving the monoid and the comonoid. Distributive laws are a familiar concept in algebra: the chief example is the one of a ring, whose equations describe the distributivity of a monoid over an abelian group. In the context of symmetric monoidal theories, distributive laws are even more powerful, as they can be used to study the interaction of theories with generators with arbitrary co-arity, such as comonoids, Frobenius monoids, and so on. The systematic study of distributive laws of symmetric monoidal theories has been initiated by Lack [Reference Lack84] and expanded in more recent works [Reference Bonchi, Sobocinski and Zanasi22, Reference Bonchi, Sobociński and Zanasi23, Reference Zanasi116]. Understanding a theory as the result of a distributive law allows us to obtain a factorisation theorem for its string diagrams, such as (2.6) and the spider theorem. Moreover, it provides insights on a more concrete representation (a semantics) for syntactically specified theories of string diagrams – a theme which we will explore in Section 5. For example, the phase-free fragment of the aforementioned ZX-calculus can be understood in terms of a distributive law between two bimonoids. This observation is instrumental in showing that the free model of the phase-free ZX-calculus is a category of linear subspaces [Reference Bonchi, Sobociński, Zanasi and Muscholl19]. We refer to [Reference Zanasi116] for a more systematic introduction to distributive laws of symmetric monoidal theories, as well as other ways of combining together theories of string diagrams.
3 String Diagrams as Graphs
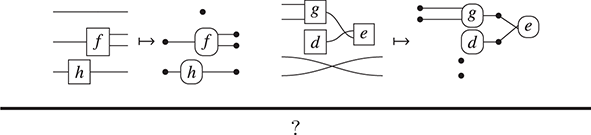
The previous section introduced string diagrams as a syntax. However, a strength of the formalism is that string diagrams may be also treated as graphs, with nodes and edges. This perspective is often convenient to investigate properties of string diagrams having to do with their combinatorial rather than syntactic structure, such as whether there is a path between two components. Another important reason to explore a combinatorial perspective to string diagrams is that their graph representation ‘absorbs’ the laws of symmetric monoidal categories shown in (2.3). It is thus more adapted than the syntactic representation for certain computation tasks, such as rewriting (see Section 6.1). The goal of this section is to illustrate how string diagrams can be formally interpreted as graphs.
As a starting point, let us take, for example, a string diagram we have previously considered:
If we forget about the term structure that underpins this representation, and try to understand it as a graph-like structure, the seemingly most natural approach is to think of boxes as nodes and the wires as edges of a graph. In fact, this is usually the intended interpretation adopted in the early days of string diagrams as a mathematical notation; see, for example, [Reference Joyal and Street77]. An immediate challenge for this approach is that ‘vanilla’ graphs do not suffice: string diagrams present loose, open-ended edges, which only connect to a node on one side, or even on no side, as, for instance, the graph representation of the ‘identity’ wires:  . Historically, a solution to this problem has been to consider as interpretation a more sophisticated notion of graph, endowed with a topology from which one can define when edges are ‘loose’, ‘half-loose’, ‘pinned’, and so on; see [Reference Joyal and Street77]. Another, more recent approach understands string diagrams as graphs with two sorts of nodes, where the second sort just plays the bureaucratic role of giving an end to edges that otherwise would be drawn as loose [Reference Dixon and Kissinger46].
. Historically, a solution to this problem has been to consider as interpretation a more sophisticated notion of graph, endowed with a topology from which one can define when edges are ‘loose’, ‘half-loose’, ‘pinned’, and so on; see [Reference Joyal and Street77]. Another, more recent approach understands string diagrams as graphs with two sorts of nodes, where the second sort just plays the bureaucratic role of giving an end to edges that otherwise would be drawn as loose [Reference Dixon and Kissinger46].
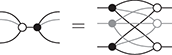
The approach we present follows [Reference Bonchi, Gadducci, Kissinger, Sobociński and Zanasi13]. We do not regard boxes as nodes, but rather as hyperedges: edges that connect lists of nodes, instead of individual nodes. This perspective allows us to work with a well-known data structure (simpler than the ones above) called a hypergraph: the only entities appearing in a hypergraph are hyperedges and nodes: these interpret the boxes and the loose ends of wires in a string diagram, respectively. And the wires themselves? They are simply a depiction of how hyperedges connect with the associated nodes. Such an interpretation applies as follows to our leading example:

Note that, even though they are seemingly very close in shape, the two entities just displayed are of a very different nature. The one on the left is a syntactic object: the string diagram representing some term modulo the laws of SMCs. The one on the right is a combinatorial object: a hypergraph, with nodes indicated as dots and hyperedges indicated as boxes with round corners, labelled with  -operations.Footnote 6
-operations.Footnote 6
In order to turn this mapping into a formal interpretation, we need an understanding of how to handle composition of string diagrams. Intuitively, parallel composition is simple: if we stack one hypergraph over the other, we still obtain a valid hypergraph. For instance:
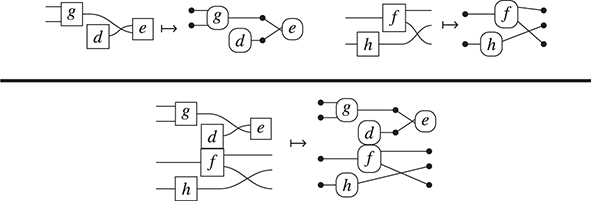
Sequential composition is subtler, as we need to formally specify how loose wires of one string diagram are ‘plugged in’ loose wires of another diagram.
A proper definition of this composition operation is what leads to the notion of an open hypergraph: a hypergraph with a record of what nodes form its left interface and what nodes form its right interface. Note that one node can be in both, as in (3.1). Pictorially, we will display the interfaces as separate discrete hypergraphs,Footnote 7 one on the left and one on the right, with dotted lines indicating which nodes of the actual hypergraph lie on which interface. Our leading example corresponds to the following open hypergraph on the right.

Thanks to this additional information, the open hypergraph comes endowed with a built-in notion of sequential composition, mimicking the sequential composition of string diagrams. We are allowed to compose two open hypergraphs sequentially whenever the right interface of the first coincides with the left interface of the second.
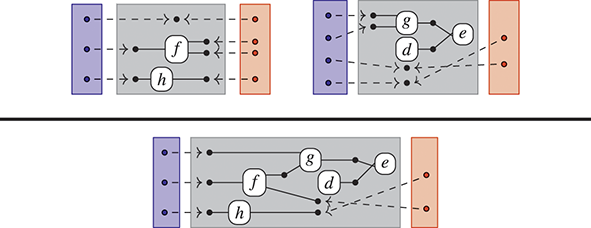
Equipped with this notion, we may define the interpretation of string diagrams as open hypergraphs, inductively on  -terms: for each
-terms: for each  in
in  , we have
, we have
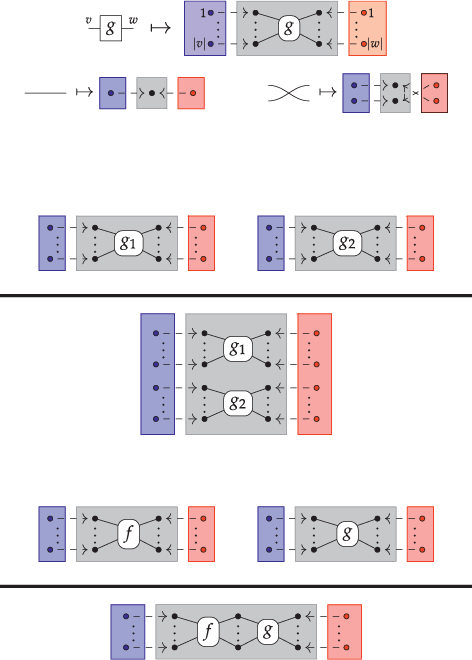
In words, the vertical composition takes the disjoint sum of each of the interfaces and hypergraphs, while the horizontal composition identifies the middle interface labels and includes them as nodes into the composite hypergraph. Note that this definition extends to an interpretation of string diagrams by verifying that it respects equality modulo the laws of SMCs – that is, if two  -terms are represented by the same string diagram, then they are mapped to the same open hypergraph.
-terms are represented by the same string diagram, then they are mapped to the same open hypergraph.
As a side note, it is significant that moving from hypergraphs to open hypergraphs does not force us to complicate the notion of graph at hand, for instance by adding a different sort of nodes. From a mathematical viewpoint, an open hypergraph  may be simply expressed as a structure consisting of two hypergraph homomorphisms
may be simply expressed as a structure consisting of two hypergraph homomorphisms  , where
, where  and
and  are discrete hypergraphs, and the image
are discrete hypergraphs, and the image  (resp.
(resp.  ) identifies the nodes in the left (resp. right) interface of
) identifies the nodes in the left (resp. right) interface of  . The visualisation in (3.1) shows such encoding:
. The visualisation in (3.1) shows such encoding:  is the hypergraph on the left side,
is the hypergraph on the left side,  is the one on the right side, and
is the one on the right side, and  is the one in the middle. The dotted lines, identifying the interfaces of
is the one in the middle. The dotted lines, identifying the interfaces of  , now take formal meaning as the definition of functions
, now take formal meaning as the definition of functions  and
and  .
.
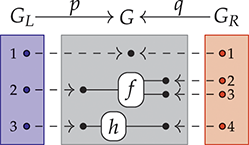
The structure  is often called a cospan of hypergraphs (see Example 5.11 on the simpler cospans of sets), with carrier
is often called a cospan of hypergraphs (see Example 5.11 on the simpler cospans of sets), with carrier  . When referring to
. When referring to  as an open hypergraph, we always implicitly refer to
as an open hypergraph, we always implicitly refer to  together with one such cospan structure. Reasoning with cospans is convenient as they come with a built-in notion of composition (by ‘pushout’ in the category of hypergraphs) which is exactly how the informal composition of open hypergraphs given earlier is formally defined. We will come back to this point in Section 6.1, as it plays a role in how we rewrite with string diagrams.
together with one such cospan structure. Reasoning with cospans is convenient as they come with a built-in notion of composition (by ‘pushout’ in the category of hypergraphs) which is exactly how the informal composition of open hypergraphs given earlier is formally defined. We will come back to this point in Section 6.1, as it plays a role in how we rewrite with string diagrams.
The interpretation of string diagrams as open hypergraphs given in (3.1) defines a monoidal functor  from the free SMC over signature
from the free SMC over signature  to the SMC of cospans of hypergraphs.
to the SMC of cospans of hypergraphs.
An important question stemming from the interpretation (3.1) is: to what extent are the syntactic and the combinatorial perspectives on string diagrams interchangeable? First, one may show that  is an injective mapping: string diagrams that are distinct (modulo the laws of SMCs) are mapped to distinct open hypergraphs. However, it is clearly not surjective. Here are some examples of open hypergraphs over a signature
is an injective mapping: string diagrams that are distinct (modulo the laws of SMCs) are mapped to distinct open hypergraphs. However, it is clearly not surjective. Here are some examples of open hypergraphs over a signature  which are not the interpretation of any
which are not the interpretation of any  -string diagram.
-string diagram.

These examples have something in common: nodes are allowed to behave more freely than in the image of interpretation of (3.1). For instance, in the first hypergraph there is an ‘internal’ node (not on the interface) that has multiple outgoing links to hyperedges. In the second hypergraph, there is an internal node that has no incoming links. Finally, the third hypergraph features a node that can be plugged in twice on the left interface; when composing with another hypergraph on the left, it will have two incoming links.
We can prove that such features are forbidden in the image of  . The property that disallows them is called monogamy [Reference Bonchi, Gadducci, Kissinger, Sobociński and Zanasi13].
. The property that disallows them is called monogamy [Reference Bonchi, Gadducci, Kissinger, Sobociński and Zanasi13].
Definition 3.1 (Degree of a node). The in-degree of a node  in a hypergraph
in a hypergraph  is the number of pairs
is the number of pairs  where
where  is a hyperedge with
is a hyperedge with  as its
as its  -th target. Similarly, the out-degree of
-th target. Similarly, the out-degree of  in
in  is the number of pairs
is the number of pairs  where
where  is a hyperedge with
is a hyperedge with  as its
as its  -th source.
-th source.
Definition 3.2 (Monogamy). An open hypergraph  is monogamous if
is monogamous if  and
and  are injective and, for all nodes
are injective and, for all nodes  of
of  ,
,
the in-degree of
is if is in the image of and otherwise;the out-degree of
is if is in the image of and otherwise.










Moreover, any hypergraph that corresponds to a string diagram is acyclic: there are no directed paths containing the same node twice. These two properties are enough to characterise string diagrams.
Theorem 3.3. An open hypergraph is in the image of  if and only if it is monogamous and acyclic.
if and only if it is monogamous and acyclic.
Corollary 3.4. String diagrams over  are in one-to-one correspondence with
are in one-to-one correspondence with  -labelled monogamous and acyclic open hypergraphs.
-labelled monogamous and acyclic open hypergraphs.
Theorem 3.3 settles the question of what kind of open hypergraphs correspond to ‘syntactically generated’ string diagrams. We may also ask the converse question: what do we need to add to the algebraic specification of string diagrams in order to capture all the open hypergraphs?
Remarkably, the special and commutative Frobenius monoid from Example 2.18 is tailored to the role. Indeed we can give an interpretation to the operations of Example 2.18, as discrete open hypergraphs:
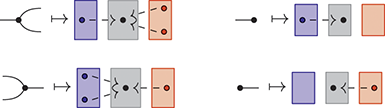
Intuitively, the Frobenius generators are modelling the possibility that a node has multiple or no ingoing/outgoing links, just as in the above examples. If we now consider string diagrams over  augmented with the generating operations of a Frobenius monoid, we can infer the string diagrams for the preceding open hypergraphs:
augmented with the generating operations of a Frobenius monoid, we can infer the string diagrams for the preceding open hypergraphs:

These observations generalise to the following result, thus completing the picture of the correspondence between string diagrams and open hypergraphs. In stating it, we write  for the signature given by the disjoint union of the generators of
for the signature given by the disjoint union of the generators of  and of
and of  , the theory of a special commutative Frobenius monoid given in (2.8).
, the theory of a special commutative Frobenius monoid given in (2.8).
Theorem 3.5. String diagrams on the signature  modulo the axioms of special commutative Frobenius monoids given in (2.8) are in one-to-one correspondence with
modulo the axioms of special commutative Frobenius monoids given in (2.8) are in one-to-one correspondence with  -labelled open hypergraphs.
-labelled open hypergraphs.
Note that it is not just the signature: the axioms of special commutative Frobenius monoids also play a role in the result, as they model precisely equivalence of open hypergraphs.
Remark 3.6. Given a signature  , Open hypergraph with
, Open hypergraph with  -labelled nodes and
-labelled nodes and  -labelled hyperedges form a symmetric monoidal category
-labelled hyperedges form a symmetric monoidal category  , whose morphisms are hypergraph homomorphisms respecting the labels. The monogamous and acyclic open hypergraphs form a subcategory
, whose morphisms are hypergraph homomorphisms respecting the labels. The monogamous and acyclic open hypergraphs form a subcategory  of
of  . One may phrase Theorem 3.3 and Theorem 3.5 in terms of these categories by saying that there is an isomorphism between
. One may phrase Theorem 3.3 and Theorem 3.5 in terms of these categories by saying that there is an isomorphism between  and
and  , and an isomorphism between
, and an isomorphism between  and
and  .
.
4 Categories of String Diagrams
Manipulating string diagrams can be confusing to the newcomer because there are actually many flavours, each of which authorises or forbids different deformations and manipulations. To make matters worse, many papers will assume that the reader is comfortable with the rules of the game for the authors’ specific flavour, and gloss over the basic transformations. This is not necessarily a bad thing, as the point of string diagrams is to serve as a useful computational tool, a syntax that empowers its users by absorbing irrelevant details into the topology of the notation itself. This section is here to convey the basic rules for the most common forms one is likely to encounter in the literature. We will give some insight into the manipulations that are authorised and those that are forbidden in each context, illustrating them through several examples.
In previous sections, we made the conscious choice of starting with string diagrams for symmetric monoidal categories. Let us recall the rules of the game briefly: we were allowed to compose boxes horizontally, as long as the types of the wires matched, and vertically, without restriction. In addition, we were allowed to cross wires however we wanted, and the only relevant structure of an arbitrary vertical or horizontal composite of multiple wire-crossings is the resulting permutation of the wires that it defines.
We will now see that there are various ways of strengthening or weakening these rules and the class of string diagrams under consideration. For the reader willing to delve further into this subject, we recommend Selinger’s extensive survey of diagrammatic languages for monoidal categories [Reference Selinger106].
4.1 Fewer Structural Laws
4.1.1 Monoidal Categories
What if we take away the ability to cross wires? Terms of the free monoidal category over a chosen signature  are generated by the following derivation rules:
are generated by the following derivation rules:
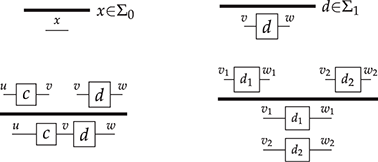
The difference with symmetric monoidal categories is that we no longer have the built-in symmetry components
at our disposal. We consider two terms structurally equivalent when they can be obtained from one another using the axioms of monoidal category, that is, the strict subset of those symmetric monoidal categories that do not involve the symmetry/wire-crossing, as found in (2.3). For example, we still have the interchange law
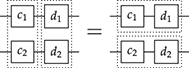
but we do not have
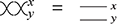
, as
is not even a term of our syntax. Intuitively, they are the planar cousins of their symmetric counterpart, that is, the subset of string diagrams we can draw in the plane in a symmetric monoidal category without crossing any wires. In a way, the rules are simpler: we can only compose string diagrams horizontally (with the usual caveat that the right ports of the first have to match the left ports of the second) and vertically. That’s it. Then, two string diagrams are equivalent if one can be deformed into the other without any intermediate steps that involve crossing wires. For example,
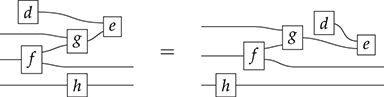
The last caveat is important, as two monoidal diagrams could be equivalent if we interpreted them (via the obvious embedding) as symmetric monoidal diagrams, but not equivalent as monoidal diagrams. This is the case for the two following diagrams:
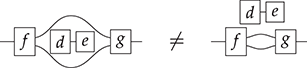
Thus, in the monoidal case, certain string diagrams can be trapped between some wires, without any way to move them on either side – whereas, in the symmetric monoidal case, we could have just pulled the middle diagram out, past the surrounding wires.
4.1.2 Braided Monoidal Categories
Braided monoidal categories [Reference Joyal and Street76] are one step up from monoidal categories, but are not symmetric. They allow a form of wire crossing that keeps track of which wire goes over which. To this effect, we introduce a braiding for each of the two possibilities depicted suggestively as follows:

Term formation rules for the free braided monoidal category over a given signature  are those of monoidal categories plus the following two:
are those of monoidal categories plus the following two:

The notion of structural equivalence is up to the axioms of braided monoidal categories, which we now give:
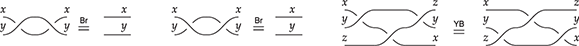
As the drawings suggest, the intuition for the braiding is that string diagrams now inhabit a three-dimensional space in which we are free to cross wires by moving them over or under each other. The first two laws state that the two braidings are inverses of each other, and the third is an instance of the naturality of the wire crossings, called the Yang–Baxter equation [Reference Cheng29]. Notice that these axioms are similar to those for the symmetry in SMCs except that braidings are not self-inverse:
does not hold if we take
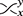
instead (see what follows). As a result, we can draw any string diagram we could draw in a symmetric monoidal category, but we have to pick which wire goes under and which goes over for each crossing.
Two string diagrams are equivalent if they can be deformed into each other without ever moving two wires through one another to magically disentangle them. Once more, this gives an equivalence that is finer than that of symmetric monoidal categories.Footnote 8 A simple illustrative example of this phenomenon is the following twist:

If we replaced the two braidings by the symmetry to obtain a term of a symmetric monoidal category, this string diagram would simply be the identity

. This serves as a reminder that the braiding is not self-inverse. One can find much more interesting examples – in fact, we can draw arbitrary braids:

or string diagrams containing other generators with arbitrary braidings between them, which can be transformed like those of symmetric monoidal categories, as long as we do not move any of the wires through one another:
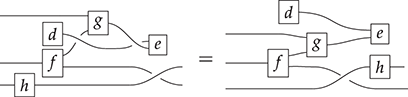
Remark 4.1. Contrary to the case of SMCs (see Section 3), there is no known representation of string diagrams for braided monoidal categories as graphs.
4.2 More Structural Laws
Just like we can weaken the structure of symmetric monoidal categories and draw more restricted diagrams, we can also extend our diagrammatic powers. The following is a non-exhaustive list of the most common variations one might find in the literature.
4.2.1 Traced Monoidal Categories
String diagrams in a (symmetric) monoidal category keep to a strict discipline of acyclicity: we can only connect the right and left ports of two boxes. One could imagine relaxing this requirement, while keeping a clear correspondence between left ports as inputs and right ports as outputs.
Term formation rules for traced monoidal categories are those of symmetric monoidal categories with the addition of an operation that allows us to form loops, called the partial trace:Footnote 9
The corresponding notion of structural equivalence is given by the following axioms (with object labels removed for clarity).
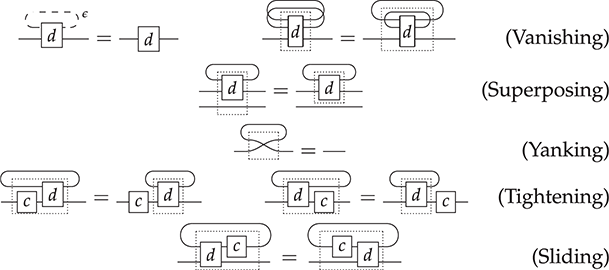
Here, we had to briefly go back to using dotted frames, because the axioms of traced monoidal categories are almost diagrammatic tautologies (which is the point of adopting a diagrammatic notation for them).
In short, string diagrams for traced monoidal categories include those of symmetric monoidal ones, but add the possibility of connecting any right port of any diagram to any left port of any other with the same type, as in the following example:
In essence, we have the ability to draw loops, breaking free from the acyclicity requirement of plain symmetric monoidal diagrams. However, we cannot bend wires arbitrarily, or connect right (resp. left) ports to right (resp. left) ports. For example, the following is not allowed:
(although we will soon introduce a syntax for which this kind of diagrams is allowed.)
The reader should convince themselves that the preceding string diagram is equivalent to the following one on the right:

As for symmetric monoidal diagrams, the trick to check this equality lies in verifying that the connectivity of the different boxes is preserved.
Remark 4.2. Traced string diagrams are often used when describing computational processes that feature some form of recursion or iteration. In this context, it is also natural to consider trace-like operations that do not satisfy the yanking axiom. This makes sense when the trace-like operation is intended to represent a form of feedback which introduces a temporal delay. Examples abound in the theory of automata. Note that the sliding rule might also fail in this case. The associated graphical language generalises that of traced categories, and the associated structure is sometimes called a delayed or guarded traced category, or a category with feedback [Reference Di Lavore, de Felice, Román and Baier44, Reference Di Lavore, Gianola, Román, Sabadini, Sobociński, Salaün and Wijs45, Reference Katis, Sabadini and Walters78].
4.2.2 Compact Closed Categories
Compact closed (or more simply, compact) categories are special cases of traced monoidal categories where, rather than adding a global trace operation, we add ways of moving ports from left to right and vice versa, using extra generators that represent wire-bending directly, as built-in operations.
The term formation rules are those of symmetric monoidal categories except the identity introduction rules, with the following additions:
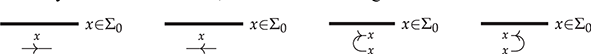
In words, we introduce a new object  (called the dual of
(called the dual of  ) for every object
) for every object  and write
and write  for the identity on
for the identity on  and
and  for the identity on
for the identity on  . The objects
. The objects  and
and  are related by two wire-bending diagrams
are related by two wire-bending diagrams  and
and  , called cup and cap respectively.
, called cup and cap respectively.
The corresponding notion of structural equivalence is defined by the axioms of symmetric monoidal category and the following two axioms, which capture the duality between inputs and outputs:

These are sometimes called the snake or yanking equalities.
Using the symmetry, we can define syntactic sugar for two other cups and caps, bending wires in the other direction, which we write as:

From cups and caps, we also obtain a partial trace operation given simply by
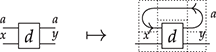
This operation satisfies all the required axioms of traced monoidal categories (it is an instructive exercise to prove them). Importantly, what was a global operation before is now decomposed into smaller components that use the added generators. This is particularly helpful in applications, whenever we aim at reasoning compositionally about feedback loops in a system. Whereas the notion of trace is ‘native’ to traced monoidal categories, it is a derived concept in compact closed categories.
For traced monoidal categories, we could draw loops directly, to connect any left port to any right port of a diagram. We could always read information in a given diagram as flowing from left to right, except in a looping wire, where it flows backwards at the top of the loop until it reaches its destination. Now that we can move left ports to the right of a diagram and right ports to the left, we have to be a bit more careful. This is why we have to annotate each wire with a direction.
We can understand this as layering a notion of input and output on top of those of left and right ports. We can call inputs those wires that flow into a diagram and outputs those that flow out of a diagram, whether they are on the left or right boundary. Then, in a compact closed category, we are allowed to connect any input to any output, that is, we can assign a consistent direction to any wiring:
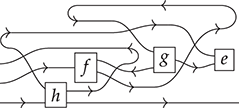
Furthermore, as it is now a leitmotiv, only the connectivity matters: we are allowed to straighten or bend wires at will, as long as we preserve the connections between the different sub-diagrams. For example, the following two diagrams are equivalent:
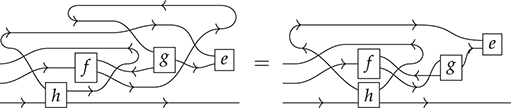
Finally, compact closed categories have the following very important property: diagrams of type  are in one-to-one correspondence with diagrams
are in one-to-one correspondence with diagrams  . Diagrammatically, moving
. Diagrammatically, moving  from the domain to the codomain is realised by bending the corresponding wire(s) using the cup
from the domain to the codomain is realised by bending the corresponding wire(s) using the cup
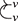
; moving in the other direction simply uses
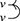
to bend the  -wires back in place.
-wires back in place.

The fact that these operations are inverses to each other is an easy consequence of the snake equalities (4.1), with which we can straighten the wires back into place. As a result,  can be seen as an internal analogue of the set of string diagrams
can be seen as an internal analogue of the set of string diagrams  . This property is found more generally in closed monoidal categories, which we cover in Section 4.2.9.
. This property is found more generally in closed monoidal categories, which we cover in Section 4.2.9.
4.2.3 Self-Dual Compact Closed Categories
There are significant instances of compact closed category where the distinction between inputs and outputs disappears completely: they are called self-dual. The term formation rules are the same as those symmetric monoidal categories, with the following additions:
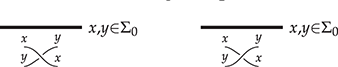
They are also very close to those of compact closed categories, but we identify  and its dual. As a result, there is no need to introduce a direction on wires. The added constants
and its dual. As a result, there is no need to introduce a direction on wires. The added constants
and
satisfy the same equations as their directed cousins:
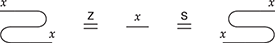
Without distinct duals there is no need to keep track of the directionality of wires, and the resulting diagrammatic calculus is even more permissive – there are no inputs or outputs, and we are now allowed to connect any two ports together:
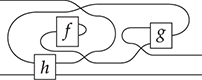
As before, the structural equivalence on diagrams allows us to identify any two diagrams where the same ports are connected:
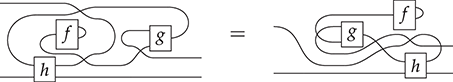
The previous three examples progressively relax which two ports we can connect together; in the following examples, we relax the requirement that only two ports can be connected at a time by introducing different ways to split and end wires.
4.2.4 Copy-Delete Monoidal Categories
The first of these adds the ability to split and end wires in order to connect some wire in the right boundary of a diagram to a (possibly empty) set of wires in the left boundary of another. There are several names for these in the literature (Copy-Delete monoidal categories, gs-monoidal categories, etc.), but we will call them CD categories for short.
The term formation rules for CD categories are the same as those for symmetric monoidal categories, with the addition of wire splitting and ending for each generator:
As anticipated, the copying and deleting operations allow us to connect a given right port of a diagram to a (possibly empty) set of left ports of another:
Notice, however, that there are several ways of connecting the same set of wires. For example, we could have connected the left boundary wire to  , and
, and  as follows:
as follows:
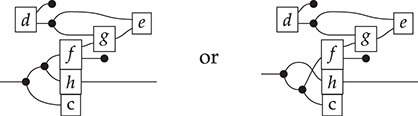
or any other way of connecting this wire to the same three boxes. To define a sensible notion of multi-wire connection, we need to add axioms that allow us to consider all these different ways of composing
and
equal if they connect the same wire to the same set of wires. To achieve this, and obtain a suitable notion of structural equivalence for CD categories, we add the following equalities to those of SMCs:
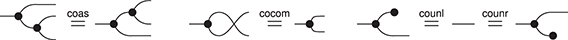
The reader will recognise these laws from Example 2.14 as those of a commutative comonoid: they tell us that there is only one way of splitting a single wire into  wires, for any natural
wires, for any natural  .
.
Using  and
and  for generating objects
for generating objects  , we can define
, we can define  and
and  for any word
for any word  over
over  or, more plainly, for arbitrarily many wires. We do so by induction:
or, more plainly, for arbitrarily many wires. We do so by induction:
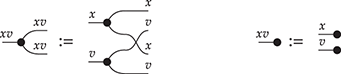
As mentioned in Example 2.14, it is typical in applications that and are interpreted as gates that duplicate and discard a resource. With this perspective, CD categories are categories whose structure makes duplicating and discarding of a resource explicit when it is used in some computation. This feature allows for a resource-sensitive analysis of processes. For instance, in CD categories we generally have that
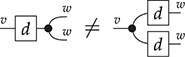
Intuitively, this means that we distinguish the case of a process  using resource of type
using resource of type  once and then copying its output, from a process which duplicates it before letting two copies of
once and then copying its output, from a process which duplicates it before letting two copies of  consume it.
consume it.
4.2.5 Cartesian Categories
Often, one would like to go further than having an operation that allows us to split and end wires – certain SMCs extend the capability of these operations to copy and delete boxes too. This is the ability that cartesian categoriesFootnote 10 give us.
The term formation rules for cartesian categories are the same as those for CD categories. The corresponding notion of structural equivalence further quotients that of CD categories with the following axioms, which capture the ability to copy and delete diagrams: for any  in
in  , we have
, we have

Note that this axiom scheme applies to generating operations with potentially multiple wires. To instantiate it, recall the definition of
and
for multiple wires given in (4.3). Then, if we apply these to  , we get
, we get

where we omit object labels for clarity. As for CD categories, we can now connect a given right port of a diagram to a (possibly empty) set of left ports of another:
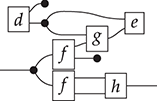
But the structural notion of equivalence for cartesian categories is much coarser. For the first time in this Element, we encounter a diagrammatic language where the structural equivalence is not topological, and where equivalence cannot simply be checked by examining the connectivity of the different sub-diagrams. In practice, this can make it more difficult to identify when two diagrams are equivalent. As well as those that have the same connectivity between their different components, we can identify diagrams where one contains several copies of the same sub-diagram, connected by the same
, or where one contains a sub-diagram connected to a
and the other does not, for example,
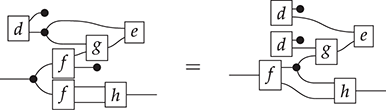
In this diagram, from left to right, we have merged the two occurrences of  and copied
and copied

. It is helpful to break down the required equational steps:
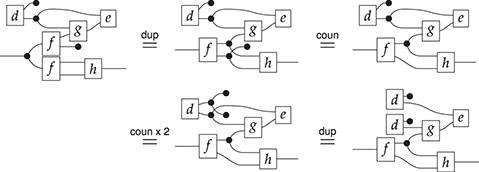
In plain English, we first merge the two occurrences of  using the
using the  equation (from right to left); apply the counitality axiom of the comonoid structure to get rid of the extra counit and leave a plain wire; and apply the counitality axiom of the comonoid twice (from right to left this time) to produce a diagram from which the
equation (from right to left); apply the counitality axiom of the comonoid structure to get rid of the extra counit and leave a plain wire; and apply the counitality axiom of the comonoid twice (from right to left this time) to produce a diagram from which the  axiom applies to
axiom applies to  , which is the last equality.
, which is the last equality.
Remark 4.3 (Cartesian categories and algebraic theories). The diagrammatic syntax of cartesian categories is the diagrammatic counterpart of the standard symbolic notation for algebraic theories. In this correspondence, wires take the place of variables. Since variables can be used arbitrarily many times, we need additional machinery in the diagrammatic setting to handle variable management: this is where and come in. Moreover, just like we can substitute an arbitrary term for all occurrences of a given variable, we can copy and delete arbitrary diagrams using and with the axioms  -
- . This is what allows us to interpret composition as substitution.
. This is what allows us to interpret composition as substitution.
Let us examine the correspondence for a simple example; the general case is worked out (for the single-sorted case) in [Reference Bonchi, Sobociński and Zanasi23]. Consider the algebraic theory of monoids. It can be presented by two generating operations,  of arity
of arity  and
and  of arity
of arity  (a constant) satisfying the following three axioms:
(a constant) satisfying the following three axioms:  and
and  . Terms of this algebraic theory are syntax trees whose leaves are labelled with variable names, as on the left in the following diagram:
. Terms of this algebraic theory are syntax trees whose leaves are labelled with variable names, as on the left in the following diagram:
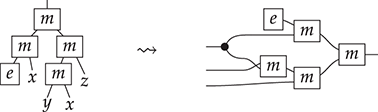
By simply turning the tree on its side and gathering all leaves labelled by the same variable with
(or deleting those that we do not use with
) we obtain the corresponding string diagram in the theory of cartesian categories, as on the right side.
We can also go in the other direction: from the diagrammatic syntax of a cartesian category over some signature, we can obtain an algebraic theory. This is done by noticing that every string diagram of such a category can be expressed as the composition of
,
with diagrams that have a single outgoing wire. Indeed, the copying and deleting axioms imply that all string diagrams  , with
, with  , can be decomposed uniquely into
, can be decomposed uniquely into  diagrams
diagrams  ,
,  , where
, where  are generating objects. Let us see concretely what this decomposition looks like and how to obtain the components for the case
are generating objects. Let us see concretely what this decomposition looks like and how to obtain the components for the case  . Let
. Let

We can then check that

The general case is completely analogous.
In the single-sorted case, that is, when the set of objects contains a single generator, the connection is clear: the decomposition property just presented implies that every string diagram in a cartesian category can be seen as a composite of and with operations with arity corresponding to the number of left wires they have (and implicitly, co-arity one).
Resuming our resource interpretation, observe that string diagrams in (4.4), whose equality is not enforced in CD categories, are always equated in cartesian categories. This means that cartesian categories are resource-insensitive by default, because they do not keep track of the interplay of processes and resources the same way CD categories do.
In applications, it is often interesting to enforce only a certain degree of (in)sensitivity, intermediate between CD and cartesian categories. A notable example is the one of Markov categories. In a Markov category we can always discard string diagrams, but we cannot copy them at will. More formally, their structure is defined by dropping from the definition of cartesian category the leftmost equation in (4.5). It turns out this setup is convenient for studying probabilistic computation, as it provides a baseline for interpreting string diagrams as stochastic processes. See Section 7 for more pointers to the literature on the topic.
4.2.6 Cocartesian Categories
If we flip all the diagrams of the previous section along the vertical axis, we obtain the duals of cartesian categories, namely cocartesian categories. They extend the language of symmetric monoidal categories, not with a commutative comonoid, but with a commutative monoid (see Example 2.13) instead:

Furthermore, we want these to merge (or co-copy) and spawn (or co-delete) any diagram as follows:

4.2.7 Biproduct Categories
Categories that are both cartesian and cocartesian are called biproduct categories. They feature a comonoid and a monoid structure on each object, satisfying the  -
- and
and  -
- axioms. Note one important consequence: if we apply
axioms. Note one important consequence: if we apply  to
to
,  to
to
,  to
to
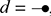
, and  to
to
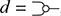
, we get the following:
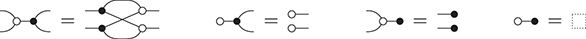
These are the defining axioms of bimonoids, as introduced in Example 2.16.
4.2.8 Hypergraph Categories
Hypergraph categories further extend the capabilities of CD categories. Similar to biproduct categories, they include both a monoid and a comonoid but, as we will see, these interact differently.
The term formation rules are the same as for biproduct categories, that is, those for symmetric monoidal categories, with the following additions:

The first two are similar to the extra generators of CD categories. The last two are their mirror image. We write them in black instead of the white generators of cocartesian and biproduct categories since they will play a different role, as we will now see.
The corresponding notion of structural equivalence is given by the laws of symmetric monoidal categories with the addition of the axioms of special commutative Frobenius monoids (Example 2.18) summarised in (2.8). However, observe that we do not impose that every diagram can be (co)copied or (co)deleted, as we did for (co)cartesian categories. This is a key difference – in fact, as we will see later, these two requirements turn out to be incompatible in a rather fundamental way.
The diagrammatic language of hypergraph categories is the most permissive: it allows any set of ports (left or right) of the same sort to be connected together via
,
,
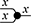
, and
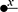
. In fact, as we have seen in Example 2.17, any two connectedFootnote 11 diagrams made exclusively of these black generators, are equal if and only if they have the same number of left and right ports, a fact known as the spider theorem. For example, we can use the defining axioms of Frobenius monoids to show that the following two diagrams are equivalent:
This means that the only relevant structure of a given connected diagram made entirely of
,
,
, and
is the number of ports on the left and on the right. As a result, as we saw in Example 2.17, we can introduce the following black nodes as syntactic sugar for any such diagram with  dangling wires on the left and
dangling wires on the left and  on the right:
on the right:

Using this convenient notation, any string diagram in a hypergraph category will look like a hypergraph, as introduced in Section 3: boxes act as hyperedges, which may be wired together via black nodes.
In fact, this observation is what justifies the name ‘hypergraph category’ for these structures. Once more, two diagrams are equivalent if they connect the same ports via black nodes. For example, the following two are equivalent:
We could justify this equality through a sequence of Frobenius monoid axioms and the laws of symmetric monoidal categories, but it would be very time-consuming! It suffices to check that the connectivity of the different labelled boxes and black nodes remains the same. This is why hypergraph categories are very appealing.
These examples lead us to observe that hypergraph categories are always self-dual compact closed.Footnote 12 With the previous intuition, this observation is not too surprising: if we are able to connect any set of ports, we can connect any two pairs of ports. More formally, we can define cups and caps as
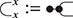
and
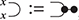
, for any  in the signature. That they satisfy the axioms of compact closed categories is a consequence of the Frobenius monoid axioms (or, more generally, of the spider theorem). We give the diagrammatic proof explicitly here, as it is instructive:
in the signature. That they satisfy the axioms of compact closed categories is a consequence of the Frobenius monoid axioms (or, more generally, of the spider theorem). We give the diagrammatic proof explicitly here, as it is instructive:

The other equation can be proved in the same way. That the resulting compact structure is also self-dual is immediate, since the cups and caps we have defined relate any given object to itself.
Remark 4.4 (A matter of perspective). The reader may have noticed that the additional structure of CD categories, self-dual compact closed, and hypergraph categories can also be seen as the free SMC over a theory that includes some additional generators and equations (cf. Section 2.1). For example, the free CD category over the theory  is definable as the free SMC over the theory formed by signature
is definable as the free SMC over the theory formed by signature  and equations, those in
and equations, those in  plus those in (4.2). Whether we pick one perspective or the other depends on which structure we want to see as built-in and which we want to see as domain-specific in the considered application.
plus those in (4.2). Whether we pick one perspective or the other depends on which structure we want to see as built-in and which we want to see as domain-specific in the considered application.
4.2.9 Closed Monoidal Categories
In monoidal categories that are closed, the set of string diagrams  can be seen as an object
can be seen as an object  of the category itself. Closed monoidal categories arise naturally in applications where it makes sense to consider higher-order functions: processes that can take functions as inputs and can output other functions. Objects of the form
of the category itself. Closed monoidal categories arise naturally in applications where it makes sense to consider higher-order functions: processes that can take functions as inputs and can output other functions. Objects of the form  are called exponentials.
are called exponentials.
The existence of exponentials  for all
for all  is not sufficient to form a closed monoidal category. We need extra conditions that encode the behaviour of
is not sufficient to form a closed monoidal category. We need extra conditions that encode the behaviour of  as some sort of function space. For this, we require the existence of a family of morphisms
as some sort of function space. For this, we require the existence of a family of morphisms  depicted as
depicted as
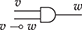
with the following property: for every  , there exists a unique morphism
, there exists a unique morphism  , such that
, such that

Intuitively,  acts like an evaluation map that applies a function
acts like an evaluation map that applies a function  to a value of type
to a value of type  and returns a
and returns a  . In usual programming terms,
. In usual programming terms,  is a curried version of
is a curried version of  which, given an argument of type
which, given an argument of type  , returns a morphism
, returns a morphism  . We can also see
. We can also see  as a family of morphisms, sending objects
as a family of morphisms, sending objects  and morphisms of type
and morphisms of type  to morphisms of type
to morphisms of type  , for any
, for any  . In fact, this defines a natural one-to-one correspondences between sets of morphisms of these typesFootnote 13. This construction is also known as (
. In fact, this defines a natural one-to-one correspondences between sets of morphisms of these typesFootnote 13. This construction is also known as ( -)abstraction in programming language theory.
-)abstraction in programming language theory.
It is possible to make the string diagrammatic language of closed monoidal categories even more appealing, by introducing a pictorial notation for the abstraction map  , represented as a box surrounding a given string diagram. For instance, given
, represented as a box surrounding a given string diagram. For instance, given  ,
,  becomes
becomes
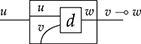
The different orientation of wires  and
and  in the box signals the different roles they play: intuitively,
in the box signals the different roles they play: intuitively,  awaits an input of type
awaits an input of type  on its left, in order to form a function with input of type
on its left, in order to form a function with input of type  . As is the case with any string diagrammatic language introduced so far, this notation finds formal justification in terms of categorical structures: it is syntactic sugar for so-called functorial boxes [Reference Melliès and Ésik91], which capture the behaviour of
. As is the case with any string diagrammatic language introduced so far, this notation finds formal justification in terms of categorical structures: it is syntactic sugar for so-called functorial boxes [Reference Melliès and Ésik91], which capture the behaviour of  . We will not cover functorial boxes in detail here, though we recall briefly what they are in the Appendix.
. We will not cover functorial boxes in detail here, though we recall briefly what they are in the Appendix.
The reader may find further details about the string diagrammatic language of closed monoidal categories in [Reference Ghica and Zanasi65: section 3]. We do not discuss it further, given how different it is from our other examples. We conclude by linking the closed monoidal structure to other categorical structures seen in this section.
First, as the name suggests, compact closed categories (Section 4.2.2) are closed monoidal. The objects  are defined as
are defined as  and the evaluation maps
and the evaluation maps  are defined by:
are defined by:
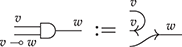
where  in compact closed categories. Moreover, in compact closed categories, abstraction can be realised by bending a wire as follows:
in compact closed categories. Moreover, in compact closed categories, abstraction can be realised by bending a wire as follows:
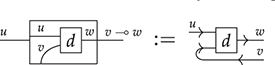
We see that the resulting diagram has type  as required. The ability to represent evaluation and abstraction as just wire bending is a special property of compact closed categories, which does not hold for generic closed monoidal ones.
as required. The ability to represent evaluation and abstraction as just wire bending is a special property of compact closed categories, which does not hold for generic closed monoidal ones.
Second, another important class of closed categories are those that are also cartesian (Section 4.2.5). Cartesian closed categories are the semantics of choice for most functional programming languages. The cartesian structure witnesses the fact that resources (represented as variables) may be used arbitrarily many times in most programming languages, while the closed structure reflects the ability to manipulate higher-order functions. Once again, we refer the reader to [Reference Ghica and Zanasi65] for an extensive discussion.
4.2.10 Mix and Match
We have seen several cases in which categorical structures blend together to give rise to interesting combinations. But beware! Certain combinations have undesired consequences. The classic example is that of the incompatibility between cartesian and compact closed categories. This can be made precise as the following claim: a category that is both cartesian and compact closed is degenerate, in the sense that it has at most one morphism between any two objects.Footnote 14 To show this, it suffices to derive from the axioms of cartesian and compact closed categories that all morphisms between any two objects are equal. We achieve this by proving that we can disconnect any wire, in two steps: first we show that the cup splits as follows,

(the reader might recognise this as an instance of Remark 4.3). Then we show that the identity can be disconnected
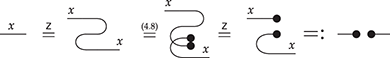
Finally, we can show what we wanted: for any  ,
,

Therefore, modulo equivalence there is at most one string diagram of type  . Note that the incompatibility between compact closed and cartesian structure implies that hypergraph and cartesian structure are also incompatible.
. Note that the incompatibility between compact closed and cartesian structure implies that hypergraph and cartesian structure are also incompatible.
Interestingly, if we weaken the cartesian compact closed structure to that of a cartesian traced monoidal category, the resulting combination not only avoids degeneracy, but turns out to be closely related to the notion of (parameterised) fixed point [Reference Hasegawa, de Groote and Hindley71]. A parameterised fixed-point operator in a cartesian SMC  takes a morphism
takes a morphism  and produces
and produces  . The operator
. The operator  is then required to satisfy a certain number of intuitive axioms. For instance,
is then required to satisfy a certain number of intuitive axioms. For instance,  should indeed be a fixed points of
should indeed be a fixed points of  , that is,
, that is,
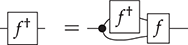
It is easy to see how to define such an operation in a traced category: let
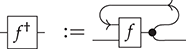
The axioms the fixed-point operator is required to satisfy are consequences of the axioms of traced monoidal categories with those of cartesian categories. For instance, it does satisfy (4.10):
where the second equality holds by the yanking and sliding axioms of the trace. Conversely, from a given fixed-point operator, we can define a trace. In fact, the notions of parameterised fixed points and cartesian traces are equivalent [Reference Hasegawa, de Groote and Hindley71: Theorem 3.1].
We conclude by mentioning another example of a useful interaction between different structures. String diagrams for braided and self-dual compact closed categories allow us to draw arbitrary knots:
The central result for these categories is that two different, closed (i.e. with empty left and right boundaries) diagrams are equal if and only if the corresponding knots can be topologically deformed into one another – thus, the topological notion of knot is fully captured by a few algebraic axioms. We see here another advantage of working with string diagrams: they give an algebraic home to topological concepts that are otherwise difficult to express in standard algebraic syntax.
5 Semantics
So far, we have thoroughly explored an arsenal of diagrammatic syntax, each kind corresponding to a specific flavour of monoidal category. We have occasionally discussed what is the intended ‘meaning’ of these structures, that scientists have in mind when reasoning about a certain phenomenon with string diagrams. In this section, we explain how assigning meaning to string diagrams can be made formal, as a semantics.
Our approach to string diagram semantics draws inspiration from the study of denotational semantics of programming languages. In programming practice, computations are not mere manipulations of symbols, devoid of content; there is a task, a mathematical object, which we intend to describe with the program. A denotational semantics specifies what that ‘something’ is intended to be. It allows us to define the behaviour of programs in a given language rigorously, and prove more easily certain properties that they satisfy. The same language can even have different semantic interpretations. A well-chosen semantics may allow us to circumscribe more precisely the expressiveness of the language, or to rule out certain classes of behaviour.
5.1 From Syntax to Semantics, Functorially
Generally speaking, a semantics is a mapping from syntax to a domain of interpretation. Categorically, this idea may be applied to string diagrams using the ingredients introduced in the previous sections. Our starting point is a symmetric monoidal theory  . Then string diagrams of the free symmetric monoidal category
. Then string diagrams of the free symmetric monoidal category  over
over  is our syntax.
is our syntax.
Now, in order to interpret such syntax, a domain of interpretation should mirror its basic structure. This is why we consider categories  that are symmetric monoidal for the task. A semantics for
that are symmetric monoidal for the task. A semantics for  will then be a mapping that preserves such structure, that is, a symmetric monoidal functor
will then be a mapping that preserves such structure, that is, a symmetric monoidal functor  .
.
If  was a generic category, in order to define
was a generic category, in order to define  we would need to come up with a definition of
we would need to come up with a definition of  and
and  for any object
for any object  and string diagram
and string diagram  of
of  . However, because
. However, because  is freely generated by
is freely generated by  , our task is simpler. In order to fully define
, our task is simpler. In order to fully define  , it suffices to assign it a value only on the generating objects and operations of
, it suffices to assign it a value only on the generating objects and operations of  , and make sure they satisfy the relevant equations.
, and make sure they satisfy the relevant equations.
More explicitly, giving a semantic interpretation of  in
in  amounts to specifying:
amounts to specifying:
an object
of for each generating object ;a morphism
of for each generating operation of type ;







Moveover, this should be done in such a way that the equations of  are satisfied, in the sense that
are satisfied, in the sense that  implies
implies  .
.
Giving such an interpretation for the generators completely defines a symmetric monoidal functor  , in a canonical way. The semantics of an arbitrary object of
, in a canonical way. The semantics of an arbitrary object of  , which is a word
, which is a word  of generating objects, is computed as
of generating objects, is computed as  . The semantics of an arbitrary (composite) string diagram is computed using the composition and monoidal product in the semantics, as long as the latter has the appropriate structure:
. The semantics of an arbitrary (composite) string diagram is computed using the composition and monoidal product in the semantics, as long as the latter has the appropriate structure:
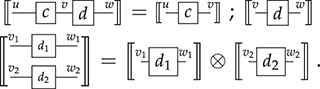
Finally, because  should be a symmetric monoidal functor, symmetries
should be a symmetric monoidal functor, symmetries  are mapped to symmetries
are mapped to symmetries  of
of  , and similarly for the identities.
, and similarly for the identities.
In a sense, one may regard such description of  as a definition of semantics by structural induction on string diagrammatic syntax. Remarkably, it is an inductive definition where we just need to specify the base cases, and the inductive step is always given by (5.1). It is worth emphasising once more that this style of definition is only possible because
as a definition of semantics by structural induction on string diagrammatic syntax. Remarkably, it is an inductive definition where we just need to specify the base cases, and the inductive step is always given by (5.1). It is worth emphasising once more that this style of definition is only possible because  is a free symmetric monoidal category. Our recipe for
is a free symmetric monoidal category. Our recipe for  implicitly exploits the universal property of free constructions; see Remark 2.9. Also, note that (5.1) is what we commonly refer to as the property of compositionality: the semantics of a compound diagram is entirely determined by the semantics of its elementary components. Compositionality is a crucial property in software analysis, as it makes formal reasoning feasible at a large scale. Being able to reason semantically about graphical models using decompositions based on (5.1) is a major appeal of string diagrammatic approaches.
implicitly exploits the universal property of free constructions; see Remark 2.9. Also, note that (5.1) is what we commonly refer to as the property of compositionality: the semantics of a compound diagram is entirely determined by the semantics of its elementary components. Compositionality is a crucial property in software analysis, as it makes formal reasoning feasible at a large scale. Being able to reason semantically about graphical models using decompositions based on (5.1) is a major appeal of string diagrammatic approaches.
One last word about syntax. In the examples of semantics that we consider in the following sections, we will often remark that the domain of interpretation  has more structure than just symmetric monoidal. In particular, we will see categories that are also cartesian, hypergraph, and so on, in the sense of Section 4. In such cases, it is often interesting to consider string diagrammatic syntax that also exhibits such structure, and study structure-preserving interpretations. To do so, we can introduce
has more structure than just symmetric monoidal. In particular, we will see categories that are also cartesian, hypergraph, and so on, in the sense of Section 4. In such cases, it is often interesting to consider string diagrammatic syntax that also exhibits such structure, and study structure-preserving interpretations. To do so, we can introduce  for the free
for the free  -category over
-category over  , where
, where  stands for one of the structures considered in Section 4, for example, cartesian, hypergraph, and so on. These can be defined analogously to the free symmetric monoidal category
stands for one of the structures considered in Section 4, for example, cartesian, hypergraph, and so on. These can be defined analogously to the free symmetric monoidal category  , except that the built-in generators are not just the symmetries and identities
, except that the built-in generators are not just the symmetries and identities  , but also the generators and equations specific to that structure. For instance, the free cartesian category
, but also the generators and equations specific to that structure. For instance, the free cartesian category  will have additional generators and for each generating object
will have additional generators and for each generating object  , satisfying all the appropriate axioms.
, satisfying all the appropriate axioms.
5.2 Soundness and Completeness
Given a semantics  , it is often insightful to understand which string diagrams
, it is often insightful to understand which string diagrams  and
and  are identified by
are identified by  , that is, when
, that is, when  . These equalities may inform us on the behaviour of the processes represented by string diagrams, and the differences of picking one semantics over another. First, the very existence of such a functor
. These equalities may inform us on the behaviour of the processes represented by string diagrams, and the differences of picking one semantics over another. First, the very existence of such a functor  requires that
requires that  implies
implies  ; otherwise,
; otherwise,  would not be well defined. Borrowing terminology from logic, in this case we say that
would not be well defined. Borrowing terminology from logic, in this case we say that  is sound for
is sound for  . Furthermore
. Furthermore  is said to be complete if the reverse implication holds. Compared to soundness, completeness is typically much harder to prove and often relies on identifying a ‘canonical shape’ for the morphisms of
is said to be complete if the reverse implication holds. Compared to soundness, completeness is typically much harder to prove and often relies on identifying a ‘canonical shape’ for the morphisms of  . When we have that
. When we have that 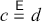 if and only if
if and only if  , we say that the theory
, we say that the theory  is sound and complete, and call it an axiomatisation of the target SMC
is sound and complete, and call it an axiomatisation of the target SMC  . In categorical terms,
. In categorical terms,  is sound and complete if
is sound and complete if  is a faithful symmetric monoidal functor. The reader will often read that a theory is ‘complete for
is a faithful symmetric monoidal functor. The reader will often read that a theory is ‘complete for  ’, rather than
’, rather than  , when the functor
, when the functor  is clear from the context. Another question that is often relevant is how expressive a diagrammatic language is. That means we may investigate which behaviours lie in the image of
is clear from the context. Another question that is often relevant is how expressive a diagrammatic language is. That means we may investigate which behaviours lie in the image of  , and whether this image may be characterised by some property. In particular, if this image is (equivalent to) the whole of
, and whether this image may be characterised by some property. In particular, if this image is (equivalent to) the whole of  , we say that
, we say that  is full.
is full.
5.3 Examples
We now cover useful examples of SMCs in which we can interpret different flavours of string diagrams. As we will see, some allow us to interpret symmetric monoidal theories with varying degrees of complexity. Some semantics have a special link with certain commonly occurring theories, in that the latter is complete for the former. In these cases, the string diagrams for a given theory capture exactly the semantics of interest.
Each time, we will use the same notation  for the semantic functor, and only specify its domain and codomain when necessary.
for the semantic functor, and only specify its domain and codomain when necessary.
Example 5.1 (Functions, ×). The category  of sets and functions can be equipped with a monoidal structure in different ways. The cartesian product of sets is one example of a monoidal product. On objects, it is simply the set of pairs, given by
of sets and functions can be equipped with a monoidal structure in different ways. The cartesian product of sets is one example of a monoidal product. On objects, it is simply the set of pairs, given by  ; on morphisms, it is given by
; on morphisms, it is given by  . The unit for the product is the singleton set
. The unit for the product is the singleton set  (any singleton set will do). It is straightforward to check that these satisfy the axioms of monoidal categories from (2.3). As an exercise, let us prove the interchange law:
(any singleton set will do). It is straightforward to check that these satisfy the axioms of monoidal categories from (2.3). As an exercise, let us prove the interchange law:
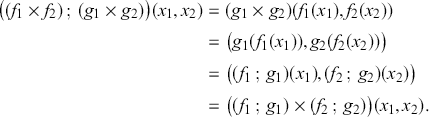
(Side note: strictly speaking, using pairs for ‘  ’ does not define an associative monoidal product, because
’ does not define an associative monoidal product, because  is not equal to
is not equal to  , but merely isomorphic to it. See Remarks 2.5 and 5.4.) Furthermore,
, but merely isomorphic to it. See Remarks 2.5 and 5.4.) Furthermore,  is a symmetric monoidal category, with symmetry given by the function
is a symmetric monoidal category, with symmetry given by the function  defined by
defined by  .
.
Since  is a symmetric monoidal category, we can use it to interpret string diagrams from a symmetric monoidal theory
is a symmetric monoidal category, we can use it to interpret string diagrams from a symmetric monoidal theory  . Formally, this amounts to defining a symmetric monoidal functor
. Formally, this amounts to defining a symmetric monoidal functor
As explained in Section 5.1, this places significant constraints on  :
:
1. Monoidal functoriality means that
for all , that the identity wire over any object is sent to the identity map over , and that the two compositions are preserved by :
2. Since
is free, to fully specify such a monoidal functor , it suffices to assign a set to each element of and a function for each operation in , such that they verify the axioms in .








 , for
, for 








We see from points 1 and 2 that the semantics of an arbitrary string diagram  can be computed from the semantics of the generating operations of
can be computed from the semantics of the generating operations of  and how they are composed together to form
and how they are composed together to form  , using (5.2).
, using (5.2).
This symmetric monoidal category also has the structure to interpret string diagrams for cartesian categories (Section 4.2.5). In fact, there is only one such structure. For an object  of a given signature, the comonoid structure
of a given signature, the comonoid structure
is given by the following copy  and discarding
and discarding  maps, defined respectively by:
maps, defined respectively by:
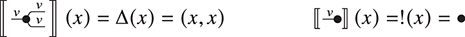
One can easily check that these satisfy the axioms of commutative comonoids (Example 2.13) and that any function satisfies the equations  and
and  from (4.5). To build a bit more intuition, let us verify
from (4.5). To build a bit more intuition, let us verify  , for example. For any
, for example. For any  , we have
, we have
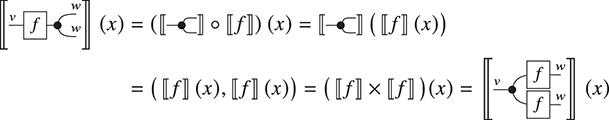
We encourage the reader to verify the other axioms as an exercise.
Note that there is only one map  for any set
for any set  , namely the discarding map
, namely the discarding map  , given by
, given by  . In conjunction with the counitality axiom of the comonoid structure, this condition forces the interpretation of the cartesian structure to be the one we have given – there are no other possible choices.
. In conjunction with the counitality axiom of the comonoid structure, this condition forces the interpretation of the cartesian structure to be the one we have given – there are no other possible choices.
Remark 5.2 (Models of algebraic theories and cartesian categories). We have seen in Remark 4.3 that there is a close syntactic correspondence between cartesian categories and algebraic theories. It is natural to wonder whether the correspondence carries over to the semantic side. This is indeed the case: symmetric monoidal functors out of the free cartesian category over a given theory into the SMC  are models (in the usual algebraic sense) of the corresponding algebraic theory. For example, to specify such a functor for the cartesian theory of monoids involves choosing a carrier set
are models (in the usual algebraic sense) of the corresponding algebraic theory. For example, to specify such a functor for the cartesian theory of monoids involves choosing a carrier set  and functions
and functions  ,
,  of the appropriate arity that satisfy the relevant axioms, which is precisely a model of the algebraic theory of monoids.
of the appropriate arity that satisfy the relevant axioms, which is precisely a model of the algebraic theory of monoids.
Example 5.3 (Relations, ×). The category  has as objects, sets, and as morphisms
has as objects, sets, and as morphisms  , binary relations, that is, subsets
, binary relations, that is, subsets  . The composition of two relations
. The composition of two relations  and
and  is defined by
is defined by  . The cartesian product
. The cartesian product  further defines a monoidal product on
further defines a monoidal product on  , with unit the singleton set
, with unit the singleton set  . Furthermore,
. Furthermore,  is symmetric monoidal, with the symmetry
is symmetric monoidal, with the symmetry  given by the relation
given by the relation  . It is easy to verify that these satisfy all the laws of symmetric monoidal categories. Even though this monoidal product is the same as in
. It is easy to verify that these satisfy all the laws of symmetric monoidal categories. Even though this monoidal product is the same as in  on objects, the properties of the two SMCs are very different.
on objects, the properties of the two SMCs are very different.
Once again, given the free symmetric monoidal category  over some theory
over some theory  , specifying a symmetric monoidal functor
, specifying a symmetric monoidal functor  means assigning a set to each element of
means assigning a set to each element of  and a relation
and a relation  for each
for each  in
in  such that the axioms of
such that the axioms of  are satisfied in
are satisfied in  . Here, monoidal functoriality, aka compositionality, means that, in particular:
. Here, monoidal functoriality, aka compositionality, means that, in particular:
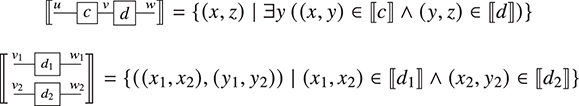
One can moreover interpret string diagrams for self-dual compact closed categories (Section 4.2.3) into  , by choosing a relation for the cups
, by choosing a relation for the cups
and caps
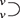
on every generating object  of our signature, such that axiom (4.1) is satisfied. Once more, there are many possible choices, but the following interpretation is a common one:
of our signature, such that axiom (4.1) is satisfied. Once more, there are many possible choices, but the following interpretation is a common one:

It is clear that these two relations satisfy the defining axiom (4.1) of (self-dual) compact closed categories.
In fact, we can go even further:  can interpret string diagrams for hypergraph categories (Section 4.2.8). For this we need to choose a special, commutative Frobenius monoid to which we map
can interpret string diagrams for hypergraph categories (Section 4.2.8). For this we need to choose a special, commutative Frobenius monoid to which we map
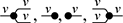
, for every generating object  of our chosen signature. There are many possibilities. One that occurs often in the literature is an extension of the comonoid structure chosen for functions in Example 5.1. We take the diagonal relation as comultiplication and the projection as counit, with the multiplication and unit given by the converse relations. Formally:
of our chosen signature. There are many possibilities. One that occurs often in the literature is an extension of the comonoid structure chosen for functions in Example 5.1. We take the diagonal relation as comultiplication and the projection as counit, with the multiplication and unit given by the converse relations. Formally:
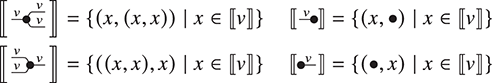
Let us check (one side of) the Frobenius law, to see how this works in more detail. In the following, all  s belong to
s belong to  for some
for some  , which we omit:
, which we omit:
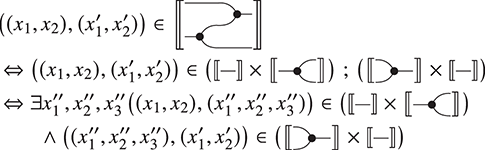
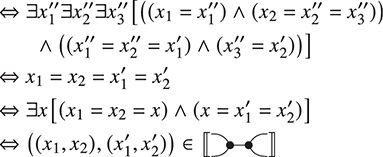
In practice, one rarely reasons this way about string diagrams for relations. There is a much more intuitive way: if we think of each wire of the diagram as being labelled by a variable, then connected networks of black nodes force all variables labelling its left and right legs to be equal. With this in mind, one may observe that any connected network of black nodes forces all the corresponding variables to be the same. This can be seen as a semantic rendition of the spider theorem (covered in Example 2.17)! The special case we have shown earlier falls out as a corollary. Functions can also be seen as relations via their graph:
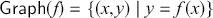
Moreover, the composite (as relations) of two functional relations is the graph of the composite of the two corresponding functions, that is, 
 . In other words,
. In other words,  defines a functor
defines a functor  . We call relations that are the graph of some function, functional.
. We call relations that are the graph of some function, functional.
Using , as above, we can interpret string diagrams for cartesian categories in  , since, as we have just seen, it contains
, since, as we have just seen, it contains  . However, not all interpretations of a signature that includes , will satisfy the axioms of cartesian categories, unlike in
. However, not all interpretations of a signature that includes , will satisfy the axioms of cartesian categories, unlike in  . In fact, in
. In fact, in  , it is possible to characterise functional relations purely by how they interact with , : they are precisely those that satisfy the
, it is possible to characterise functional relations purely by how they interact with , : they are precisely those that satisfy the  and
and  axioms in (4.5), as in the example of
axioms in (4.5), as in the example of  above. Indeed, a relation
above. Indeed, a relation  satisfies
satisfies  if and only if it is single-valued, and it satisfies
if and only if it is single-valued, and it satisfies  if and only if it is total. This is a useful characterisation that often comes up in the literature.
if and only if it is total. This is a useful characterisation that often comes up in the literature.
Finally, as we have mentioned, there are other choices of special, commutative Frobenius monoids in this SMC. The interested reader will find a full classification of all such choices in [Reference Pavlovic, Bruza, Sofge, Lawless, van Rijsbergen and Klusch96].
Remark 5.4 (Not strict?). The observant reader may have noticed an issue with the previous examples: the SMCs of functions and relations are not strict. This is because taking the cartesian product is not strictly associative, that is, the set  is not equal to the set
is not equal to the set  . However, because of the coherence theorem for SMCs (Remark 2.5) it is harmless to pretend that they are – and again, this is why we can draw string diagrams in this category. If the reader is still uncomfortable with this idea, we invite them to give an equivalent presentation of the same SMC that does not rely on taking pairs, but tuples of arbitrary length. This SMC would then be the strictification of
. However, because of the coherence theorem for SMCs (Remark 2.5) it is harmless to pretend that they are – and again, this is why we can draw string diagrams in this category. If the reader is still uncomfortable with this idea, we invite them to give an equivalent presentation of the same SMC that does not rely on taking pairs, but tuples of arbitrary length. This SMC would then be the strictification of  or
or  , and nothing of importance would be lost.
, and nothing of importance would be lost.
Similarly, we required the semantic functor  to be strict. To be fully formal, for many examples, we should allow
to be strict. To be fully formal, for many examples, we should allow  to merely be isomorphic to
to merely be isomorphic to  . However, for all intents and purposes, we can act as if
. However, for all intents and purposes, we can act as if  was strict, with codomain the strictification of the semantics we have in mind, as we do here.
was strict, with codomain the strictification of the semantics we have in mind, as we do here.
Example 5.5 (Functions, +). The cartesian product is only one among several possible choices of monoidal structures that one can impose on the category of sets and functions. In fact, we can turn it into an SMC in at least one other interesting way: instead of taking the monoidal product to be the cartesian product of sets, we consider the disjoint sum, defined as  on objects, and given by
on objects, and given by  on maps. The unit for this monoidal product is the empty set. Moreover, it is also symmetric monoidal, with symmetry
on maps. The unit for this monoidal product is the empty set. Moreover, it is also symmetric monoidal, with symmetry  given by
given by  and
and  .
.
If we can no longer interpret diagrams for cartesian categories in this SMC, we can, however, interpret those for cocartesian categories (Section 4.2.6). For each generating object  of our chosen signature, we can interpret the commutative monoid operations
of our chosen signature, we can interpret the commutative monoid operations
and
as the following maps:
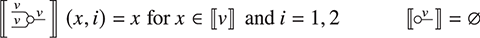
It is a straightforward exercise to check that these are associative, unital and commutative. Moreover, every map (of the appropriate type) satisfies the  and
and  axioms with respect to
axioms with respect to
and
.
Amazingly, every map between finite sets can be represented using this syntax. We only need to give ourselves a single generating object  in our signature, which we interpret as the singleton set
in our signature, which we interpret as the singleton set  . Then we simply write
. Then we simply write
and
as

and

since object labels are redundant in this context. Given a map  , for
, for  and
and  two finite sets, we first fix some ordering of
two finite sets, we first fix some ordering of  and
and  . In this way, we can identify them with finite sets of the form
. In this way, we can identify them with finite sets of the form  . This allows us to encode finite sets as sequences of wires in the diagrammatic setting (we will assume a similar encoding for several of the other examples that follow). With this encoding fixed, we can represent any map
. This allows us to encode finite sets as sequences of wires in the diagrammatic setting (we will assume a similar encoding for several of the other examples that follow). With this encoding fixed, we can represent any map  : use as many
: use as many
as necessary to connect all elements  in the domain to the single
in the domain to the single  in the codomain to which
in the codomain to which  sends them; those elements of
sends them; those elements of  that are not in the image of
that are not in the image of  are each connected to a
are each connected to a
. Here are a few examples of the translation:
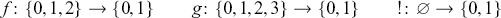

where the first is given by  , the second by
, the second by  and
and  , and the last is the unique map from the empty set to
, and the last is the unique map from the empty set to  .
.
Notice that there are several ways of drawing the same function, depending on how we choose to arrange the different
and
. The following diagrams all represent  above:
above:
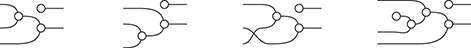
In a cocartesian category, all these diagrams are equal, as
and
form a commutative monoid. This is the first instance of a monoidal theory we encounter that fully characterises the chosen semantics: the free cocartesian category over a single object (and no morphisms) is equivalent to the SMC  of finite sets and functions, with the disjoint sum as monoidal product. In other words, the symmetric monoidal theory of a commutative monoid is complete for this semantics (in the sense explained in Section 5.2). This also means that
of finite sets and functions, with the disjoint sum as monoidal product. In other words, the symmetric monoidal theory of a commutative monoid is complete for this semantics (in the sense explained in Section 5.2). This also means that  , the free symmetric monoidal category over
, the free symmetric monoidal category over
and where  is the theory of commutative monoids (Example 2.13), is equivalent to
is the theory of commutative monoids (Example 2.13), is equivalent to  . Any two diagrams made of
. Any two diagrams made of
and
that denote the same map can be shown equal using only the axioms of commutative monoids.
The proof of this fact is typical for this kind of completeness result: it works by showing how, given an arbitrary  -diagram
-diagram  , we can rewrite it to some normal form, using only the equations of commutative monoids. The chosen normal form is one from which the corresponding relation can be recovered uniquely: we can choose, for example, to eliminate all connected to a using unitality (
, we can rewrite it to some normal form, using only the equations of commutative monoids. The chosen normal form is one from which the corresponding relation can be recovered uniquely: we can choose, for example, to eliminate all connected to a using unitality ( ) and to associate all connected to the top using associativity (
) and to associate all connected to the top using associativity ( ). Then, any two diagrams have the same normal form if and only if they are interpreted as the same map. The fact that any diagram can be rewritten to a normal form using only the preceding axioms, is typically proven by induction, considering each individual case, much like normalisation proofs in programming language theory, or cut elimination proofs in logic. Also, much like these, they tend to be quite tedious and combinatorial, so we do not reproduce them here.
). Then, any two diagrams have the same normal form if and only if they are interpreted as the same map. The fact that any diagram can be rewritten to a normal form using only the preceding axioms, is typically proven by induction, considering each individual case, much like normalisation proofs in programming language theory, or cut elimination proofs in logic. Also, much like these, they tend to be quite tedious and combinatorial, so we do not reproduce them here.
Example 5.6 (Bijections, +). If we restrict the previous example to bijections (one-to-one and onto functions), we obtain the simplest example of a SMC – call it  . String diagrams for
. String diagrams for  are simply permutations of the wires! If we restrict further to finite ordinals, the resulting SMC is equivalent to
are simply permutations of the wires! If we restrict further to finite ordinals, the resulting SMC is equivalent to  , the free SMC over the signature
, the free SMC over the signature  , the SMC of permutations we have already encountered in Example 2.7.
, the SMC of permutations we have already encountered in Example 2.7.
Example 5.7 (Relations, +). As for functions, the disjoint sum gives another interesting monoidal product on relations. On objects, it remains the same:  . On morphisms,
. On morphisms,  is given by
is given by  if and only if
if and only if  for some
for some  . Once again, the unit is the empty set and the symmetry is the graph of the corresponding function
. Once again, the unit is the empty set and the symmetry is the graph of the corresponding function  seen earlier. In this case, we cannot interpret string diagrams for compact closed nor hypergraph categories.
seen earlier. In this case, we cannot interpret string diagrams for compact closed nor hypergraph categories.
However, with the disjoint sum as monoidal product, we can interpret string diagrams for cartesian as well as cocartesian categories in  . For each generating object
. For each generating object  of a given signature, the monoid of the cocartesian structure is given by the graph of the relations that give the cocartesian structure to
of a given signature, the monoid of the cocartesian structure is given by the graph of the relations that give the cocartesian structure to  :
:
For the cartesian structure on with copying and deleting relations given by the converse of the preceding relations:
One can check that
form a commutative comonoid for any interpretation of  , and that they can copy and delete any relation, that is, that they satisfy the
, and that they can copy and delete any relation, that is, that they satisfy the  and
and  axioms from (4.5). This means that we can interpret string diagrams for biproduct categories (Section 4.2.7) in
axioms from (4.5). This means that we can interpret string diagrams for biproduct categories (Section 4.2.7) in  .
.
Intuitively, we can think of the diagrams , , , in this category as directing the flow of a single token that travels around the wires. The intuition here is that the transfers to the right wire the token that comes through any one of its left wires, is able to generate a token, is a non-deterministic fork and a dead end. As we have already said, the relations for and are simply the graphs of the functions defined in the category of sets and functions. This makes sense: functions can only direct the token deterministically from left to right. Hence, they lack the non-deterministic and .
Note that the particle intuition for diagrams in  with the disjoint sum as monoidal product is quite different from the intuition for diagrams in
with the disjoint sum as monoidal product is quite different from the intuition for diagrams in  with the cartesian product, where the variables for all wires are set to compatible values globally, all at once. For this reason, diagrams in biproduct categories are sometimes called particle-style, while those of self-dual compact closed categories are said to be wave-style. A more systematic discussion of this perspective can be found in [Reference Abramsky, Montanari and Sassone1].
with the cartesian product, where the variables for all wires are set to compatible values globally, all at once. For this reason, diagrams in biproduct categories are sometimes called particle-style, while those of self-dual compact closed categories are said to be wave-style. A more systematic discussion of this perspective can be found in [Reference Abramsky, Montanari and Sassone1].
As in the previous example, we can represent any relation between finite sets, using only the signature  , where we set
, where we set  and interpret
and interpret 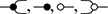 as the preceding relations. In our interpretation, a relation
as the preceding relations. In our interpretation, a relation  corresponds to a diagram
corresponds to a diagram  with
with  wires on the left and
wires on the left and  wires on the right. The
wires on the right. The  -th port on the left is connected to the
-th port on the left is connected to the  -th port on the right exactly when
-th port on the right exactly when  . For example, the relation
. For example, the relation  given by
given by  can be represented by the following diagram:
can be represented by the following diagram:

We see that this representation extends that of functions by adding the possibility of connecting one wire on the left to several (or none) on the right. This is precisely the difference between functions and relations, between determinism and non-determinism, reflected in the diagrams.
Note that a relation can also be seen as a matrix with Boolean coefficients. The relationship between the preceding string diagrams and matrices (over arbitrary semirings) will be explained in Example 5.14.
Not only do these string diagrams allow us to represent any relation between finite sets, we can also produce an axiomatisation of this SMC, that is, a sound and complete equational theory for the chosen semantics. To do this, we simply quotient  -diagrams by the axioms of an idempotent, commutative bimonoid:
-diagrams by the axioms of an idempotent, commutative bimonoid:
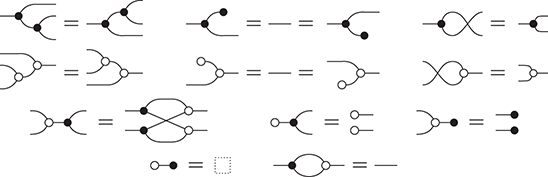
This equational theory turns out to be complete for our choice of  . In other words, any two diagrams
. In other words, any two diagrams  made from , , , are equal modulo the axioms in (5.5) if and only if
made from , , , are equal modulo the axioms in (5.5) if and only if  , that is, if and only if they denote the same relation.
, that is, if and only if they denote the same relation.
Remark 5.8. We just saw that going straight from functions to relations (with the disjoint sum as product) amounts to adding
and
to
and
. These two examples fit into a hierarchy of expressiveness, from bijections to relations:
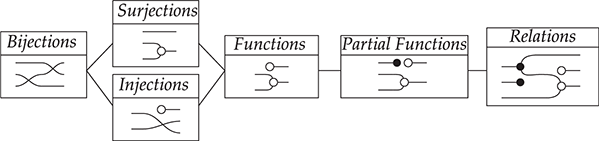
Of course, any subset of the generators
,
,
,
gives a well-defined sub-SMC of ( ,
,  ). We have not included all
). We have not included all  of them as they do not all correspond to well-known mathematical notions.
of them as they do not all correspond to well-known mathematical notions.
We should also note that the ways in which these theories are combined define distributive laws, a topic we mentioned in Remark 2.20.
Example 5.9 (Spans, ×). The category  has sets as objects and, as morphisms
has sets as objects and, as morphisms  , pairs of maps
, pairs of maps  with the same set
with the same set  as domain. We will write spans as
as domain. We will write spans as  . One way to think about spans is as witnessed or proof-relevant relations. In other words, they keep track of the way in which two elements are related: an element
. One way to think about spans is as witnessed or proof-relevant relations. In other words, they keep track of the way in which two elements are related: an element  of the apex
of the apex  can be thought of as a witness or a proof of the fact that
can be thought of as a witness or a proof of the fact that  are related by the span. Thus, the difference with relations is that there may be several ways in which two elements from
are related by the span. Thus, the difference with relations is that there may be several ways in which two elements from  and
and  are related by the same span
are related by the same span  ; if
; if  and
and  , then
, then  are related by two different witnesses
are related by two different witnesses  and
and  .
.
The composition of two spans is obtained by computing what is called the pullback of  and
and  and composing the resulting outer two functions on each side:
and composing the resulting outer two functions on each side:
where  and
and  are the two projections onto
are the two projections onto  and
and  . Thus, the composition of
. Thus, the composition of  followed by
followed by  is
is  . For a set
. For a set  , the identity span is
, the identity span is  . As given, this operation is not strictly associative or unital. To make
. As given, this operation is not strictly associative or unital. To make  into a bona fide category, we need to identify all isomorphic spans: two spans
into a bona fide category, we need to identify all isomorphic spans: two spans  and
and  are isomorphic when there is a bijection
are isomorphic when there is a bijection  such that
such that  and
and  .
.
 can be made into a symmetric monoidal category with the cartesian product of sets: on objects
can be made into a symmetric monoidal category with the cartesian product of sets: on objects  is the usual set of pairs of elements of
is the usual set of pairs of elements of  and
and  , on morphisms
, on morphisms  . With the singleton set as unit and the symmetry as
. With the singleton set as unit and the symmetry as  where
where  as before, this equips
as before, this equips  with a symmetric monoidal structure.
with a symmetric monoidal structure.
Furthermore, like relations, we can interpret string diagrams for hypergraph categories in the SMC of spans. There are many possible choices of where to map the Frobenius monoid  for a given generating object
for a given generating object  of a given signature. However, there is one evident choice, dictated by the presence of finite products:
of a given signature. However, there is one evident choice, dictated by the presence of finite products:
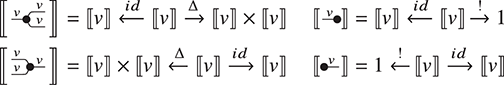
Here  is the usual diagonal map, defined by
is the usual diagonal map, defined by  , and
, and  is the unique map
is the unique map  . The proof that these satisfy the axioms of commutative Frobenius monoids can be computed much like for relations, with the added complexity that one has to keep track of the witnesses in each apex.
. The proof that these satisfy the axioms of commutative Frobenius monoids can be computed much like for relations, with the added complexity that one has to keep track of the witnesses in each apex.
Notice that if we forget the apex of each of these, and only keep track of the pairs that they relate, the resulting relations are exactly those that give  its hypergraph structure, in (5.3). This stems from a more general fact about spans and relations. If spans (of sets or any category with categorical products) of type
its hypergraph structure, in (5.3). This stems from a more general fact about spans and relations. If spans (of sets or any category with categorical products) of type  can be seen as maps
can be seen as maps  , relations are precisely injective (or monomorphic, in the general categorical setting) spans. One can always obtain a relation from a span
, relations are precisely injective (or monomorphic, in the general categorical setting) spans. One can always obtain a relation from a span  by first factorising the map into a surjective map (epimorphism) followed by an injective (monomorphism) one, and keeping only the latter. The interested reader will find the construction of
by first factorising the map into a surjective map (epimorphism) followed by an injective (monomorphism) one, and keeping only the latter. The interested reader will find the construction of  from
from  explained in more detail in [Reference Gadducci, Heckel and Presicce61; Reference Zanasi117].
explained in more detail in [Reference Gadducci, Heckel and Presicce61; Reference Zanasi117].
Example 5.10 (Spans,+). As for functions and relations, spans can also be made into a symmetric monoidal category with the disjoint sum as monoidal product. On objects, it is defined in the same way, and on spans, it is given by taking the disjoint sum of each pair of legs of the two spans.
With this monoidal product, we can use the same signature as in Example 5.7 to represent any span of finite sets. Let
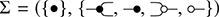
with the following slightly modified interpretation:  and (omitting the only object label)
and (omitting the only object label)
where  is defined by
is defined by  and
and  is the only map from the empty set. These also satisfy the axioms for string diagrams of biproduct categories; see Section 4.2.7. In fact, it is the free biproduct category over a single object and no additional morphism [Reference Lack84: section 5.3].
is the only map from the empty set. These also satisfy the axioms for string diagrams of biproduct categories; see Section 4.2.7. In fact, it is the free biproduct category over a single object and no additional morphism [Reference Lack84: section 5.3].
As for relations, we can use this signature to represent any span of finite sets with  as monoidal product: for the span
as monoidal product: for the span  , there is a path from the
, there is a path from the  -th wire on the left to the
-th wire on the left to the  -th one on the right in the corresponding diagram for each element of
-th one on the right in the corresponding diagram for each element of  . For example, the span
. For example, the span  , with
, with  ,
,  and
and  , can be represented by the following diagram:
, can be represented by the following diagram:
Notice that this diagram denotes the same relation as in (5.4), but the two represent different spans.
Another way to understand the correspondence is to observe that spans of finite sets can be seen as matrices with coefficients in  . Because we identify isomorphic spans, the specific label of each witness in the apex plays no role. In this sense a span just keeps track of how many ways two elements in each of its legs are related. More precisely, given the span
. Because we identify isomorphic spans, the specific label of each witness in the apex plays no role. In this sense a span just keeps track of how many ways two elements in each of its legs are related. More precisely, given the span  , we can represent it as an
, we can represent it as an  matrix whose
matrix whose  -th coefficient is the cardinality of
-th coefficient is the cardinality of  . The diagrammatic calculus for matrices will be explained in more detail in Example 5.14. This perspective is also developed in [Reference Bruni and Gadducci24], where the authors study some of the algebraic properties of the SMC of spans and their dual, cospans, which we introduce next.
. The diagrammatic calculus for matrices will be explained in more detail in Example 5.14. This perspective is also developed in [Reference Bruni and Gadducci24], where the authors study some of the algebraic properties of the SMC of spans and their dual, cospans, which we introduce next.
Example 5.11 (Cospans). Cospans, as their name indicates, are formed by inverting the arrows in the definition of spans. Let  be the category with sets as objects and morphisms
be the category with sets as objects and morphisms  given by pairs of maps
given by pairs of maps  and
and  with the same set
with the same set  as codomain, which we write as
as codomain, which we write as  . The composition of two cospans is obtained by computing what is called the pushout of
. The composition of two cospans is obtained by computing what is called the pushout of  and
and  and composing the resulting outer two functions on each side:
and composing the resulting outer two functions on each side:
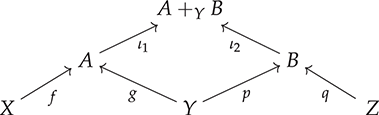
where  where
where  is the equivalence relation defined by
is the equivalence relation defined by  if and only if
if and only if  and
and  for some
for some  , and
, and  are the obvious inclusion maps of
are the obvious inclusion maps of  and
and  into
into  . Then, the composition of
. Then, the composition of  with
with  is
is  . For a set
. For a set  , the identity cospan is
, the identity cospan is  . As for spans, this operation is not strictly associative or unital. To make
. As for spans, this operation is not strictly associative or unital. To make  into a bona fide category, we need to identify all isomorphic cospans: two cospans
into a bona fide category, we need to identify all isomorphic cospans: two cospans  and
and  are isomorphic when there is a bijection
are isomorphic when there is a bijection  that makes the two resulting triangles commute.
that makes the two resulting triangles commute.
Like for spans, we can equip cospans with the structure of a SMC – this time with the disjoint sum as monoidal product. Take  to be the monoidal product on objects and, on morphisms,
to be the monoidal product on objects and, on morphisms,  where
where  ; the empty set is the unit of this monoidal product and the symmetry is given by
; the empty set is the unit of this monoidal product and the symmetry is given by  , where
, where  ,
,  are the injections into the first and second components given respectively by
are the injections into the first and second components given respectively by  and
and  .
.
Once again, we can interpret Frobenius monoids into the SMC of cospans and thus draw string diagrams for hypergraph categories. For any generating object  of a chosen signature, let
of a chosen signature, let
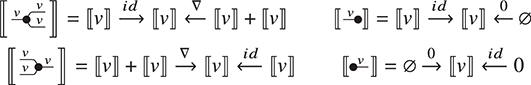
where  is defined as before by
is defined as before by  and
and  is the unique map from the empty set to
is the unique map from the empty set to  . Notice the similarity (and differences) with (5.6).
. Notice the similarity (and differences) with (5.6).
In fact, there is more than a coincidental relationship between cospans and hypergraph categories:  , the SMC of cospans restricted to finite sets, is equivalent to the free hypergraph category on a single object and no morphisms [Reference Lack84: section 5.4], that is, on the signature
, the SMC of cospans restricted to finite sets, is equivalent to the free hypergraph category on a single object and no morphisms [Reference Lack84: section 5.4], that is, on the signature  . Another way to say the same thing is that
. Another way to say the same thing is that  is equivalent to
is equivalent to  , the free SMC over the theory of a special commutative Frobenius monoid (see Example 2.18).
, the free SMC over the theory of a special commutative Frobenius monoid (see Example 2.18).
This means in particular that any cospan between finite sets (seen again as ordinals  ) can be represented as a diagram using only , , , (where we omit the single object label
) can be represented as a diagram using only , , , (where we omit the single object label  once again) and
once again) and  . To build some intuition for this correspondence, take for example the pair
. To build some intuition for this correspondence, take for example the pair  and
and  , given by
, given by  ,
,  , and
, and  ; this cospan can be depicted as:
; this cospan can be depicted as:
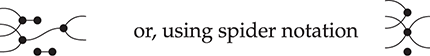
The rule of thumb is easy to formulate: each element of the apex of the cospan – here,  – corresponds to one connected network of black generators, and a boundary point is connected to a black dot if it is mapped to the corresponding apex element by (one of the legs of) the cospan. There is only one way of forming such a network from the generators modulo the axioms of special commutative Frobenius monoids, by the spider theorem, a result we saw in Example 2.17.
– corresponds to one connected network of black generators, and a boundary point is connected to a black dot if it is mapped to the corresponding apex element by (one of the legs of) the cospan. There is only one way of forming such a network from the generators modulo the axioms of special commutative Frobenius monoids, by the spider theorem, a result we saw in Example 2.17.
Completeness means that string diagrams in  are equal if and only if they denote the same cospan. The proof of this fact is essentially the spider theorem from Example 2.18. This theorem gives a normal form from which we can uniquely read the corresponding cospan: any diagram of the free hypergraph category on a single object is fully and uniquely characterised by the number of disconnected components (spiders) and to which of these each boundary point is connected. This is the same as defining a cospan!
are equal if and only if they denote the same cospan. The proof of this fact is essentially the spider theorem from Example 2.18. This theorem gives a normal form from which we can uniquely read the corresponding cospan: any diagram of the free hypergraph category on a single object is fully and uniquely characterised by the number of disconnected components (spiders) and to which of these each boundary point is connected. This is the same as defining a cospan!
Finally, many hypergraph categories can be seen as categories of cospans equipped with additional structure [Reference Fong52]. Interestingly, not all hypergraph categories can be described in this way. For that, we need the notion of corelation, which we cover in the next example.
Example 5.12 (Corelations). After seeing the last few examples, it is natural to wonder: spans are to relations as cospans are to what? The answer is equivalence relations, also known as corelations in this context [Reference Coya and Fong38]. It turns out that we can organise equivalence relations into a SMC. In fact, they can be organised into a hypergraph category.
A corelation  is an equivalence relation (i.e. a reflexive, symmetric and transitive relation) over
is an equivalence relation (i.e. a reflexive, symmetric and transitive relation) over  . Given two corelations
. Given two corelations  and
and  , their composition
, their composition  is defined by glueing together equivalence classes from
is defined by glueing together equivalence classes from  and
and  along shared elements. To define it formally, we temporarily rename
along shared elements. To define it formally, we temporarily rename  the usual composition of relations (cf. Example 5.3) and let
the usual composition of relations (cf. Example 5.3) and let  be the transitive closure of a relation
be the transitive closure of a relation  ; then
; then  is the restriction of
is the restriction of  to elements of
to elements of  . Intuitively, two elements
. Intuitively, two elements  and
and  are in the same equivalence class of
are in the same equivalence class of  if there exists some sequence of elements of
if there exists some sequence of elements of  that are equivalent either according to
that are equivalent either according to  or
or  , starting with
, starting with  and ending with
and ending with  . The disjoint sum of sets can be extended to corelations to give a monoidal product. It is moreover symmetric with symmetry given by
. The disjoint sum of sets can be extended to corelations to give a monoidal product. It is moreover symmetric with symmetry given by  . Once more, we can interpret the Frobenius monoids that define hypergraph categories in this SMC – for a generator
. Once more, we can interpret the Frobenius monoids that define hypergraph categories in this SMC – for a generator  of our signature; let
of our signature; let
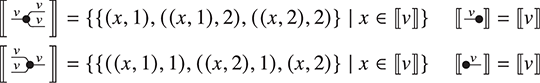
In plain English, 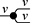 (resp. ) is mapped to the equivalence relation over
(resp. ) is mapped to the equivalence relation over  (resp.
(resp.  ) that identifies all occurrences of
) that identifies all occurrences of  in the different components of the disjoint sum.
in the different components of the disjoint sum.
As we did for cospans, it is easy to represent any corelation between finite sets as a diagram using only
,
,
,
. For example, the corelation  given by the two equivalence classes
given by the two equivalence classes  over the disjoint sum
over the disjoint sum  , can be depicted by any of the following string diagrams, using spider notation:
, can be depicted by any of the following string diagrams, using spider notation:

Observe that the first is the same diagram as in (5.8). The individual black dot, which represents an element of the apex of the cospan that was not in the image of any of the two leg maps, is missing in the second diagram. These two string diagrams represent the same corelation, since an isolated black dot represents an empty equivalence class:

. In diagrammatic terms, this means that we can always remove networks of black generators that are not connected to any boundary points, using the fact that
. However, the two string diagrams represent different cospans. This is an instance of a more general observation: at the semantic level, the only difference between corelations and cospans is that the former do not allow empty equivalence classes.
By the spider theorem, a network of black generators is fully characterised by its number of legs. Thus, there is only one such network, up to the laws of special commutative Frobenius monoids: the single dot
. Putting all of the above together with the completeness result for cospans, we can get a similar completeness result for corelations: for this, we need only add a single axiom to remove isolated dots to the theory of special commutative Frobenius monoids:
The resulting theory is known as the theory of extraspecial commutative Frobenius monoids [Reference Coya and Fong38: theorem 1.1].
Recall that relations can be seen as jointly injective spans, that is, injective maps  . Dually, corelations
. Dually, corelations  are jointly surjective cospans, that is, surjective maps
are jointly surjective cospans, that is, surjective maps  . We have already seen that, given a span
. We have already seen that, given a span  , one can extract a relation
, one can extract a relation  by factorising it into
by factorising it into  , a surjective map followed by an injective map. Similarly, one can obtain a corelation from a cospan by keeping only the surjective map in the factorisation of the corresponding map
, a surjective map followed by an injective map. Similarly, one can obtain a corelation from a cospan by keeping only the surjective map in the factorisation of the corresponding map  . As we have just seen, diagrammatically, this corresponds to removing isolated black dots. In category theory, the factorisation of
. As we have just seen, diagrammatically, this corresponds to removing isolated black dots. In category theory, the factorisation of  maps into a surjective map followed by an injective one can be abstracted into a notion called a factorisation system. It turns out that corelations can be defined for different factorisation systems than the surjective-injective one. Moreover, their apex can be decorated with additional structure. In fact, these two generalisations are so powerful that every hypergraph category can be constructed as a category of decorated corelations [Reference Fong53; Reference Fong54].
maps into a surjective map followed by an injective one can be abstracted into a notion called a factorisation system. It turns out that corelations can be defined for different factorisation systems than the surjective-injective one. Moreover, their apex can be decorated with additional structure. In fact, these two generalisations are so powerful that every hypergraph category can be constructed as a category of decorated corelations [Reference Fong53; Reference Fong54].
Example 5.13 (Linear maps, ⊗). The category fVect of finite-dimensional vector spaces (over some chosen field  ) and linear maps is also a symmetric monoidal category, in at least two different ways. This example deals with the tensor product, while the next one considers the direct product.
) and linear maps is also a symmetric monoidal category, in at least two different ways. This example deals with the tensor product, while the next one considers the direct product.
We will not go over the rigorous definition of the tensor product of vector spaces here; suffice it to say that  can be defined as a quotient of the free vector space over
can be defined as a quotient of the free vector space over  that make
that make  bilinear. On morphisms, it is uniquely specified as the linear map
bilinear. On morphisms, it is uniquely specified as the linear map  that satisfies
that satisfies  . This defines a SMC, with unit the field
. This defines a SMC, with unit the field  itself, since
itself, since  , and symmetry the map fully characterised by
, and symmetry the map fully characterised by  .
.
Crucially, this SMC is not cartesian: like in  , not all interpretations of a theory containing a commutative comonoid structure
, not all interpretations of a theory containing a commutative comonoid structure
, for each generating object of the signature, satisfy the axioms of cartesian categories ( and
and  ). The intuition here is that, when we choose an interpretation of the comultiplication operation
). The intuition here is that, when we choose an interpretation of the comultiplication operation
over  , we also choose some set of vectors
, we also choose some set of vectors  that this operation copies, that is, that verify:
that this operation copies, that is, that verify:
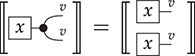
But then, given two such copyable vectors  , consider their sum
, consider their sum  – we should have
– we should have

On the other hand:
Thus, no linear map can copy all elements of a given vector space, as is required for the comonoid structure of a cartesian category.
In fact, we can interpret string diagrams for compact closed categories in (fVect,  ) (recall that the requirement of cartesian-ness and compact closed-ness are incompatible in the sense explained in Section 4). For a given generating object
) (recall that the requirement of cartesian-ness and compact closed-ness are incompatible in the sense explained in Section 4). For a given generating object  , its dual
, its dual  is interpreted as the algebraic dual of
is interpreted as the algebraic dual of  in the usual sense, that is, as
in the usual sense, that is, as  , the space of linear maps
, the space of linear maps  . Then, the cap on a vector space
. Then, the cap on a vector space  is the unique linear map
is the unique linear map  that satisfies
that satisfies
(also known as the evaluation map). The cup is its adjoint: to describe it explicitly, we need to pick a basis  of
of  and a dual basis
and a dual basis  of
of  in the sense that
in the sense that  if
if  and
and  otherwise;
otherwise;
is then the map  given by extending
given by extending  by linearity. In summary, using the bases
by linearity. In summary, using the bases  and
and  for both cups and caps, we have:
for both cups and caps, we have:
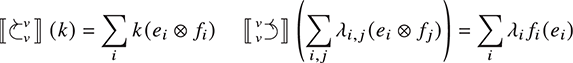
However, observe that the resulting maps are independent of the specific choice of bases. With these expressions, we can verify the yanking equation for
and
. Let  of
of  such that
such that  ; we have:
; we have:
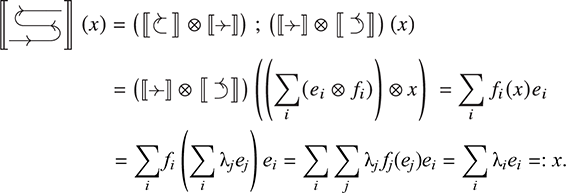
In this SMC, the elements of the vector space  are precisely the morphisms
are precisely the morphisms  .
.
As we have seen, every compact closed category is also traced. In fact, the name (partial) trace comes from linear algebra, where the trace Tr  of a linear map
of a linear map  is the sum of the diagonal coefficients of its matrix representation in any basis. Thus, we expect that,
is the sum of the diagonal coefficients of its matrix representation in any basis. Thus, we expect that,
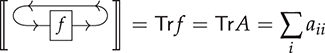
where  is the matrix that represents the action of
is the matrix that represents the action of  on some chosen basis. It is a nice exercise to show that this is indeed the case. It is then immediate to derive certain well-known properties of the trace in linear algebra, such as Tr(AB)
on some chosen basis. It is a nice exercise to show that this is indeed the case. It is then immediate to derive certain well-known properties of the trace in linear algebra, such as Tr(AB) Tr(BA) or, more generally, that it is invariant under circular shifts.
Tr(BA) or, more generally, that it is invariant under circular shifts.
Another important feature is that commutative and special Frobenius monoid in (fVect,  ) correspond to a choice of a basis for the supporting vector space [Reference Coecke, Pavlovic and Vicary36: section 6]. Even if there is no linear copying map for all the elements of a vector space, we have seen earlier that, when we choose a comultiplication operation over
) correspond to a choice of a basis for the supporting vector space [Reference Coecke, Pavlovic and Vicary36: section 6]. Even if there is no linear copying map for all the elements of a vector space, we have seen earlier that, when we choose a comultiplication operation over  we also choose some set of elements
we also choose some set of elements  that copies. Conversely, given any basis, we can define a comonoid operation that copies its elements, that is, whose comultiplication and counit are defined respectively by extending the following maps by linearity:
that copies. Conversely, given any basis, we can define a comonoid operation that copies its elements, that is, whose comultiplication and counit are defined respectively by extending the following maps by linearity:  and
and  . What about the monoid? A monoid in (fVect,
. What about the monoid? A monoid in (fVect,  ) is more commonly known as an algebra. Any basis defines not only a comonoid but an algebra given by extending the comparison map
) is more commonly known as an algebra. Any basis defines not only a comonoid but an algebra given by extending the comparison map  by linearity. Not only that, the corresponding monoid–comonoid pair satisfies the Frobenius axioms and defines a special and commutative Frobenius monoid. Conversely, the copyable states of any commutative and special Frobenius monoid form a basis of
by linearity. Not only that, the corresponding monoid–comonoid pair satisfies the Frobenius axioms and defines a special and commutative Frobenius monoid. Conversely, the copyable states of any commutative and special Frobenius monoid form a basis of  . The last direction is more difficult to prove, and we will not do so here. Instead, we refer the interested reader to the lecture notes of Vicary and Heunen, who deal with a related case in detail [Reference Heunen and Vicary73: chapter 5] and use string diagrams throughout.
. The last direction is more difficult to prove, and we will not do so here. Instead, we refer the interested reader to the lecture notes of Vicary and Heunen, who deal with a related case in detail [Reference Heunen and Vicary73: chapter 5] and use string diagrams throughout.
A historical note: one of the earliest instances of string diagrams is Penrose graphical notation [Reference Penrose101] for working with tensors, which are precisely string diagrams for (fVect,  ), later systematised and generalised in [Reference Joyal and Street77].
), later systematised and generalised in [Reference Joyal and Street77].
Example 5.14 (Matrices, ⊕). Another possible monoidal product is given by the direct sum of vector spaces  on objects and by
on objects and by  on morphisms. The unit of the product is the vector space
on morphisms. The unit of the product is the vector space  and, with the symmetry given by
and, with the symmetry given by  , the resulting structure is a SMC. It is well known that isomorphic finite-dimensional vector spaces are uniquely identified by their dimension. Therefore, in the same way that we identified finite sets with finite ordinals, we will restrict our attention to the subcategory of fVect whose objects are
, the resulting structure is a SMC. It is well known that isomorphic finite-dimensional vector spaces are uniquely identified by their dimension. Therefore, in the same way that we identified finite sets with finite ordinals, we will restrict our attention to the subcategory of fVect whose objects are  for some
for some  . We can go even further: given a linear map
. We can go even further: given a linear map  , we can identify it with its representation in the canonical bases of
, we can identify it with its representation in the canonical bases of  and
and  . We call
. We call  the category whose objects are natural numbers (representing the dimension of a vector space) and morphisms
the category whose objects are natural numbers (representing the dimension of a vector space) and morphisms  are
are  matrices (notice the reversal). Nothing is lost, since
matrices (notice the reversal). Nothing is lost, since  and fVect are equivalent.
and fVect are equivalent.
The SMC  can interpret diagrams for cartesian categories: given any object
can interpret diagrams for cartesian categories: given any object  of some signature, the canonical comonoid structure over the vector space
of some signature, the canonical comonoid structure over the vector space  is given by
is given by
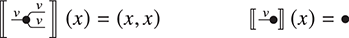
Since linear maps are maps with extra structure, this comonoid is inherited from  (see Example 5.1) and the proof that it satisfies the axioms of comonoid as well as the copying and deleting axioms
(see Example 5.1) and the proof that it satisfies the axioms of comonoid as well as the copying and deleting axioms  and
and  , is similar. We can also interpret diagrams for cocartesian categories in
, is similar. We can also interpret diagrams for cocartesian categories in  : for any object
: for any object  , the monoid structure is given by addition and zero:
, the monoid structure is given by addition and zero:
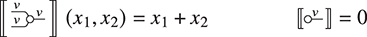
Note that the comonoid and monoid do not interact to form a Frobenius monoid but a bimonoid (see Section 2.16). In fact, we have even more structure: these string diagrams satisfy the axioms of biproduct categories (Section 4.2.7). This means that maps satisfy not only the  and
and  axioms of cartesian categories, but the dual axioms of cocartesian categories
axioms of cartesian categories, but the dual axioms of cocartesian categories  and
and  . In semantic terms, these last two axioms are simply implied by linearity: all maps preserve addition. Note that this structure is very similar to that of relations with the disjoint sum as monoidal product (see Example 5.7), the chief difference being that the bimonoid is not idempotent for matrices over a field. The close similarity between the two cases comes from the fact that relations can be seen as matrices, not over field, but over the semiring of the Booleans.
. In semantic terms, these last two axioms are simply implied by linearity: all maps preserve addition. Note that this structure is very similar to that of relations with the disjoint sum as monoidal product (see Example 5.7), the chief difference being that the bimonoid is not idempotent for matrices over a field. The close similarity between the two cases comes from the fact that relations can be seen as matrices, not over field, but over the semiring of the Booleans.
With the preceding bimonoid, we are very close to being able to express all matrices diagrammatically. As before, we will use the signature
,
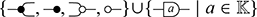
. We interpret the single generating object as  . Contrary to the case of relations, we cannot express arbitrary matrices with just
. Contrary to the case of relations, we cannot express arbitrary matrices with just
,
,
,
; this is why we have added a new generating operation
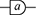
for each  , intended to represent scalar multiplication and interpreted correspondingly:
, intended to represent scalar multiplication and interpreted correspondingly:
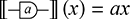
Before explaining the encoding of matrices, there are a few special cases of
that we should mention: multiplying by one is the same as the identity, so
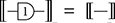
, and the result of multiplying by zero is always zero, so
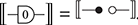
.
Putting all these ingredients together, we are now ready to represent matrices. An  matrix
matrix  corresponds to a diagram
corresponds to a diagram  with
with  wires on the left and
wires on the left and  wires on the right – the left ports can be interpreted as the columns and the right ports as the rows of
wires on the right – the left ports can be interpreted as the columns and the right ports as the rows of  . The left
. The left  -th port is connected to the
-th port is connected to the  -th port on the right through an
-th port on the right through an  -weighted wire whenever coefficient
-weighted wire whenever coefficient  is a scalar
is a scalar  . When coefficient
. When coefficient  is
is  , they are disconnected. In addition, given that
, they are disconnected. In addition, given that
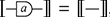
, we can simply draw the connection as a plain wire when  and since
and since
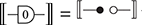
we can also omit a connecting wire when  . Conversely, given a diagram, we recover the matrix by summing weighted paths from left to right ports. For example, the matrix
. Conversely, given a diagram, we recover the matrix by summing weighted paths from left to right ports. For example, the matrix
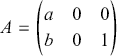 (5.14)
(5.14)
can be represented by any of the following diagrams, which are all semantically equal (i.e., represent the same matrix):
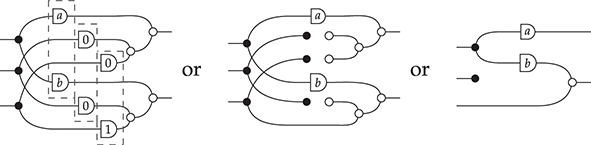
The dotted boxes in the diagram on the left represent the columns of the corresponding matrix.
Amazingly, we can then quotient the diagrammatic syntax by an equational theory that makes these three equal. More generally, we can give an axiomatisation of  . The equational theory is very similar to that of relations with the disjoint union. It has all axioms of (5.5) except the last one, namely
. The equational theory is very similar to that of relations with the disjoint union. It has all axioms of (5.5) except the last one, namely  (which encodes
(which encodes  , a specific feature of the Boolean semiring). Furthermore, we need axioms that encode the additive and multiplicative structure of
, a specific feature of the Boolean semiring). Furthermore, we need axioms that encode the additive and multiplicative structure of  , namely:
, namely:

Finally, we need to make sure that the scalars can be copied and deleted and that scalar multiplication distributes over addition; we can obtain these from the usual  -
- and
and  -
- for scalars:
for scalars:
Taken with the axioms of (5.5) minus the last one, the axioms listed in (5.11)–(5.12) give a complete theory for matrices over  : diagrams modulo these equations are equal if and only if they denote the same matrix.
: diagrams modulo these equations are equal if and only if they denote the same matrix.
Note that everything we have claimed in this example would have worked as well with an arbitrary semiring  , instead of a field: we would just need to consider matrices with coefficients in
, instead of a field: we would just need to consider matrices with coefficients in  and have generating operations for all
and have generating operations for all  . From this general result, combined with the equivalence between spans and matrices with coefficients in
. From this general result, combined with the equivalence between spans and matrices with coefficients in  , we can derive the following corollary: the free biproduct category over a single generating object (and no morphism) is an axiomatisation of the SMC
, we can derive the following corollary: the free biproduct category over a single generating object (and no morphism) is an axiomatisation of the SMC  (Example 5.10).
(Example 5.10).
Example 5.15 (Linear relations, ×). In the last two examples, we have considered linear maps with different monoidal products. It is possible to extend the notion of linearity to relations: given two vector spaces  and
and  , a linear relation
, a linear relation  is a linear subspace of
is a linear subspace of  , that is, a subset of the direct sum that is closed under linear combinations. The composition (as relations) of two linear relations is still a linear relation (exercise), and the identity relation is linear. Therefore, linear relations can be organised into a category. We call
, that is, a subset of the direct sum that is closed under linear combinations. The composition (as relations) of two linear relations is still a linear relation (exercise), and the identity relation is linear. Therefore, linear relations can be organised into a category. We call  the category whose objects are natural numbers and morphisms
the category whose objects are natural numbers and morphisms  are linear relation
are linear relation  . With the direct sum,
. With the direct sum,  becomes a SMC, with unit and symmetry the same as those of
becomes a SMC, with unit and symmetry the same as those of  (see the previous example).
(see the previous example).
This SMC has a very rich structure. Firstly, just like any function can be seen as a relation, any linear map  can be seen as a linear relation
can be seen as a linear relation  , by taking its graph:
, by taking its graph:  . Thus, we can also interpret the diagrams that allowed us to depict linear maps/matrices diagrammatically in
. Thus, we can also interpret the diagrams that allowed us to depict linear maps/matrices diagrammatically in  : taking
: taking
, where each wire represent a single generating object  , interpreted as
, interpreted as  . Their interpretation as relations is given by the graph of the corresponding maps:
. Their interpretation as relations is given by the graph of the corresponding maps:
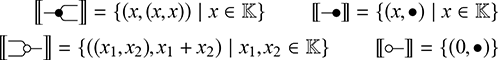
Interestingly, the converses of these relations are also linear; to depict them, we add to our signature the mirror image of the corresponding diagrams:
, with semantics given by
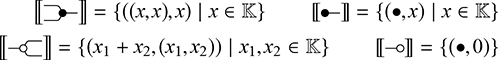
Notice that these are the same relations as the first two, with the pairs flipped. We can do this for any map  : let
: let  . If
. If  is linear, its cograph will also be a linear relation. This duality will translate into a pleasant symmetry of the equational theory, which we now cover.
is linear, its cograph will also be a linear relation. This duality will translate into a pleasant symmetry of the equational theory, which we now cover.
There is a complete axiomatisation of  with the direct sum, which is sometimes called the theory of Interacting Hopf algebras, or IH for short. The reader will find the complete theory and further details in [Reference Bonchi, Sobocinski and Zanasi22]. We discuss its most salient features in what follows, less formally.
with the direct sum, which is sometimes called the theory of Interacting Hopf algebras, or IH for short. The reader will find the complete theory and further details in [Reference Bonchi, Sobocinski and Zanasi22]. We discuss its most salient features in what follows, less formally.
As for Example 5.7, the image by  of diagrams made from
of diagrams made from
are precisely those relations that are the graph of some linear map (aka a matrix). For these, the equational theory is the same as in that example: essentially, a commutative bimonoid, with additional axioms to encode scalar multiplication and addition. The nice thing is that their colour-swap
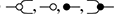
satisfy exactly the same axioms. These two facts take care of all interactions between the black and white generators. We also need to specify how diagrams of the same colour interact:
,
,
,
and
both form extraspecial commutative Frobenius monoids (Example 2.17)! The remaining axioms specify the behaviour of scalars
, which may now encounter their mirrored version:
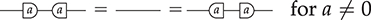
where
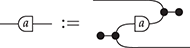
These axioms force the mirrored version of
to be division by  , which we have over any field, as long as
, which we have over any field, as long as  is non-zero. The two cups and caps are also related in an obvious way:
is non-zero. The two cups and caps are also related in an obvious way:

From these axioms, most of linear algebra can be reformulated, with subspaces and linear maps on an equal (diagrammatic) footing.
As an elementary illustration of the basic principles of diagrammatic reasoning in linear algebra, let us look at systems of linear equations. The idea is simple: a system of linear equations in the form  can be expressed by simply plugging
can be expressed by simply plugging
into the right side of a diagram that encodes the matrix  (Example 5.14), that is, by the diagram
(Example 5.14), that is, by the diagram
. For example,
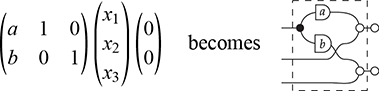
Computing a basis of the set of solutions then involves rewriting the diagram into a form from which any solution can be generated easily:
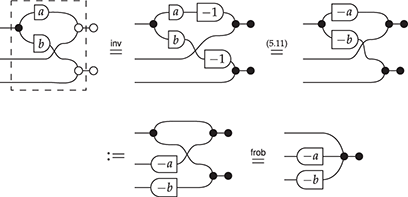
Here we find that the kernel of  has dimension
has dimension  , with basis vector, for example,
, with basis vector, for example,  .
.
Remark 5.16. If we identify the complete equational theory of a particular structure in a semantic model, we can seek it in different models, and thereby identify seemingly unrelated algebraic objects as instances of the same abstract structure. For example, we have seen many different interpretations of Frobenius monoids or bimonoids in different models (i.e. in different symmetric monoidal categories). Another common example is that of groups and Hopf algebras, both instances of bimonoids in different symmetric monoidal categories (sets and functions with the cartesian product for the former, and vector spaces and linear maps with the tensor product for the latter). Even a complicated theory such as IH occurs in other contexts than that of linear relations. Indeed, IH can be interpreted in the category of vector spaces with the tensor product as monoidal product, where its models are closely related to the notion of complementary observables in quantum physics [Reference Coecke, Duncan, Aceto, Damgärd and Goldberg34; Reference Duncan and Dunne47].
Example 5.17 (Monotone relations, ×). So far, all the examples of compact closed categories we have covered (spans, relations, cospans, corelations) also have the structure of hypergraph categories. Of course, there are compact closed categories where the compact structure does not come from some chosen Frobenius monoid. The category of monotone relations is one such example. It has pre-ordered sets as objects (that is, sets equipped with a reflexive and transitive binary relation); its morphisms  are relations
are relations  that preserve the order in the following sense: if
that preserve the order in the following sense: if  and
and  ,
,  , then
, then  . The composition of monotone relation is the same as the usual composition of relations (recalled in Example 5.3). Since the composition of two monotone relations is monotone, they form a category, with identity on each object
. The composition of monotone relation is the same as the usual composition of relations (recalled in Example 5.3). Since the composition of two monotone relations is monotone, they form a category, with identity on each object  given by the pre-order relation
given by the pre-order relation  itself.
itself.
As for plain relations, the cartesian product defines a monoidal product:  with
with  if and only if
if and only if  and
and  . The unit is still the singleton set
. The unit is still the singleton set  with the only possible pre-order.
with the only possible pre-order.
As anticipated, this category can interpret the string diagrams of compact closed categories. For this, given an object  of a given signature, we need to define its dual
of a given signature, we need to define its dual  : if
: if  , then
, then  , the same underlying set with the opposite pre-order relation
, the same underlying set with the opposite pre-order relation  . The cups and caps on each object are then given by
. The cups and caps on each object are then given by

Let us check one of the defining equations of compact closed categories:
The left-hand side of this equation has the following semantics:
where the last step holds by transitivity of  . This is clearly the same relation as
. This is clearly the same relation as  itself, which is the identity on
itself, which is the identity on  , as we wanted.
, as we wanted.
Finally, in this SMC, every partial order is equipped with an interesting monoid and comonoid structure: given the signature (
), we can interpret its generators as follows: let  and
and
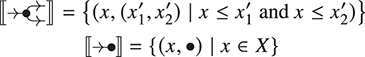
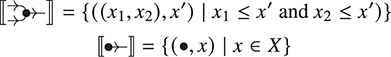
That these satisfy the monoid and comonoid axioms respectively is a simple exercise. Note that they are very similar to their standard relational cousins from Example 5.3. In fact, the former can be seen as the latter, composed with the partial order relation on each wire: for example, if we momentarily reinterpret  as a mapping into
as a mapping into  (since monotone relations are, after all, relations), we have that
(since monotone relations are, after all, relations), we have that
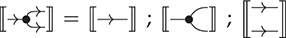
since
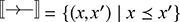
.
It should be noted that  interpreted in this way do not necessarily form a Frobenius monoid, nor do they give rise to a (co)cartesian structure. Their interaction is still interesting, and can be axiomatised, but doing so requires turning to theories with inequalities rather than just equalities. We will look at these briefly in Section 6.3 and at monotone relations again in Example 6.5.
interpreted in this way do not necessarily form a Frobenius monoid, nor do they give rise to a (co)cartesian structure. Their interaction is still interesting, and can be axiomatised, but doing so requires turning to theories with inequalities rather than just equalities. We will look at these briefly in Section 6.3 and at monotone relations again in Example 6.5.
6 Other Trends in String Diagram Theory
6.1 Rewriting
When reasoning about programs, reductions of a program  into another one
into another one  are important objects of study: such reductions may witness, for instance, the evaluation of
are important objects of study: such reductions may witness, for instance, the evaluation of  on a certain input (akin to
on a certain input (akin to  -reduction in the
-reduction in the  -calculus [Reference Barendregt8]), or more generically its transformation into a simpler program
-calculus [Reference Barendregt8]), or more generically its transformation into a simpler program  . When considering programs as terms of an algebraic theory, reductions are typically formalised as rewriting steps: we may apply a rewrite rule
. When considering programs as terms of an algebraic theory, reductions are typically formalised as rewriting steps: we may apply a rewrite rule  inside
inside  if the term
if the term  appears as a subterm of
appears as a subterm of  , in which case we say that the rule has a matching in
, in which case we say that the rule has a matching in  ; if there is such a matching, then the outcome
; if there is such a matching, then the outcome  of the rewriting step is the term
of the rewriting step is the term  obtained by replacing
obtained by replacing  for
for  in
in  .
.
When it comes to string diagrams, rewriting presents additional challenges that we do not experience with terms. The crux of the matter is matching: as string diagrams are invariant under certain topological transformations – crossing of wires, shifting of boxes, etc. – we would like matchings to exist or not regardless of which graphical presentation we choose for our string diagram. For example, consider the rule
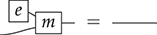
We claim the rule has a matching in the following string diagram on the left. However, strictly speaking, the matching isolates a subterm only when we ‘massage’ the string diagram as on the right:
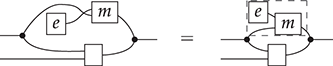
More formally, the point is that string diagrams are equivalence classes of terms, modulo the laws of SMCs. We want to be able to match a rewriting rule  on a string diagram
on a string diagram  whenever a term in the equivalence class of the string diagram
whenever a term in the equivalence class of the string diagram  appears as a subterm in the equivalence class of the string diagram
appears as a subterm in the equivalence class of the string diagram  .
.
Definition 6.1. Let  be a signature,
be a signature,  be a rewrite rule of
be a rewrite rule of  -terms, and
-terms, and  be a
be a  -term. We say that
-term. We say that  rewrites into
rewrites into  modulo
modulo  if
if  and
and
The standard case is when  are the laws of SMCs, but the notion can be adapted to fit other categorical structures where string diagrams occur, as those illustrated in Section 4. This definition seems reasonable enough from a mathematical viewpoint. However, it is completely unpractical when it comes to implementing string diagram rewriting. Exploring the space of all
are the laws of SMCs, but the notion can be adapted to fit other categorical structures where string diagrams occur, as those illustrated in Section 4. This definition seems reasonable enough from a mathematical viewpoint. However, it is completely unpractical when it comes to implementing string diagram rewriting. Exploring the space of all  -terms equivalent to a given one is an expensive computational task, and if done naively it may not even terminate given that, in principle, there are infinitely many equivalent terms to be checked for a matching. This is an issue especially because rewriting is the way we formally reason about string diagrams with a computer: whenever we want to apply the equations of a theory such as those considered in Section 2.2, the first thing to do is to orient such equations to turn them into rewrite rules.
-terms equivalent to a given one is an expensive computational task, and if done naively it may not even terminate given that, in principle, there are infinitely many equivalent terms to be checked for a matching. This is an issue especially because rewriting is the way we formally reason about string diagrams with a computer: whenever we want to apply the equations of a theory such as those considered in Section 2.2, the first thing to do is to orient such equations to turn them into rewrite rules.
The way out of this impasse comes from the combinatorial interpretation of string diagrams, introduced in Section 3. Recall that under this interpretation, equivalent  -terms are mapped to a single open hypergraph. In other words, if
-terms are mapped to a single open hypergraph. In other words, if  is mapped to
is mapped to  , and
, and  and
and  are equivalent modulo the laws of SMCs, then
are equivalent modulo the laws of SMCs, then  . This feature makes open hypergraphs suitable data structures to reason about string diagram rewriting: if we want to rewrite with a rule
. This feature makes open hypergraphs suitable data structures to reason about string diagram rewriting: if we want to rewrite with a rule  and a string diagram
and a string diagram  as just presented, we do not need to bother with the many equivalent syntactic presentations of these diagrams, but just need to consider the corresponding open hypergraphs. In fact, open hypergraphs do come with their own rewriting theory, called double-pushout rewriting [Reference Ehrig, Pfender and Jürgen Schneider50]. The fundamental result linking double-pushout rewriting and syntactic rewriting is the following:
as just presented, we do not need to bother with the many equivalent syntactic presentations of these diagrams, but just need to consider the corresponding open hypergraphs. In fact, open hypergraphs do come with their own rewriting theory, called double-pushout rewriting [Reference Ehrig, Pfender and Jürgen Schneider50]. The fundamental result linking double-pushout rewriting and syntactic rewriting is the following:
Theorem 6.2.  rewrites into
rewrites into  modulo
modulo  if and only if the open hypergraph
if and only if the open hypergraph  rewrites into
rewrites into  modulo double-pushout rewriting.
modulo double-pushout rewriting.
Example 6.3. The rule
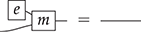
is interpreted as the span
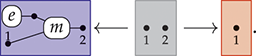
Its application in the rewrite step
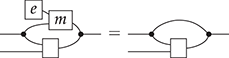
is interpreted as the double-pushout rewriting step
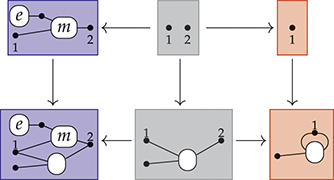
Intuitively, double-pushout rewriting matches the left-hand side of the rewrite rule to a subgraph and replaces it with the right-hand side.
Theorem 6.2 is a consequence of the correspondence established by Theorem 3.5 between string diagrams modulo Frobenius monoid and open hypergraphs. However, it is not completely satisfactory: we would like to interpret faithfully rewriting modulo the laws of SMCs, without the need of considering Frobenius equations too. It turns out it is still possible to obtain a correspondence, with a more restrictive notion of double-pushout rewriting, called convex.
Theorem 6.4.  rewrites into
rewrites into  modulo the laws of SMCs if and only if
modulo the laws of SMCs if and only if  rewrites into
rewrites into  modulo convex double-pushout rewriting.
modulo convex double-pushout rewriting.
We omit the details of the definition of convexity, which would require us to delve into the theory of double-pushout rewriting. Instead, we refer the interested reader to the overview of string diagram rewriting offered in [Reference Bonchi, Gadducci, Kissinger, Sobocinski and Zanasi14].
The preceding two theorems settle the question of rewriting for string diagrams in symmetric monoidal categories (Theorem 6.4) and hypergraph categories (Theorem 6.2). However, as we saw in Section 4, there are other structures for which we can draw string diagrams considered both of lower and higher complexity. Among the ones we have covered here, the question is not settled for monoidal, braided monoidal, traced monoidal, (self-dual) compact closed, and cartesian monoidal categories. It has been answered recently in [Reference Milosavljevic and Zanasi93] for copy-delete monoidal categories,Footnote 15 and in [Reference Ghica and Kaye67] for traced copy-delete categories. Finally, we point out the recent work [Reference Alvarez-Picallo, Ghica, Sprunger, Zanasi and Amy2], which studied rewriting for monoidal closed categories.
6.2 Higher-Dimensional Diagrams
The string diagrams we have considered so far are a particular case of a more general notation for higher categories. We highlight the connection in this section. First, we need to explain what an  -category is. Given the limited scope of our work, we will confine ourselves to a sketch, which should, however, be sufficient to grasp the link between the graphical language(s) of
-category is. Given the limited scope of our work, we will confine ourselves to a sketch, which should, however, be sufficient to grasp the link between the graphical language(s) of  -categories and string diagrams. The reader should also know that there are several competing definitions of
-categories and string diagrams. The reader should also know that there are several competing definitions of  -categories, and that our lack of precision allows us to avoid committing to any one notion.
-categories, and that our lack of precision allows us to avoid committing to any one notion.
Very roughly, an  -category is a category that may have
-category is a category that may have  -morphisms between morphisms, 3-morphisms between 2-morphisms, and so on. For example, in a 2-category there can be 2-morphisms between morphisms, indicated as follows:
-morphisms between morphisms, 3-morphisms between 2-morphisms, and so on. For example, in a 2-category there can be 2-morphisms between morphisms, indicated as follows:
Like monoidal categories, 2-categories also admit a visual representation, called surface diagrams: objects are represented as (labelled/shaded) regions of space, morphisms as (labelled) strings or wires, and 2-morphisms as (labelled) dots.
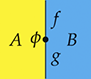
Let us see how these compose. There are two ways, just as there are two directions of composition for string diagrams: horizontally,
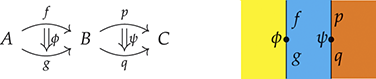
and vertically
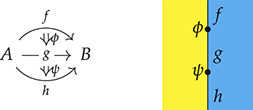
The identity (1-)morphism  can be depicted as a single-shaded region of 2D space, while the identity 2-morphism
can be depicted as a single-shaded region of 2D space, while the identity 2-morphism  can be depicted as a plain wire separating the domain and codomain objects of
can be depicted as a plain wire separating the domain and codomain objects of  :
:

For these diagrams to make sense, horizontal and vertical compositions should satisfy additional associativity and unitality requirements, much like those of (1-)categories. In addition, for the diagrams to work, horizontal and vertical composition need to interact nicely; 2-categories should also verify a form of interchange law between horizontal and vertical composition. This law says that the two ways of decomposing the following diagram are equal:
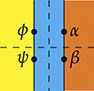
There is a surprising correspondence between certain 2-categories and monoidal categories: a monoidal category is simply a 2-category with a single object! Take the 2-morphisms to be the ordinary morphisms of the corresponding monoidal category, the 1-morphisms to be its objects, and the monoidal product to be composition of 1-morphisms. Diagrammatically, we can simply depict the single object as the (white here) background on which we draw our diagrams. In this sense, 2-categories can be thought of as typed monoidal categories (where the monoidal product cannot be applied uniformly, but has to match at the boundary 1-morphisms).
Note, however, that this correspondence is limited to monoidal categories, without any braiding or symmetry. To recover the ability to swap wires of symmetric monoidal categories a lot more structure is required. Intuitively this is because, strictly speaking, if all we have are two dimensions of ambient space, wires cannot cross – what would that even mean? Braidings can occur in at least three dimensions where it makes sense to ask the question of which wire went over or under which other wire. This is why we need to move from 2-categories to 3-or-more-categories. This may sound complicated, but just like 2-categories have morphisms between morphisms, we can define 3-categories, which have 3-morphisms between 2-morphisms, 4-categories, which have 4-morphisms between 3-morphisms, and so on. Each of these come with different ways of composing  -morphisms. As it turns out, braided or symmetric monoidal categories and their graphical languages can be recovered as special cases of degenerate 3-and 4-categories, respectively. More precisely, a braided monoidal category is a 3-category with only a single object and (1-)morphism, while a symmetric monoidal category is a 4-category with a single object, 1- and 2-morphism. These correspondences are known as the periodic table of
-morphisms. As it turns out, braided or symmetric monoidal categories and their graphical languages can be recovered as special cases of degenerate 3-and 4-categories, respectively. More precisely, a braided monoidal category is a 3-category with only a single object and (1-)morphism, while a symmetric monoidal category is a 4-category with a single object, 1- and 2-morphism. These correspondences are known as the periodic table of  -categories [Reference Baez and Dolan5].
-categories [Reference Baez and Dolan5].
One last point: the category of categories is itself a 2-category in which objects are categories, (1-)morphisms are functors, and 2-morphisms are natural transformations between them. The graphical language of 2-categories can therefore be used to present key concepts in category theory. For an excellent introduction to category theory using this diagrammatic language (and an excellent introduction to the diagrammatic language of 2-categories itself) we recommend [Reference Marsden90].
6.3 Inequalities
In the same way that we can reason equationally about string diagrams (see Section 2.1), it is also possible to reason with inequalities. From the syntactic point of view, the changes are minimal: we can define theory with inequalities in the same way that we defined equational theories (equalities are recovered as two inequalities in both directions). To interpret inequalities requires a SMC with an order between the morphisms of the semantics that is coherent with the rest of the structure (composition, monoidal product, etc.). More formally, we need a SMC in which the morphisms are partially ordered and for which the composition and monoidal product are monotone. This kind of structure appears naturally in the examples of relations that we have covered earlier, where morphisms can be ordered by inclusion: for two relations  , we write
, we write  if
if  is included in
is included in  as a subset of
as a subset of  . If we look at inequalities, some fascinating structure starts to emerge.
. If we look at inequalities, some fascinating structure starts to emerge.
Example 6.5 (Cartesian bicategories). Cartesian bicategories [Reference Aurelio and Walters.27] are SMCs in which we can assign to each object  of our chosen signature a monoid and comonoid structure, which we draw once again as
of our chosen signature a monoid and comonoid structure, which we draw once again as  and , respectively. These have to satisfy the following additional axioms:Footnote 16
and , respectively. These have to satisfy the following additional axioms:Footnote 16

The SMC of monotone relations (Example 5.17) is an example of a cartesian bicategory, with a monoid-comonoid pair given by those of (5.14)–(5.13) for each pre-ordered set  . Note however that these, as we have seen, do not form a Frobenius monoid in general. In fact, one can show that this is only the case when the underlying partial order is given by equality. In other words, the objects
. Note however that these, as we have seen, do not form a Frobenius monoid in general. In fact, one can show that this is only the case when the underlying partial order is given by equality. In other words, the objects  in the category of monotone relations for which the interpretations of and form a Frobenius monoid are just plain sets and monotone relations between them are just ordinary relations! This precisely characterises the SMC of relations within the larger SMC of monotone relations.
in the category of monotone relations for which the interpretations of and form a Frobenius monoid are just plain sets and monotone relations between them are just ordinary relations! This precisely characterises the SMC of relations within the larger SMC of monotone relations.
We can characterise other well-known structures in this SMC. For example, we can require that there exist two more generating operations on the same object  , which we write as
, which we write as
,
, and such that the duals of the inequalities (6.2) hold:
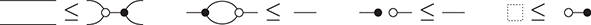
A set  equipped with this structure in the SMC of monotone relations is precisely a semi-lattice whose binary meet and top can be identified with
equipped with this structure in the SMC of monotone relations is precisely a semi-lattice whose binary meet and top can be identified with
and
respectively. To get a lattice, we need to add
satisfying the same inequalities:
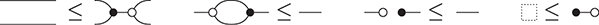
One might also wonder how
,
and
interact. For an arbitrary lattice, there is not much one can say. However, when the lattice is a Boolean algebra, they form a commutative Frobenius monoid!
6.4 Relationship with Proof Nets
Readers who have encountered proof nets before might wonder if there is a relationship with string diagrams. Given that proof nets are a graphical proof system for (multiplicative) linear logic [Reference Girard69] and that the natural categorical semantics for linear logic takes place in monoidal categories [Reference Mellies92], there should be a connection between the two. However, classical multiplicative linear logic usually requires two different monoidal products: one for the multiplicative conjunction, usually written  , and one for the multiplicative disjunction, usually written . These have non-trivial interplay, axiomatised in the notion of linearly (or weakly) distributive category [Reference Robin, Cockett and Robert33]; if we also want a classical negation, they are related via the usual DeMorgan duality, and the relevant semantics given by
, and one for the multiplicative disjunction, usually written . These have non-trivial interplay, axiomatised in the notion of linearly (or weakly) distributive category [Reference Robin, Cockett and Robert33]; if we also want a classical negation, they are related via the usual DeMorgan duality, and the relevant semantics given by  -autonomous categories [Reference Barr9].
-autonomous categories [Reference Barr9].
The problem is that our diagrams already use two dimensions: one for the composition operation and one for the monoidal product. How should we deal with two monoidal products? There are different answers. The first (though not the first one historically) is to move one dimension up, from string diagrams in two-dimensional space, to surface diagrams in three-dimensional space. This is what the authors in [Reference Dunn and Vicary49] propose.
However, if we prefer to retain the typesetting ease of a two-dimensional notation, proof nets come to the rescue. Unlike standard string diagrams (for strict SMCs that is), proof nets include explicit generators for the two monoidal productsFootnote 17

Like for compact closed categories, we also need cups and caps satisfying the usual snake equations, which the proof net literature tends to depict as undirected:
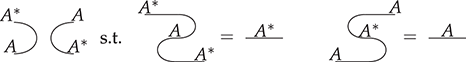
However, not all diagrams we can draw in the free SMC over these generators are proof nets, in the sense they do not necessarily denote well-formed proofs in linear logic. For example, the following diagram is not a proof net and its conclusion ( ) is not a theorem of linear logic:
) is not a theorem of linear logic:
This is why we need an additional criterion to distinguish correct proof nets among all the diagrams we are allowed to draw. There are several such criteria in the literature, under the name of correctness criteria [Reference Girard69; Reference Danos and Regnier41]. We will not cover these criteria here – the reader should just know that they usually boil down to detecting some form of acyclicity in graphs derived from the string diagram.
Proof nets can also be understood as a two-dimensional shadow of the natural three-dimensional notation used to represent both monoidal products in [Reference Dunn and Vicary49]. This projection comes at a cost: not all two-dimensional diagrams are shadows of a three-dimensional surface. Correctness criteria can therefore be seen as conditions guaranteeing that a proof net is the projection of some higher-dimensional surface diagram.
In the most degenerate cases (from the logic perspective),  , and we are left with the diagrammatic language of compact closed categories (Section 4.2.2).
, and we are left with the diagrammatic language of compact closed categories (Section 4.2.2).
6.5 Software
With the spread of diagrammatic reasoning, it is natural to wonder to what extent it may be automated, and more generally how computers can assist humans in manipulating string diagrams. There are several tools dedicated to this task, each with their specific focus and area of predilection. Here is a (non-exhaustive) list.
Cartographer [Reference Sobociński, Wilson and Zanasi108] deals with string diagrams for SMCs, the central concept of this introduction. It allows the user to specify arbitrary theories in this setting, and apply them as rewrites. String diagram rewriting is implemented as double-pushout hypergraph rewriting, following the approach of Section 6.1.
Chyp (available at https://github.com/akissinger/chyp) is an interactive proof assistant for free SMCs over some signature and equational theory. The application works both with a conventional term syntax and with string diagrams. It also supports a hole-directed rewriting of terms (in the style of Agda programming).
DisCoPy [Reference de Felice, Toumi and Coecke43] is a Python library that defines a DSL for diagrams given by either, a free monoidal category or a free SMC over some signature. Furthermore, DisCoPy allows the user to define a semantics for diagrams, that is, to define functors out of free (symmetric) monoidal categories – through these, diagrams can be evaluated to some Python programs (as linear maps, for example). Note, however, that the package does not act as a proof assistant for diagrammatic equational theories.
homotopy.io (the successor of a tool known as Globular [Reference Vicary, Kissinger and Bar110]) is a more general tool that allows the user to construct finitely generated
-categories. As a result, it is possible to encode string diagrams for SMCs into homotopy.io (using a correspondence that we have briefly covered in Section 6.2). However, the increased generality comes at the cost of significant sophistication: the user has to explicitly use the laws of SMCs in proofs, having to show the functoriality of the monoidal product by sliding two generators past each other, for example, instead of the two diagrams being equal in the internal representation.rewalt [Reference Hadzihasanovic and Kessler70] is a Python library for higher-dimensional diagrammatic rewriting in which it is possible to build presentations of higher and monoidal categories, among other applications to algebraic topology and algebra. For SMCs, this requires an encoding similar to what was needed with homotopy.io. As a bonus, rewalt can generate TikZ output to embed diagrams directly into a LaTeX document.
Quantomatic [Reference Kissinger, Zamdzhiev, Amy and Middeldorp83] is one of the earliest tools, which deals with a restricted subset of signatures (initially motivated by the ZX-calculus, see the paragraph on quantum physics in Section 7), namely signatures containing only commutative operations in compact closed categories. It allows the user to specify theories and rewriting strategies, as well as higher-order rules using so-called !-boxes.

An important theoretical question for these tools is which data structures best implement string diagrams and diagrammatic reasoning. Considering that string diagrams themselves are quotients of terms, it is a non-trivial task to represent their manipulation efficiently. This question has been explored recently in [Reference Wilson and Zanasi113; Reference Wilson and Zanasi115].
Finally, if one is exclusively interested in the typesetting of string diagrams into LaTeX documents, we mention the TikZ library, which is especially convenient when paired with TikZit (https://tikzit.github.io/), a GUI editor designed to handle PGF/TikZ pictures.
7 String Diagrams in Science: Some Applications
In the last few years, string diagrams have found application in several fields of science and engineering. This section is intended as a succinct overview of such applications, with the main aim of providing to the reader references for a more focussed study. Clearly, a survey of this type cannot possibly begin to cover all the relevant material, and it will necessarily be a partial account. Our perspective will be pedagogical rather than historical: we will typically point to the most recent surveys and introductory materials, when available. A comprehensive literature review, including a rigorous reconstruction of ‘who did what first,’ is out of our scope.
Many of the applications that we will describe share the same methodology. They involve noticing that the kind of systems and/or processes which constitute the focus of a given research area can be understood as the objects and/or morphisms of some SMC. This opens up the possibility of studying the topic from a functorial standpoint, using string diagrams as a syntax and the relevant systems and/or processes as semantics. In many cases the same approach also opens up the possibility of studying the equational properties of the resulting diagrammatic language. In some particular cases (this does not apply to all of the following examples), a universal set of generators can be found for the syntax and, if we are even luckier, the equational theory can be axiomatised by a complete monoidal theory.
It is fitting to start this section by applications of string diagrams in physics, since a notable ancestor of string diagrams is Penrose’s pictorial notation, invented to carry out the complex tensor calculations in the differential geometry of general relativity [Reference Penrose101] (see [Reference Penrose and Welsh100] for a more recent overview).
Quantum Physics
One of the most outstanding modern applications of diagrammatic reasoning has been to quantum computing. Mathematically, quantum systems are modelled as Hilbert spaces, where joining two systems is represented by taking the tensor product of the respective spaces, and processes acting on a system are linear (unitary) maps. Linear maps between Hilbert spaces with the tensor product as monoidal product form a SMC and are thus amenable to a string diagrammatic study.
There are several diagrammatic calculi to reason about linear maps between qubits (represented as vector spaces of dimension  for some natural
for some natural  ) with the tensor product represented as a monoidal product. These generalise and formalise the circuit representation that is ubiquitous in quantum computing. The first and most well-known such calculus is the ZX-calculus: its diagrams consist of nodes of two different coloursFootnote 18 called spiders, each labelled by an angle:
) with the tensor product represented as a monoidal product. These generalise and formalise the circuit representation that is ubiquitous in quantum computing. The first and most well-known such calculus is the ZX-calculus: its diagrams consist of nodes of two different coloursFootnote 18 called spiders, each labelled by an angle:

The two colours denote one of two classical observables or measurement bases: the Z (or computational) basis and X (or Hadamard) basis respectively. The angle denotes a phase relative to this basis, that is, a rotation of the Bloch sphere along the axis determined by the chosen observable.
Equationally, the spiders form a special commutative Frobenius monoid and the two colours interact with each other to form a bimonoid (more specifically, a Hopf algebra which is to a bimonoid what a group is to a monoid). Together with some other more complex equalities, the ZX-calculus completely axiomatises linear maps between qubits so that any semantic equality can be obtained by purely equational reasoning at the level of the diagrams themselves.
Because the ZX-calculus generalises quantum circuits, its axiomatisation provides a completely equational way to reason about those (see Figure 7.1). Reasoning equationally at the level of circuits is more difficult, so the ZX-calculus provides a more compositional setting in which to study the behaviour of circuits. In fact, one of its most successful applications has been to quantum circuit synthesis and simplification. Given some measure of complexity of circuits, one can compile a given circuit to its corresponding ZX diagram and simplify it using the axioms of the calculus, with the important caveat that one needs to guarantee that a bona fide circuit can be recovered at the end. (There are many technical papers on this topic; we could not find a more accessible survey, though the general introduction [Reference van de Wetering109] contains some pointers to the literature.) String diagrams have now reached the mainstream quantum computing community, as even one of the founders of the field has adopted the ZX-calculus in a recent preprint [Reference Boris Khesin, Jonathan and Shor81].
Figure 7.1 The quantum circuit on the left prepares the GHZ state  ; the ZX-calculus derivation is a diagrammatic proof of this (unlabelled spiders have
; the ZX-calculus derivation is a diagrammatic proof of this (unlabelled spiders have  phase and the square box is a Hadamard gate). See [Reference van de Wetering109: section 5] for similar examples of ZX-calculus proofs.
phase and the square box is a Hadamard gate). See [Reference van de Wetering109: section 5] for similar examples of ZX-calculus proofs.
There are other calculi with the same target semantics – linear maps between qubits – with different sets of generators as building blocks. The ZW-calculus was the first for which a completeness result was found and was instrumental in deriving a complete equational theory for the ZX-calculus (by translating one into the other). Its generators are further from the conventional gates of the classical quantum circuit model, but closely related to linear optical quantum circuits [Reference De Felice and Coecke42; Reference Poór, Wang, Shaikh, Yeh, Yeung and Coecke103]. This last reference builds a calculus that unifies both ZX- and ZW-calculus and is shown complete for arbitrary dimension. The ZH-calculus is a variation of the ZX-calculus with which it is easier to represent certain multiply controlled logic gates, like the Toffoli or AND gates (on the computational basis), and other related operations.
For a diagrammatic introduction to quantum computing and the foundations of quantum theory, the reference textbook is [Reference Coecke and Kissinger35]. Alternatively, [Reference Heunen and Vicary73] provides a complementary (and more categorically minded) approach to some of the same topics. A comprehensive survey of the ZX-calculus (and its cousins) for the working computer scientist can be found in [Reference van de Wetering109]. Beyond these, there is a wealth of recent developments that have taken the original work in different directions: a calculus which incorporates finite memory elements to the ZX-calculus [Reference Carette, De Visme and Perdrix28], several calculi for quantum linear optical circuits [Reference Clément, Heurtel, Mansfield, Perdrix, Valiron, Szeider, Ganian and Silva31, Reference De Felice and Coecke42], and more. There are also automated tools to reason about large-scale ZX diagrams: the Python library PyZX which we have already mentioned is the most recent [Reference Kissinger and van de Wetering82]. Finally, the website https://zxcalculus.com/ contains tutorials, a helpful guide to the publications in the field and even a map of ZX research community.
Signal Flow Graphs and Control Theory
Engineers and control theorists have long expressed causal flow of information between different components of a system by graphical means. One popular formalism is that of signal flow graphs, sometimes called block diagrams. They are directed graphs whose nodes represent system variables and edges functional dependencies between variables. They are used to represent networks of interconnected electronic components, amplifiers, filters, and so on. In signal flow graphs, cycles represent feedback between different parts of the system.
Giving signal flow graphs a functorial semantics required a change of perspective: instead of only allowing functional dependencies between variables, we can generalise signal flow graphs to allow relational dependencies between them, that is, arbitrary systems of (usually linear) equations. This is entirely consistent with the underlying physics, where laws tend to express relationships between variables, without any explicit assumption about the direction of causality. This change of perspective allowed the reinterpretation of the fundamental building blocks of signal flow graphs as relations, their connection as relation composition, and their juxtaposition as taking the Cartesian product of the corresponding relations. In other words, these generalised signal flow graphs are string diagrams for a sub-category of the SMC  ! One important such subcategory is that of vector spaces over a field and linear relations (see Example 5.15) between them. It turns out that signal flow graphs are intimately related to linear relations over the field of rational functions over
! One important such subcategory is that of vector spaces over a field and linear relations (see Example 5.15) between them. It turns out that signal flow graphs are intimately related to linear relations over the field of rational functions over  . The connection was established independently in [Reference Bonchi, Sobociński and Zanasi20; Reference Bonchi, Sobociński and Zanasi21] and [Reference Baez and Erbele6], where the authors also give a complete equational theory, called Interacting Hopf Algebra (IH) by the first set of authors, to reason about the behaviour of these systems entirely diagrammatically (see Figure 7.2). Since these early developments, the theory IH has been employed to reason algebraically about various tasks related to signal flow graphs: we mention the realisability of rational behaviours as circuits [Reference Bonchi, Sobociński and Zanasi20], semantic refinement [Reference Bonchi, Holland, Pavlovic, Sobociński, Meyer and Nestmann15], and a compositional criterion for controllability [Reference Fong, Sobociński and Rapisarda55]. The interested reader should note, however, that there are some subtle discrepancies between this generalisation of signal flow graphs and the standard control-theoretic interpretation of their behaviour: a more accurate, but closely related semantics in terms of bi-infinite streams is given in [Reference Fong, Sobociński and Rapisarda55], along with a complete equational theory.
. The connection was established independently in [Reference Bonchi, Sobociński and Zanasi20; Reference Bonchi, Sobociński and Zanasi21] and [Reference Baez and Erbele6], where the authors also give a complete equational theory, called Interacting Hopf Algebra (IH) by the first set of authors, to reason about the behaviour of these systems entirely diagrammatically (see Figure 7.2). Since these early developments, the theory IH has been employed to reason algebraically about various tasks related to signal flow graphs: we mention the realisability of rational behaviours as circuits [Reference Bonchi, Sobociński and Zanasi20], semantic refinement [Reference Bonchi, Holland, Pavlovic, Sobociński, Meyer and Nestmann15], and a compositional criterion for controllability [Reference Fong, Sobociński and Rapisarda55]. The interested reader should note, however, that there are some subtle discrepancies between this generalisation of signal flow graphs and the standard control-theoretic interpretation of their behaviour: a more accurate, but closely related semantics in terms of bi-infinite streams is given in [Reference Fong, Sobociński and Rapisarda55], along with a complete equational theory.
Figure 7.2 Steps of a derivation transforming the Fibonacci generating function  into a signal flow graph [Reference Bonchi, Sobociński and Zanasi21]. The
into a signal flow graph [Reference Bonchi, Sobociński and Zanasi21]. The  can be interpreted as derivation in the field
can be interpreted as derivation in the field  of rational functions or as a time delay. Note that both the specification (on the left), the signal flow graph which realises it (on the right), and the intermediate steps are all string diagrams of the same calculus, and all the steps apply laws of IH over
of rational functions or as a time delay. Note that both the specification (on the left), the signal flow graph which realises it (on the right), and the intermediate steps are all string diagrams of the same calculus, and all the steps apply laws of IH over  .
.
Finally, linear relations are not just important because of the relationship with signal flow graphs; more generally the diagrammatic calculus and the equational theory IH provide a playground in which a substantial amount of standard linear algebra can be reformulated entirely diagrammatically. The blog graphicallinearalgebra.net is a great introduction to this topic, aimed at a general audience.
Circuit Theory
String diagrams are particularly compelling where they can give an algebraic foundation to existing graphical representations that are usually treated purely combinatorially. This is the case in many existing approaches to electrical or digital circuits. Despite the existence of a standard graphical representation for circuits, the string diagrammatic approach is not without challenges: taking the original graphical representation as a starting point, one needs to decompose them into a suitable set of generators from which all other circuits can be built and, more importantly, give this syntax a functorial interpretation that assigns to each circuit its intended behaviour. In traditional introductions to electrical circuits, this last step usually appeals informally to some intuitive connection between a circuit and the set of differential equations that it specifies. String diagrams can make this connection precise and compositional (see Figure 7.3). In some particular cases, it is even possible to equip the resulting syntax with a complete equational theory that axiomatises semantic equivalence of circuits.

Figure 7.3 Deriving textbook properties of electrical circuits by compiling them to graphical linear algebra. The black diagrams represent the voltage–current pairs enforced by elements of the circuit [Reference Boisseau, Sobociński and Kishida11].
For electrical circuits with linear/affine behaviour (including resistors, inductors, capacitors, for example) this ambitious goal has not yet been achieved, though it is possible to compile them down to an intermediate representation in IH (or its affine extension) for which, as mentioned in the previous paragraph, we do have a complete diagrammatic calculus. The case of circuits with passive components is treated in [Reference Baez4] while the extension to current and voltage sources (in AC regime only) is carried out in [Reference Bonchi, Piedeleu, Sobociński and Zanasi17]. Building on this, [Reference Boisseau, Sobociński and Kishida11] develops a convenient calculus that blends both circuit elements and their compilation in IH; see Figure 7.3. The resulting language allows for entirely diagrammatic proofs of standard textbook results of electrical engineering such as the superposition theorem or Thévenin/Norton’s theorem. In this work, the ability to reason inductively on circuits as a genuine syntax proves very useful to prove these general theorems.
For digital circuits, there are many possible variants of interest to consider, each at its own level of abstraction (and each with its own limitations). The simple case of acyclic circuits consisting only of logic gates, without any memory elements, reduces to Boolean algebra and thus defines a cartesian monoidal category, which can be presented by the symmetric monoidal version of the algebraic theory of Boolean algebras, with only minor adaptations (as explained in Remark 5.2 for example) – details can be found in the pioneering [Reference Lafont85].
More complex cases, involving delays or cycles, are more delicate. Recently, the sequential synchronous (i.e. where a global clock is assumed to define the time at which signals can meaningfully change) case has found a complete axiomatisation in [Reference Ghica, Kaye and Sprunger68]. Notably, this work also allows combinational (that is, without any delay) cycles in the syntax. This feature is usually avoided in traditional treatments of digital circuits because of the difficulty of handling these types of cycles compositionally. The case of asynchronous (cyclic) circuits remains elusive and an important open problem, although some work has already been done in this direction [Reference Dan, Coecke, Ong and Panangaden66].
Probability and Statistics
Issues with the encoding of probability theory in set-theoretic measure theory have pushed researchers to develop a different, synthetic approach to probability theory. In recent years, some have sought alternative categorical foundations.
One approach studies categories of measurable spaces and Markov kernels (conditional probability measures) in an attempt to find an axiomatic setting for probability theory. This category is not only symmetric monoidal but a CD category. Moreover, in general, its morphisms satisfy only the  equation below:
equation below:

At the semantic level, this equation simply means that conditional probabilities are measures that normalise to  . Crucially, not all morphisms satisfy this
. Crucially, not all morphisms satisfy this  equation, so that categories of Markov kernels are not cartesian; those morphisms that can be copied and do satisfy
equation, so that categories of Markov kernels are not cartesian; those morphisms that can be copied and do satisfy  are precisely deterministic kernels, that is, those that, given a element of their domain, map it to a single element in their codomain with probability one. We already see that a few elementary properties of random variables can be expressed in these categories, called Markov categories; their string diagrams for Markov categories give a graphical language to treat standard properties such as conditional independence, disintegration, almost sure properties, sufficient statistics, and more. The interested reader will find [Reference Fritz57] to be a good introduction to the topic, with applications to statistics.
are precisely deterministic kernels, that is, those that, given a element of their domain, map it to a single element in their codomain with probability one. We already see that a few elementary properties of random variables can be expressed in these categories, called Markov categories; their string diagrams for Markov categories give a graphical language to treat standard properties such as conditional independence, disintegration, almost sure properties, sufficient statistics, and more. The interested reader will find [Reference Fritz57] to be a good introduction to the topic, with applications to statistics.
Much like the existing graphical methods of Bayesian networks and related representations, string diagrams make the flow of information between different variables explicit, highlighting structural properties, such as (conditional) independence. In fact, this connection was already explored in [Reference Fong51] which gave a functorial account of Bayesian networks. Around the same time, the authors of [Reference Coecke and Robert37] proposed a diagrammatic calculus for Bayesian inference. Since then, a surprising amount of probability theory has been recast in this synthetic mould: a growing list of results have been reproven in this more general setting, many of which use string diagrams to streamline proofs, including zero-one laws [Reference Fritz and Fjeldgren Rischel60], de Finetti theorem [Reference Fritz, Gonda and Perrone58], and the ergodic decomposition theorem [Reference Moss and Perrone94].
The same diagrams (in Markov or CD categories) also allow for a treatment of standard concepts in causal reasoning. In [Reference Jacobs, Kissinger and Zanasi75], the authors give a diagrammatic account of interventions and a sufficient criterion to identify when a given causal effect can be reliably estimated from observational data; see Figure 7.4. The recent [Reference Lorenz and Tull87] extends this work to counterfactuals and shows how causal inference calculations can be carried out fully diagrammatically. Beyond its pedagogical value, one advantage of the diagrammatic approach is that it is axiomatic: as such, it is not restricted to the category of Markov kernels, but applies in all categories with the relevant structure.
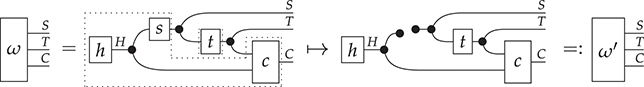
Figure 7.4 In this scenario, from [Reference Jacobs, Kissinger and Zanasi75], we seek to identify the causal effect of smoking on cancer. String diagrams represent generalised Bayesian networks, encoding causal dependencies between a set of variables. The prior is  , the joint probability distribution of smoking (variable
, the joint probability distribution of smoking (variable  ), presence of tar in the lungs (variable
), presence of tar in the lungs (variable  ), and developing cancer (variable
), and developing cancer (variable  ). A tobacco company contends that, even though there is a statistical correlation between
). A tobacco company contends that, even though there is a statistical correlation between  and
and  , there might be some confounding factor
, there might be some confounding factor  (perhaps genetic) which causes both smoking and cancer (decomposition of
(perhaps genetic) which causes both smoking and cancer (decomposition of  , on the left). How can we rule out this causal scenario, when direct intervention is impossible? We see that performing a ‘cut’ at
, on the left). How can we rule out this causal scenario, when direct intervention is impossible? We see that performing a ‘cut’ at  and replacing it with the uniform distribution, as on the right, would remove any confounding influence of
and replacing it with the uniform distribution, as on the right, would remove any confounding influence of  over
over  . In this case, we can infer from the structure of the diagram that the distribution corresponding to the resulting diagram
. In this case, we can infer from the structure of the diagram that the distribution corresponding to the resulting diagram  can be computed from observational data only. If, under
can be computed from observational data only. If, under  , a smoker is still more likely to develop cancer, then we have demonstrated that there is a causal relationship between
, a smoker is still more likely to develop cancer, then we have demonstrated that there is a causal relationship between  and
and  .
.
Machine Learning with Neural Networks
Having mentioned string diagrammatic treatments of Bayesian networks, it is natural to wonder about analogous studies of neural networks, another chief graphical model of machine learning. Categorical approaches to these structures are fairly recent and so far have mainly focussed on providing an abstract account of the gradient-based learning process [Reference H. Cruttwell, Gavranović, Ghani, Paul, Zanasi and Sergey39, Reference Fong, Spivak and Tuyéras56, Reference Gavranović63]. See, for example, [Reference Shiebler, Gavranović and Wilson107] for an overview. Use of string diagrams to describe the network structure only cursorily appears in [Reference Fong, Spivak and Tuyéras56]. String diagrams are heavily used in [Reference H. Cruttwell, Gavranović, Ghani, Paul, Zanasi and Sergey39] to represent the categorical language of lenses in the context of machine learning, but presentations by generators and equations of these diagrams are not investigated. The works on gradient-based learning with “quantised” versions of neural networks, such as Boolean circuits [Reference Wilson, Zanasi, David and Vicary112] and polynomial circuits [Reference Wilson, Zanasi, Behr and Strüber114], adopt string diagrams in a more decisive way. These works define reverse derivatives compositionally on the diagrammatic syntax for circuits, building on the theory of reverse derivative categories [Reference Cockett, Cruttwell, Gallagher, Pacaud Lemay, MacAdam, Plotkin, Pronk, Fernández and Muscholl32] and Lafont’s algebraic presentation of Boolean circuits [Reference Lafont85]. Going forward, the expectation is that such an approach may work also for real-valued networks, once the different neural network architectures are properly understood in terms of algebraic presentations. A starting point is provided in [Reference Fong, Spivak and Tuyéras56] for feedforward neural networks (see also the diagrammatic presentation of piecewise-linear relations found in [Reference Boisseau, Piedeleu, Bouyer and Schröder10], which may be used to model networks with ReLu activation units). Another important research thread concerns automatic differentiation (AD): the work [Reference Alvarez-Picallo, Ghica, Sprunger, Zanasi, Klin and Pimentel3] uses rewriting of string diagrams in monoidal closed categories to describe an algorithm for AD and prove its soundness. In this context, string diagrams are appealing as they can be reasoned about as a high-level language, while at the same time exhibiting the same information of lower-level combinatorial formalisms, which in traditional AD are introduced via compilation. Finally, we recommend the webpage [Reference Gavranović62] to the interested reader, as it maintains a list of papers at the intersection of category theory and machine learning.
Automata Theory
Automata have always been represented graphically, as state-transition graphs. However, the graphical representation is usually treated as a visual aid to convey intuition, not as a formal syntax. Kleene introduced regular expressions to give finite-state automata an algebraic syntax. Their equational theory – under the name of Kleene algebra – is now well understood and multiple complete axiomatisations have been given, for both language and relational models.
With string diagrams, however, it is possible to go directly from the operational model of automata to their equational properties, without going through a symbolic algebraic syntax [Reference Piedeleu and Zanasi102]. This approach lets us axiomatise the behaviour of automata directly, freeing us from the necessity of compressing them down to a one-dimensional notation like regular expressions. In addition, embracing the two-dimensional nature of automata guarantees a strong form of compositionality that the one-dimensional syntax of regular expressions does not have. In the string diagrammatic setting, automata may have multiple inputs and outputs and, as a result, can be decomposed into subcomponents that retain a meaningful interpretation. For example, the Kleene star can be decomposed into more elementary building blocks, which come together to form a feedback loop:
It should be noted that a similar insight was already present in the work of Ştefănescu [Reference Ştefănescu40] who studied the algebraic properties of traced monoidal categories with several additional axioms in order to capture the properties of automata, flowchart schemes, Petri nets, data-flow networks, and more.
Databases and Logic
As we have discussed earlier in several places, string diagrams are a convenient syntax for relations. They are particularly well suited to conjunctive queries, the first-order language that contains relation symbols, equality, truth, conjunction, and existential quantification. This is a core fragment of query languages for relational databases with appealing theoretical properties, such as NP-completeness (and thus, decidability) of query inclusion. Moreover, it admits a flexible diagrammatic language, which is exactly that of cartesian bicategories (Example 6.5). These were introduced in [Reference Aurelio and Walters.27] in the 1980s (without a diagrammatic syntax, most likely for typesetting reasons, though the authors give an axiomatisation that is easy to translate into string diagrams). The precise connection with conventional conjunctive query languages is worked out in [Reference Bonchi, Seeber, Sobociński, Dan and Jung18]. More recently, the authors of [Reference Haydon, Sobociński, Pietarinen, Chapman, Smet, Giardino, Corter and Linker72] have generalised these diagrams to all of (classical) predicate logic. This requires adding boxes that represent negation to the diagrams of [Reference Aurelio and Walters.27; Reference Bonchi, Seeber, Sobociński, Dan and Jung18]. Remarkably, these give a categorical account of a graphical notation for first-order logic invented by the American philosopher C. S. Peirce in a series of manuscripts [Reference Sanders Peirce99] dating as far back as the nineteenth century!
Computability Theory
Computers are machines that can be programmed to exhibit a certain behaviour. The range of behaviours that they can exhibit (its processes) can be axiomatised into a monoidal category with additional properties: we require that every process the machine can perform has a name – its corresponding program – encoding the intentional content of the process. In turn, the category contains distinguished processes, called evaluators, which run a given program on an input state of the machine. These simple requirements, with the ability to copy and delete data, are what [Reference Pavlovic97] calls a monoidal computer. This structure is sufficient to reproduce a substantial chunk of computability (and complexity) theory using string diagrams. A textbook that does just that is [Reference Pavlovic98].
Concurrency Theory
Concurrency lends itself to graphical methods, a fact noticed early by Petri. Initially, like so many other graphical representations, Petri nets were treated monolithically, and little attention was given to their composition. Once again, it is possible to take Petri nets seriously as a diagrammatic syntax with a functorial semantics. There are several ways to do so: one can either compose Petri nets along shared states (places) or shared actions (transitions). The former was developed in [Reference Baez and Master7], while the latter was initiated in [Reference Bruni, Melgratti, Connector algebras, Clarke, Virbitskaite and Voronkov25; Reference Bruni and Sobociński26]. The authors have contributed to developing this last approach further, by studying and axiomatising the algebra of Petri net transitions [Reference Bonchi, Holland, Piedeleu, Sobociński and Zanasi16]. Significantly, the syntax is the same as that of signal flow graphs (see above) – only the semantics changes, replacing real numbers (modelling signals) with natural numbers (modelling non-negative finite resources like the tokens of Petri nets). This simple change also changes the equational theory dramatically.
Linguistics
String diagrams have made a surprising appearance in formal linguistics and natural language processing. The core idea relies on a formal analogy between syntax and semantics of natural language. On the semantic side, vectors (in other words, arrays of numbers) are a convenient way of encoding statistical properties of words or features (word embeddings) extracted from large amounts of text by training machine learning models. The semantics obtained in this way is called distributional. On the syntax side, formal structures of increasing complexity have been used to study the grammatical properties of languages and explain what distinguishes a well-formed sentence from an incorrect one.
Reconciling, or rather, combining the insights of these two perspectives has been a long-standing problem. One possible approach, first proposed in [Reference Clark, Coecke, Sadrzadeh, Bruza, Lawless, Rijsbergen, Donald and Coecke30], is premised on a formal correspondence between grammatical structure and distributional semantics: both fit into monoidal categories! We have seen that vector spaces and linear maps form a SMC, with the tensor as monoidal product. Similarly, formal grammars can be recast as certain (non-symmetric) monoidal categories in which objects are parts of speech (think nouns, adjectives, transitive verbs, etc.) and morphisms derivations of well-formed sentences. The analogy allows for a functorial mapping from one to the other. With this correspondence in place, it becomes possible to interpret grammatical derivations of sentences as string diagrams in the category of vector spaces and linear maps. This gives a compositional way to build the meaning of sentences from the individual meaning of words. Moreover, certain symmetric monoidal theories can model grammatical features of language whose distributional semantics is less clear. Relative pronouns, for example, have been successfully interpreted as certain Frobenius algebras [Reference Sadrzadeh, Clark and Coecke104; Reference Sadrzadeh, Clark and Coecke105], allowing equational reasoning about the meaning of sentences that contain them. String diagrams also reveal that two a priori distinct areas of scientific enquiry can share some formal structure.
Game Theory
In classical game theory, games and their various solution concepts are usually studied monolithically. Remarkably, a compositional approach was shown to be possible in [Reference Ghani, Hedges, Winschel and Zahn64]. In this paper, the authors build games from smaller pieces, called open games. An open game is a component that chooses its next move strategically, given the state of its environment and some counterfactual reasoning about how the environment might react to its move (and what payoff it would derive from it). They form an SMC with an interesting diagrammatic syntax which contains forward and backward flowing wires (the latter represent this counterfactual reasoning, flowing from future to present). In fact, these diagrams are related to those for lenses, which we have encountered in the paragraph on machine learning. Closed diagrams represent classical games, whose semantics is given by the appropriate equilibrium condition. Initially developed only for standard games with pure Nash equilibria as solution concept, open games have been extended to more general settings, such as Bayesian games [Reference Bolt, Hedges and Zahn12] with the appropriate solution concept.
Appendix Category Theory: The Bare Minimum
In this appendix, we recall the most basic notions of category theory: category, functor, natural transformation, adjunctions. This very brief recap is intended as reference material for some of the explanations provided in the main text. For a more pedagogical treatment, the reader should turn to an introductory textbook on the topic, such as [Reference Leinster86].
Definition A.1. A category  consists of
consists of
a collection of objects;
a collection of morphisms such that every morphism
of has a unique object called its domain, and a unique object called its codomain, which we then write ;for every pair of morphisms
and , a morphism which we call the composition of and ;for every object
, a morphism which we call the identity on ;such that
1. composition is associative, that is,
2. identities are the (two-sided) unit for composition, that is,















Remark A.2. The order of composition in the preceding definition is chosen to adhere to the diagrammatic order of composition, from left to right. It is common to see the reverse-order operation,  , in particular when dealing with maps between sets.
, in particular when dealing with maps between sets.
Remark A.3. In the main text, the first categorical structure in which we consider string diagrams are (symmetric) monoidal categories (Definition 2.6). However, plain categories already accommodate a representation of their morphisms as string diagrams, albeit of a simpler kind. Just as in the monoidal case, one may use wires to depict (the identity on) each object, and boxes for each morphism:

Sequential composition of boxes with matching wires in the middle is the only allowed operation:
The diagrammatic notation has the benefit of absorbing the associativity and unitality laws of Definition A.1:
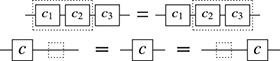
The appropriate notion of structure-preserving mapping between categories is called a functor.
Definition A.4. Given two categories  and
and  , a functor
, a functor  is a map from the objects of
is a map from the objects of  to those of
to those of  , and a map from the morphisms of
, and a map from the morphisms of  to those of
to those of  that preserves composition and identities, that is,
that preserves composition and identities, that is,
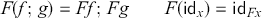
Clearly, functors can also be composed like ordinary maps. With functors as morphisms, categories themselves form a category. A functor is called faithful if it is injective on morphisms of the same type, that is, if  implies that
implies that  ; it is full if it is surjective on morphisms of the same type, that is, for any
; it is full if it is surjective on morphisms of the same type, that is, for any  in
in  , there exists
, there exists  in
in  such that
such that  .
.
There is also a notion of mapping between functors, which we now recall.
Definition A.5. Given two functors  and
and  , a natural transformation
, a natural transformation  is a family of morphisms
is a family of morphisms  indexed by the objects of
indexed by the objects of  , such that
, such that  for every morphism
for every morphism  .
.
Remark A.6. Functors can also be represented pictorially, via functorial boxes mellies2006functorial. Plainly, for a functor  , they are
, they are  -labelled boxes that frame diagrams
-labelled boxes that frame diagrams
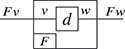
Diagrams inside the box live in category  , and those outside in
, and those outside in  . To represent functors, functorial boxes have to be functorial! This means that they satisfy the following equality:
. To represent functors, functorial boxes have to be functorial! This means that they satisfy the following equality:

This is easily seen to be the translation of the first equality in Definition A.4. Note that the preservation of identities required by Definition A.4 is already a diagrammatic tautology, as it is absorbed by the diagrammatic notation.
We do not cover these here in detail, though we refer to their use in representing diagrams for closed monoidal categories, in Section 4.2.9.
Recall that an isomorphism is a morphism  which has an inverse: a morphism
which has an inverse: a morphism  such that
such that  and
and  . We then say that
. We then say that  is isomorphic to
is isomorphic to  . The notion of isomorphism makes sense for functors and categories too. The inverse of a functor
. The notion of isomorphism makes sense for functors and categories too. The inverse of a functor  is a functor
is a functor  such that
such that  and
and  . However, it is sometimes too restrictive to ask for isomorphisms between categories. Indeed, there are categories that we would like to identify, which are not isomorphic. The more general notion of equivalence of categories is often more appropriate.
. However, it is sometimes too restrictive to ask for isomorphisms between categories. Indeed, there are categories that we would like to identify, which are not isomorphic. The more general notion of equivalence of categories is often more appropriate.
Definition A.7. A functor  is an equivalence of categories if there exists a functor
is an equivalence of categories if there exists a functor  and two natural transformations
and two natural transformations  and
and  whose components are isomorphisms.
whose components are isomorphisms.
Remark A.8. In this Element, we make use of monoidal equivalences of monoidal categories. The definition is the obvious modification of Definition A.7: it is a monoidal functor  (see Definition 2.8) for which there exists a monoidal functor
(see Definition 2.8) for which there exists a monoidal functor  satisfying the conditions of the preceding definition. The same goes for symmetric monoidal categories.
satisfying the conditions of the preceding definition. The same goes for symmetric monoidal categories.
We can even weaken further the notion of equivalence to that of adjunction. Instead of requiring equalities  and
and  , we can consider functors for which we have natural transformations
, we can consider functors for which we have natural transformations  and
and  that satisfy some conditions that we now recall.
that satisfy some conditions that we now recall.
Definition A.9. An adjunction between two categories consists of a pair of functors  and
and  and two natural transformations
and two natural transformations  (the unit) and
(the unit) and  (the counit) such that
(the counit) such that
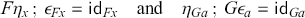
We call  the left adjoint and
the left adjoint and  the right adjoint.
the right adjoint.
Acknowledgements
Funding from University College London made it possible for this book to be published open access, making the digital version freely available for anyone to read and reuse under a Creative Commons licence.
Bob Coecke
Cambridge Quantum Ltd
Bob Coecke is Chief Scientist at Cambridge Quantum Ltd. and Emeritus Professor at Wolfson College, University of Oxford. His pioneering research includes categorical quantum mechanics, ZX-calculus, quantum causality, resource theories, and quantum natural language processing. Other interests include cognitive architectures and diagrams in education. Most of his work uses the language of tensor categories and their diagrammatic representations. He co-authored the book Picturing Quantum Processes. A First Course in Quantum Theory and Diagrammatic Reasoning. He is considered as one of the fathers of the field of applied category theory, and a co-founder of the journal Compositionality.
Joshua Tan
University of Oxford
Joshua Tan is a doctoral student at the University of Oxford and a Practitioner Fellow at Stanford University. He is the executive director of the Metagovernance Project and an executive editor of the journal Compositionality. He works on applications of category theory and sheaf theory to theoretical machine learning and to the design of complex, multi-agent systems.
About the Series
Elements in Applied Category Theory features Elements intended both for mathematicians familiar with category theory and seeking elegant, graduate-level introductions to other fields in the language of categories, and for subject-matter experts outside of pure mathematics interested in applications of category theory to their field.




















































 Open access
Open access