



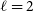
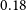
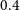
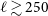
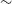

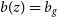
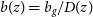
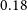
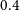
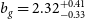
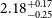
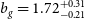
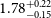
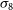
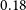
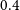
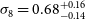
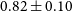
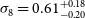
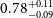
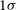
1. Introduction
A primary goal of large-scale structure experiments probing the late Universe is to provide answers on the history of the growth of cosmic structures and also discover the nature of the unknown components that dominate in the universe leading it to its recent accelerated expansion (e.g. Huterer Reference Huterer2023). To achieve this, the tracers we choose should be able, on one hand, to cover a large patch of the observed sky, accessing this way both large and small cosmological scales and, on the other hand, to be deep enough so that we can reconstruct the growth of structure history as a function of time. However, these probes alone, are not able to address these aspects simultaneously. For instance, probes like weak gravitational lensing on galaxies, which is the effect of the distortions of galaxy shapes caused by the underlying matter field between us and the galaxies, or on the cosmic microwave background (CMB) (Bartelmann & Schneider Reference Bartelmann and Schneider2001), is an unbiased tracer of the matter field in the Universe. Nonetheless, it provides poor information on the redshift evolution of the galaxies and also has lower statistical power compared to the other large-scale structure probe, called galaxy clustering. This probe, though, is a biased tracer of the total matter field and the modelling needed to connect the two has been proven to be quite complex (Kaiser Reference Kaiser1987; Sánchez et al. Reference Sánchez2016; Abbott et al. Reference Abbott2018; Desjacques, Jeong, & Schmidt Reference Desjacques, Jeong and Schmidt2018). One way to overcome this and reconstruct the growth of structures, is to use redshift-space distortions in case there are accurate redshift estimates which are obtained spectroscopically (Guzzo et al. Reference Guzzo2008; Blake et al. Reference Blake2013; Howlett et al. Reference Howlett, Ross, Samushia, Percival and Manera2015; Pezzotta et al. Reference Pezzotta2017; Alam et al. Reference Alam2021). Another way to overcome the limitations from the individual experiments, is to combine weak lensing and galaxy clustering data measurements (Hu Reference Hu2002; de la Torre et al. Reference de la Torre2017; Peacock & Bilicki Reference Peacock and Bilicki2018; Wilson & White Reference Wilson and White2019; Heymans et al. 2021; White et al. Reference White2022; García-García et al. Reference García-García, Ruiz-Zapatero, Alonso, Bellini, Ferreira, Mueller, Nicola and Ruiz-Lapuente2021; Alonso et al. Reference Alonso, Fabbian, Storey-Fisher, Eilers, García-García, Hogg and Rix2023). In addition, this multi-tracing increases the statistical power by accessing as much information as possible in the different cosmological scales as well as in redshift.
In this framework, there has been a growing interest in deep radio continuum galaxy surveys. These surveys have the ability to scan enormous patches of the sky thanks to the large field of view of modern radio interferometers operating at low frequencies. There has been a variety of forecasting analyses in the literature arguing for their cosmological potential using the Square Kilometer Array (hereafter SKAO Raccanelli et al. Reference Raccanelli2012; Jarvis et al. Reference Jarvis, Bacon, Blake, Brown, Lindsay, Raccanelli, Santos and Schwarz2015; Maartens et al. Reference Maartens, Abdalla, Jarvis and Santos2015; Bacon et al. Reference Bacon2020) and also the benefit reaped when different radio populations are combined in a multi-tracer approach. In particular, several ultra-large scale effects can be detected with multi-tracing such as relativistic effects and the primordial non-Gaussianity (Ferramacho et al. Reference Ferramacho, Santos, Jarvis and Camera2014; Alonso et al. Reference Alonso, Bull, Ferreira, Maartens and Santos2015; Fonseca et al. Reference Fonseca, Camera, Santos and Maartens2015; Bengaly et al. Reference Bengaly, Maartens, Randriamiarinarivo and Baloyi2019; Gomes et al. Reference Gomes, Camera, Jarvis, Hale and Fonseca2019).
When observing the universe at frequencies between 0.1–10 GHz, wavelengths larger than those in optical and infrared, the main radio continuum emission mechanism is synchrotron radiationFootnote
a
(e.g. Condon Reference Condon1992). This is caused by relativistic electrons as they spiral in the magnetic fields. For this reason, the dominant populations of the radio galaxies are active galactic nuclei (hereafter AGNs), and star forming galaxies (hereafter SFGs). Regarding AGNs, there is a variety in the origin of sources as well as in their classifications. This includes the accretion mechanism of infalling material into central supermassive black holes (e.g. Best & Heckman Reference Best and Heckman2012; Heckman & Best Reference Heckman and Best2014), AGN orientation with respect to the observer (Antonucci Reference Antonucci1993; Urry & Padovani Reference Urry and Padovani1995) and also their morphology (e.g. Type I & II, Fanaroff & Riley Reference Fanaroff and Riley1974). As for SFGs, these are mainly spiral galaxies and they fall into two main categories. First is starburst galaxies, in which intensive star formation is present (star formation rate
 $\gtrsim 100 \text{ M}_\odot \text{yr}^{-1}$
). The other category is normal star forming galaxies (star formation rate
$\gtrsim 100 \text{ M}_\odot \text{yr}^{-1}$
). The other category is normal star forming galaxies (star formation rate
 $\lesssim 100 \text{ M}_\odot \text{yr}^{-1}$
) (e.g. Wynn-Williams Reference Wynn-Williams and Persson1986). One of the main advantages of observations at these frequencies is that dust contamination is negligible in the line-of-sight direction as well as in the intergalactic medium due to the long wavelengths at radio frequencies. This is especially relevant for SFG studies where their radio emission is an unbiased probe of the star formation rate (e.g. Bell Reference Bell2003; Davies et al. Reference Davies2016; Gürkan et al. Reference Gürkan2018).
$\lesssim 100 \text{ M}_\odot \text{yr}^{-1}$
) (e.g. Wynn-Williams Reference Wynn-Williams and Persson1986). One of the main advantages of observations at these frequencies is that dust contamination is negligible in the line-of-sight direction as well as in the intergalactic medium due to the long wavelengths at radio frequencies. This is especially relevant for SFG studies where their radio emission is an unbiased probe of the star formation rate (e.g. Bell Reference Bell2003; Davies et al. Reference Davies2016; Gürkan et al. Reference Gürkan2018).
There have been a number of past large-area radio continuum experiments like the NRAO VLA Sky Survey (NVSS at 1.4 GHz, Condon et al. Reference Condon, Cotton, Greisen, Yin, Perley, Taylor and Broderick1998; Hotan et al. Reference Hotan2021), the TIFR GMRT Sky Survey (TGSS-ADR at 150 MHz, Intema et al. Reference Intema, Jagannathan, Mooley and Frail2017) and the Sydney University Monongolo Sky Survey (SUMSS, Mauch et al. Reference Mauch, Murphy, Buttery, Curran, Hunstead, Piestrzynski, Robertson and Sadler2003). However, the current generation of radio surveys like the Australian Square Kilometre Array Pathfinder (hereafter ASKAP, Johnston et al. Reference Johnston2007), the Meer Karoo Array Telescope (hereafter MeerKAT, Jonas Reference Jonas2009) and the Low Frequency ARray (hereafter LOFAR, van Haarlem et al. Reference van Haarlem2013), all of them precursors of SKAO, make an advance through much deeper observations together with the large sky coverage. In particular, ASKAP has a field of view of
 $\sim 30 \text{ deg}^2$
operating at 700–1 800 MHz thanks to its phased array feeds. LOFAR, similarly, has a field of view of
$\sim 30 \text{ deg}^2$
operating at 700–1 800 MHz thanks to its phased array feeds. LOFAR, similarly, has a field of view of
 $\sim 30 \text{ deg}^2$
at 150 MHz, while MeerKAT has a field of view of
$\sim 30 \text{ deg}^2$
at 150 MHz, while MeerKAT has a field of view of
 $\sim 1 \text{ deg}^2$
at 1.2 GHz. With these large fields of view achieved with radio interferometers, large and contiguous patches of the sky can be observed, accessing in this way large-scale structure information at very large scales (angular separations).
$\sim 1 \text{ deg}^2$
at 1.2 GHz. With these large fields of view achieved with radio interferometers, large and contiguous patches of the sky can be observed, accessing in this way large-scale structure information at very large scales (angular separations).
In this work we use the Pilot Survey 1 of the Evolutionary Map of the Universe (hereafter EMU PS1, Norris et al. Reference Norris2011, Reference Norris2021) which uses ASKAP at 944 MHz, covering a contiguous patch of
 $\sim 270 \text{ deg}^2$
at a depth of 25–30
$\sim 270 \text{ deg}^2$
at a depth of 25–30
 $\unicode{x03BC} \text{Jy/beam rms (root mean square)}$
and with a spatial resolution of 11–18 arcsec. By the end of its operation, EMU will cover the whole of the southern sky.
$\unicode{x03BC} \text{Jy/beam rms (root mean square)}$
and with a spatial resolution of 11–18 arcsec. By the end of its operation, EMU will cover the whole of the southern sky.
As already mentioned, the radio continuum emission mechanism is synchrotron radiation, whose spectrum typically lacks strong emission or absorption lines which renders redshift measurements impossible.Footnote b This results in large uncertainties on the redshift distribution of the galaxy sample and its properties, like the mass of host halos and galaxy bias. To shed light on radio sources’ clustering properties, one solution is to cross-match with optical sources (e.g. Lindsay et al. Reference Lindsay2014; Hale et al. Reference Hale, Jarvis, Delvecchio, Hatfield, Novak, Smolčić and Zamorani2017; Mazumder, Chakraborty, & Datta Reference Mazumder, Chakraborty and Datta2022).
Radio continuum sources overlap in redshift with the CMB lensing convergence field. This probe is sensitive to inhomogeneities of the matter distribution at high redshifts (peaking at
 $z\sim2$
) and at comparable large volumes, making it ideal for cross-correlations with radio galaxies (e.g. Planck Collaboration et al. 2014; Allison et al. Reference Allison2015) and also in the context of de-lensing studies (Namikawa et al. Reference Namikawa, Yamauchi, Sherwin and Nagata2016). Previous works on cross-correlation of radio galaxies with CMB lensing include Smith et al. (Reference Smith, Zahn and Doré2007), where this combination was used to make the first CMB lensing detection and also Allison et al. (Reference Allison2015) and Piccirilli et al. (2023) to infer the galaxy bias of radio galaxies. Furthermore, the first and second data releases of the LOFAR Two-metre Sky Survey (LoTSS; Shimwell et al. Reference Shimwell2019, Reference Shimwell2022) radio catalogues were cross-correlated with CMB lensing from the Planck satellite (Planck Collaboration et al. 2020a), in order to constrain the redshift distribution and the galaxy bias of the sample (Alonso et al. Reference Alonso, Bellini, Hale, Jarvis and Schwarz2021; Nakoneczny et al. 2024). These works have also shown that this cross-correlation can lift the degeneracy between the galaxy bias and the amplitude of the matter fluctuations. Here, we explore the auto-correlation and the cross-correlation of EMU PS1 with the latest CMB lensing convergence data (PR4) from Planck (Carron, Mirmelstein, & Lewis Reference Carron, Mirmelstein and Lewis2022) to place constraints on the galaxy bias of the sample and on the matter fluctuations amplitude and leave the redshift distribution parameterisation of radio sources with the help of optical surveys for a future work.
$z\sim2$
) and at comparable large volumes, making it ideal for cross-correlations with radio galaxies (e.g. Planck Collaboration et al. 2014; Allison et al. Reference Allison2015) and also in the context of de-lensing studies (Namikawa et al. Reference Namikawa, Yamauchi, Sherwin and Nagata2016). Previous works on cross-correlation of radio galaxies with CMB lensing include Smith et al. (Reference Smith, Zahn and Doré2007), where this combination was used to make the first CMB lensing detection and also Allison et al. (Reference Allison2015) and Piccirilli et al. (2023) to infer the galaxy bias of radio galaxies. Furthermore, the first and second data releases of the LOFAR Two-metre Sky Survey (LoTSS; Shimwell et al. Reference Shimwell2019, Reference Shimwell2022) radio catalogues were cross-correlated with CMB lensing from the Planck satellite (Planck Collaboration et al. 2020a), in order to constrain the redshift distribution and the galaxy bias of the sample (Alonso et al. Reference Alonso, Bellini, Hale, Jarvis and Schwarz2021; Nakoneczny et al. 2024). These works have also shown that this cross-correlation can lift the degeneracy between the galaxy bias and the amplitude of the matter fluctuations. Here, we explore the auto-correlation and the cross-correlation of EMU PS1 with the latest CMB lensing convergence data (PR4) from Planck (Carron, Mirmelstein, & Lewis Reference Carron, Mirmelstein and Lewis2022) to place constraints on the galaxy bias of the sample and on the matter fluctuations amplitude and leave the redshift distribution parameterisation of radio sources with the help of optical surveys for a future work.
The paper is structured as follows: In Section 2, we describe the theoretical observables we use in our modelling. Then, in Section 3, we present the data we use in our analysis. In Section 4, we introduce the method used to construct the auto-correlation and cross-correlation measurements from the data, and also discuss the models and the error estimates we assume for our statistical analysis. The main results concerning the detection significance and the constraints on the galaxy bias and cosmology are shown in Section 5. Finally, we discuss our conclusions in Section 6.
2. Theory
The harmonic-space power spectrum signal
 $S_{\ell}^{XY}$
between the projected quantities X and Y, can be defined as
$S_{\ell}^{XY}$
between the projected quantities X and Y, can be defined as
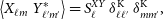 \begin{equation} \left\langle X_{\ell m}\,Y^\ast_{\ell^{\prime} m^{\prime}}\right\rangle=S^{XY}_\ell\,\delta^{\textrm{K}}_{\ell\ell^{\prime}}\,\delta^{\textrm{K}}_{m m^{\prime}},\end{equation}
\begin{equation} \left\langle X_{\ell m}\,Y^\ast_{\ell^{\prime} m^{\prime}}\right\rangle=S^{XY}_\ell\,\delta^{\textrm{K}}_{\ell\ell^{\prime}}\,\delta^{\textrm{K}}_{m m^{\prime}},\end{equation}
where
 $X_{\ell m}$
and
$X_{\ell m}$
and
 $Y_{\ell m}$
denote the coefficients of the harmonic expansion for the statistically isotropic fields of interest X and Y, while
$Y_{\ell m}$
denote the coefficients of the harmonic expansion for the statistically isotropic fields of interest X and Y, while
 $\delta^{\textrm{K}}$
is the Kronecker symbol. In this work we focus on the fluctuations of the galaxy number counts
$\delta^{\textrm{K}}$
is the Kronecker symbol. In this work we focus on the fluctuations of the galaxy number counts
 $\delta_g$
and the convergence field
$\delta_g$
and the convergence field
 $\kappa$
. Both are later discussed in detail in Sections 2.1 and 2.2, respectively.
$\kappa$
. Both are later discussed in detail in Sections 2.1 and 2.2, respectively.
For broad redshift distributions, as is the case in radio continuum surveys (e.g. Tanidis et al. Reference Tanidis, Camera and Parkinson2019), the harmonic-space power spectrum between the two quantities X and Y can be written in the Limber approximation (Limber Reference Limber1953; Kaiser Reference Kaiser1992) as
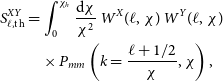 \begin{align}S^{XY}_{\ell, \text{th}} &=\int_0^{\chi_h} \frac{\text{d} \chi}{\chi^2}\, W^X(\ell,\chi)\,W^Y(\ell, \chi)\,\notag \\ &\quad\times P_{mm}\left(k=\frac{\ell+1/2}{\chi},\chi\right),\end{align}
\begin{align}S^{XY}_{\ell, \text{th}} &=\int_0^{\chi_h} \frac{\text{d} \chi}{\chi^2}\, W^X(\ell,\chi)\,W^Y(\ell, \chi)\,\notag \\ &\quad\times P_{mm}\left(k=\frac{\ell+1/2}{\chi},\chi\right),\end{align}
where
 $\chi(z)$
is the comoving distance at a given redshift z for flat cosmologies,
$\chi(z)$
is the comoving distance at a given redshift z for flat cosmologies,
 $\chi_h$
the co-moving distance at the horizon,
$\chi_h$
the co-moving distance at the horizon,
 $P_{mm}$
is the matter power spectrum and
$P_{mm}$
is the matter power spectrum and
 $k=|\vec k|$
with
$k=|\vec k|$
with
 $\vec k$
the wave vector. We use the notation
$\vec k$
the wave vector. We use the notation
 $S_{\text{th}}$
for the model harmonic-space spectrum to distinguish it from S which is the measured harmonic-space spectrum signal from definition in Equation (1). The general redshift and scale-dependent kernel
$S_{\text{th}}$
for the model harmonic-space spectrum to distinguish it from S which is the measured harmonic-space spectrum signal from definition in Equation (1). The general redshift and scale-dependent kernel
 $W^X(\ell,\chi)$
can take different expressions depending on the desired observable. These observables are described in Sections 2.1 and 2.2.
$W^X(\ell,\chi)$
can take different expressions depending on the desired observable. These observables are described in Sections 2.1 and 2.2.
2.1. Galaxy clustering
Galaxies are well-known biased tracers of the dark matter field (Kaiser Reference Kaiser1987). In general, this bias can be considered to be redshift and scale dependent. Assuming Gaussian initial curvature perturbations, this scale dependence is especially relevant at non-linear scales, where the bias is non-local (e.g. Sánchez et al. Reference Sánchez2016; Desjacques et al. Reference Desjacques, Jeong and Schmidt2018). Nevertheless, at sufficiently large scales as we probe here
 $(k\;\lesssim 0.2 \,h\,\text{Mpc}^{-1})$
, we can assume that it is only redshift dependent (e.g. Abbott et al. Reference Abbott2018). Thus, the projected quantity defined as the observed fluctuations of the galaxy number counts at a given sky position
$(k\;\lesssim 0.2 \,h\,\text{Mpc}^{-1})$
, we can assume that it is only redshift dependent (e.g. Abbott et al. Reference Abbott2018). Thus, the projected quantity defined as the observed fluctuations of the galaxy number counts at a given sky position
 $\hat{n}$
is related to the three-dimensional matter density fluctuations
$\hat{n}$
is related to the three-dimensional matter density fluctuations
 $\delta_m(z, \chi\hat{n})$
as
$\delta_m(z, \chi\hat{n})$
as
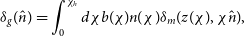 \begin{equation}\delta_g(\hat{n})=\int_0^{\chi_h} d\chi b(\chi)n(\chi)\delta_m(z(\chi),\chi\hat{n}),\end{equation}
\begin{equation}\delta_g(\hat{n})=\int_0^{\chi_h} d\chi b(\chi)n(\chi)\delta_m(z(\chi),\chi\hat{n}),\end{equation}
where
 $b(\chi)$
is the galaxy bias and
$b(\chi)$
is the galaxy bias and
 $n(\chi)$
the normalised distribution of galaxies. Then, the kernel in Equation (2) takes the form
$n(\chi)$
the normalised distribution of galaxies. Then, the kernel in Equation (2) takes the form
 \begin{equation}W^{\delta_g}(\ell,\chi)\equiv W^{\delta_g}(\chi)=n(\chi)b(\chi)\;.\end{equation}
\begin{equation}W^{\delta_g}(\ell,\chi)\equiv W^{\delta_g}(\chi)=n(\chi)b(\chi)\;.\end{equation}
We do not consider any other correcting term on top of the galaxy density field, like magnification bias or redshift-space distortions which both are subdominant in our analysis and are relevant for tomographic analysis and narrow redshift bins, respectively (Tanidis et al. Reference Tanidis, Camera and Parkinson2019).
2.2. CMB lensing
The convergence field
 $\kappa(\hat{n})$
is defined as the distortion of the CMB photon trajectories due to the gravitational potential caused by the underlying dark matter field (Lewis & Challinor Reference Lewis and Challinor2006). This is proportional to the divergence of the deflection in the photon arrival angle
$\kappa(\hat{n})$
is defined as the distortion of the CMB photon trajectories due to the gravitational potential caused by the underlying dark matter field (Lewis & Challinor Reference Lewis and Challinor2006). This is proportional to the divergence of the deflection in the photon arrival angle
 $\vec \alpha$
as:
$\vec \alpha$
as:
 $\kappa\equiv-{\nabla} \cdot {\vec \alpha}/2$
. Thus,
$\kappa\equiv-{\nabla} \cdot {\vec \alpha}/2$
. Thus,
 $\kappa$
is an unbiased tracer of the matter density fluctuations
$\kappa$
is an unbiased tracer of the matter density fluctuations
 $\delta_m(z, \chi\hat{n})$
and is related to them as
$\delta_m(z, \chi\hat{n})$
and is related to them as
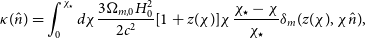 \begin{equation}\kappa(\hat{n})=\int_0^{\chi_\star} d\chi \frac{3\Omega_{m,0} H_0^2}{2c^2}[1+z(\chi)]\chi \frac{\chi_\star-\chi}{\chi_\star}\delta_m(z(\chi), \chi\hat{n}),\end{equation}
\begin{equation}\kappa(\hat{n})=\int_0^{\chi_\star} d\chi \frac{3\Omega_{m,0} H_0^2}{2c^2}[1+z(\chi)]\chi \frac{\chi_\star-\chi}{\chi_\star}\delta_m(z(\chi), \chi\hat{n}),\end{equation}
with c the speed of light,
 $\Omega_{m,0}$
the matter fraction at present,
$\Omega_{m,0}$
the matter fraction at present,
 $H_0$
the Hubble constant in units of km s−1 Mpc−1, and
$H_0$
the Hubble constant in units of km s−1 Mpc−1, and
 $\chi_\star$
the comoving distance at the last scattering surface corresponding to
$\chi_\star$
the comoving distance at the last scattering surface corresponding to
 $z_\star\approx1\,100$
. The radial kernel in this case takes the form
$z_\star\approx1\,100$
. The radial kernel in this case takes the form
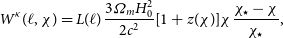 \begin{equation}W^\kappa(\ell,\chi)=L(\ell) \frac{3\varOmega_m H_0^2}{2c^2}[1+z(\chi)]\chi \frac{\chi_\star-\chi}{\chi_\star},\end{equation}
\begin{equation}W^\kappa(\ell,\chi)=L(\ell) \frac{3\varOmega_m H_0^2}{2c^2}[1+z(\chi)]\chi \frac{\chi_\star-\chi}{\chi_\star},\end{equation}
where the factor
 $L(\ell)$
reads
$L(\ell)$
reads
 \begin{equation} L(\ell)=\frac{\ell(\ell+1)}{(\ell+1/2)^2},\end{equation}
\begin{equation} L(\ell)=\frac{\ell(\ell+1)}{(\ell+1/2)^2},\end{equation}
which is only relevant (starts to deviate from unity) at
 $\ell\lesssim 10$
. This term accounts for the fact that
$\ell\lesssim 10$
. This term accounts for the fact that
 $\kappa$
is related to
$\kappa$
is related to
 $\delta_m$
through the angular Laplacian of the lensing potential
$\delta_m$
through the angular Laplacian of the lensing potential
 $\phi$
as:
$\phi$
as:
 $\kappa(\hat{n})=-{\nabla^2}\phi(\hat{n})/2$
.
$\kappa(\hat{n})=-{\nabla^2}\phi(\hat{n})/2$
.
3. Data
3.1. EMU Pilot Survey 1
The radio continuum galaxy sample used here is the Pilot Survey 1 of the Evolutionary Map of the Universe (EMU PS1; Norris et al. Reference Norris2021). EMU will cover the complete southern sky within five years and will observe several tens of million sources (Norris et al. Reference Norris2011; Johnston et al. Reference Johnston2007, Reference Johnston2008). Here we use the first pilot data covering a contiguous patch of
 $\sim 270 \text{ deg}^2$
, observed at 944 MHz, at a spatial resolution of 11–18 arcsec and reaching a depth of 25–30
$\sim 270 \text{ deg}^2$
, observed at 944 MHz, at a spatial resolution of 11–18 arcsec and reaching a depth of 25–30
 $\unicode{x03BC} \text{Jy/beam rms}$
. The resulting catalogue corresponds to roughly
$\unicode{x03BC} \text{Jy/beam rms}$
. The resulting catalogue corresponds to roughly
 $\sim$
200 000 sources for the full sample. The exact number slightly differs depending on the source finding algorithm used and it is further reduced after applying flux density cuts as we discuss in Section 3.1.1.
$\sim$
200 000 sources for the full sample. The exact number slightly differs depending on the source finding algorithm used and it is further reduced after applying flux density cuts as we discuss in Section 3.1.1.
3.1.1. Source finding algorithms and flux density cuts
The first source finding algorithm output we used is from the Selavy software (Whiting & Humphreys Reference Whiting and Humphreys2012; Whiting et al. Reference Whiting, Voronkov, Mitchell, Lorente, Shortridge and Wayth2017). The tool identifies pixels that have emission above a certain threshold, in this case 5 sigma (5 times the local rms in the image, Selavy variable snrCut=5) using the flood-fill technique, and groups the pixels that lie next to each other together into a single ‘island’. Then, if there are nearby pixels that lie above a lower threshold (in our case 3 times the rms, growthThreshold=3), the island can be ‘grown’ to encompass these pixels also. As discussed in Whiting & Humphreys (Reference Whiting and Humphreys2012), this ‘growing’ can lead to nearby sources being merged with the source under-consideration. Finally then, it fits Gaussian components to peaks of emission within the islands (Fitter.doFit=true). We note that we use the estimate of the total flux density of each source by summing over the Gaussians that have been fit to the components, for a more accurate integrated flux density estimate.
At this point we note that we consider only the Selavy island sample and not the Selavy component sample for the cosmological analysis described in Section 5. We make this choice due to the fact that as sources can be quite extended in the images, different components can be generated by the same radio galaxy. This can affect the clustering statistics at small scales
 $\lt0.1^\circ$
(see again Norris et al. Reference Norris2021). Even though we use the islands catalogue, there still may exist residual biases we need to account for (see discussion in Section 4.3). We also cross-check that the clustering measurements we discuss in Section 5.2 using the Selavy island catalogue are in good agreement with the machine-learning based morphological classification of EMU-PS radio catalogue compiled with the Gal-DINO pipeline (Gupta et al. Reference Gupta2024).
$\lt0.1^\circ$
(see again Norris et al. Reference Norris2021). Even though we use the islands catalogue, there still may exist residual biases we need to account for (see discussion in Section 4.3). We also cross-check that the clustering measurements we discuss in Section 5.2 using the Selavy island catalogue are in good agreement with the machine-learning based morphological classification of EMU-PS radio catalogue compiled with the Gal-DINO pipeline (Gupta et al. Reference Gupta2024).
The other source finder algorithm we used to generate the catalogue is PyBDSF
Footnote
c
(Mohan & Rafferty Reference Mohan and Rafferty2015). To do this, we set a threshold which determines which pixels contribute to an island of emission (thresh_isl) to be 3
 $\sigma$
and the threshold for source detection (thresh_pix) to 5
$\sigma$
and the threshold for source detection (thresh_pix) to 5
 $\sigma$
. We additionally include a specification that the background mean level should be zero (mean_map=‘zero’) and specify the box size and step size used to generate the rms map (rms_box = (150,30)). From running PyBDSF over the image we record the rms map, to generate random sources, alongside the output source and Gaussian catalogues.
$\sigma$
. We additionally include a specification that the background mean level should be zero (mean_map=‘zero’) and specify the box size and step size used to generate the rms map (rms_box = (150,30)). From running PyBDSF over the image we record the rms map, to generate random sources, alongside the output source and Gaussian catalogues.
In addition, we consider only the galaxies with flux density brighter than 0.18 mJy. The choice is based on the fact that for sources brighter than this value, the source counts in the previous models and simulations (Mancuso et al. Reference Mancuso2017; Bonaldi et al. Reference Bonaldi, Bonato, Galluzzi, Harrison, Massardi, Kay, De Zotti and Brown2018) are in agreement with the EMU PS1 island catalogue (Norris et al. Reference Norris2021). In order to test the robustness of our cosmological analysis on the galaxy sample, we also consider a more rigorous flux density cut at
 $0.4$
mJy. We perform these cuts both on Selavy and PyBDSF catalogues. The number of galaxies after the flux density cuts and the maps are discussed in Section 4.1.
$0.4$
mJy. We perform these cuts both on Selavy and PyBDSF catalogues. The number of galaxies after the flux density cuts and the maps are discussed in Section 4.1.
3.1.2. Redshift distributions
As we can appreciate from Equation (4), to estimate the kernel of the radio continuum galaxy sample we need to obtain an accurate model for the galaxy number distribution as a function of redshift. To achieve that, we make use of two of the largest extragalactic radio galaxy simulations; the European SKA Design Study (hereafter SKADS) Simulated Skies (Wilman et al. Reference Wilman2008), and the Tiered Radio Extragalactic Continuum Simulation (hereafter T-RECS; Bonaldi et al. Reference Bonaldi, Bonato, Galluzzi, Harrison, Massardi, Kay, De Zotti and Brown2018). Also, we consider for both simulations AGNs and SFGs contributions, which constitute the main tracers of the galaxy populations in the radio surveys. In Fig. 1, we show the redshift distributions for SKADS and T-RECS and for the flux density cuts at
 $0.18$
and
$0.18$
and
 $0.4$
mJy. The distributions are not affected considerably by the flux density cuts and both SKADS and T-RECS are peaked at
$0.4$
mJy. The distributions are not affected considerably by the flux density cuts and both SKADS and T-RECS are peaked at
 $z\sim0.5$
, after which they fall slowly up to high redshifts. Nonetheless, we can appreciate that the SKADS has longer tail at high redshift, while the T-RECS is more localized at
$z\sim0.5$
, after which they fall slowly up to high redshifts. Nonetheless, we can appreciate that the SKADS has longer tail at high redshift, while the T-RECS is more localized at
 $z\sim0.5$
. This can affect power spectra fits to the data, since samples with broader redshift distributions wash out their structure information, decreasing in this way the power amplitude and in turn increasing the galaxy bias
$z\sim0.5$
. This can affect power spectra fits to the data, since samples with broader redshift distributions wash out their structure information, decreasing in this way the power amplitude and in turn increasing the galaxy bias
 $b_g$
. However, as we discuss in Section 5.3, this difference does not affect the results significantly (shift of
$b_g$
. However, as we discuss in Section 5.3, this difference does not affect the results significantly (shift of
 $\sim0.2\sigma$
). Thus, for our baseline results of Sections 5.3 and 5.4, we use the SKADS distribution.
$\sim0.2\sigma$
). Thus, for our baseline results of Sections 5.3 and 5.4, we use the SKADS distribution.
It is important to stress at this point that SKADS and T-RECS have both similarities (all of them considering AGNs and SFGs) and differences (empirical models for the former and more detailed population models for the latter) and therefore, it should not be surprising that the redshift distributions look similar. The comparison we make between them in this work (Appendix C) certainly should not be seen as a robustness systematic test but rather as an indicative comparison between the state-of-the art radio continuum simulation codes given the large uncertainty in the redshift distribution of the radio galaxies. In fact, there is a series of ongoing parallel works aimed to constrain both the peak and the tail of the redshift distribution of the EMU radio sample by using cross-correlation with the Dark Energy Survey (DES, Abbott et al. Reference Abbott2016) optical galaxies (Saraf et al. Reference Saraf, Parkinson, Asorey, Hale, Bahr-Kalus, Camera and Tanidis2025) and the Euclid telescope (Mellier et al. Reference Mellier2024) deep fields (Bahr-Kalus et al., in preparation). Also, a cross-matching study that will further help in the modelling of the redshift distribution is planned in the future.
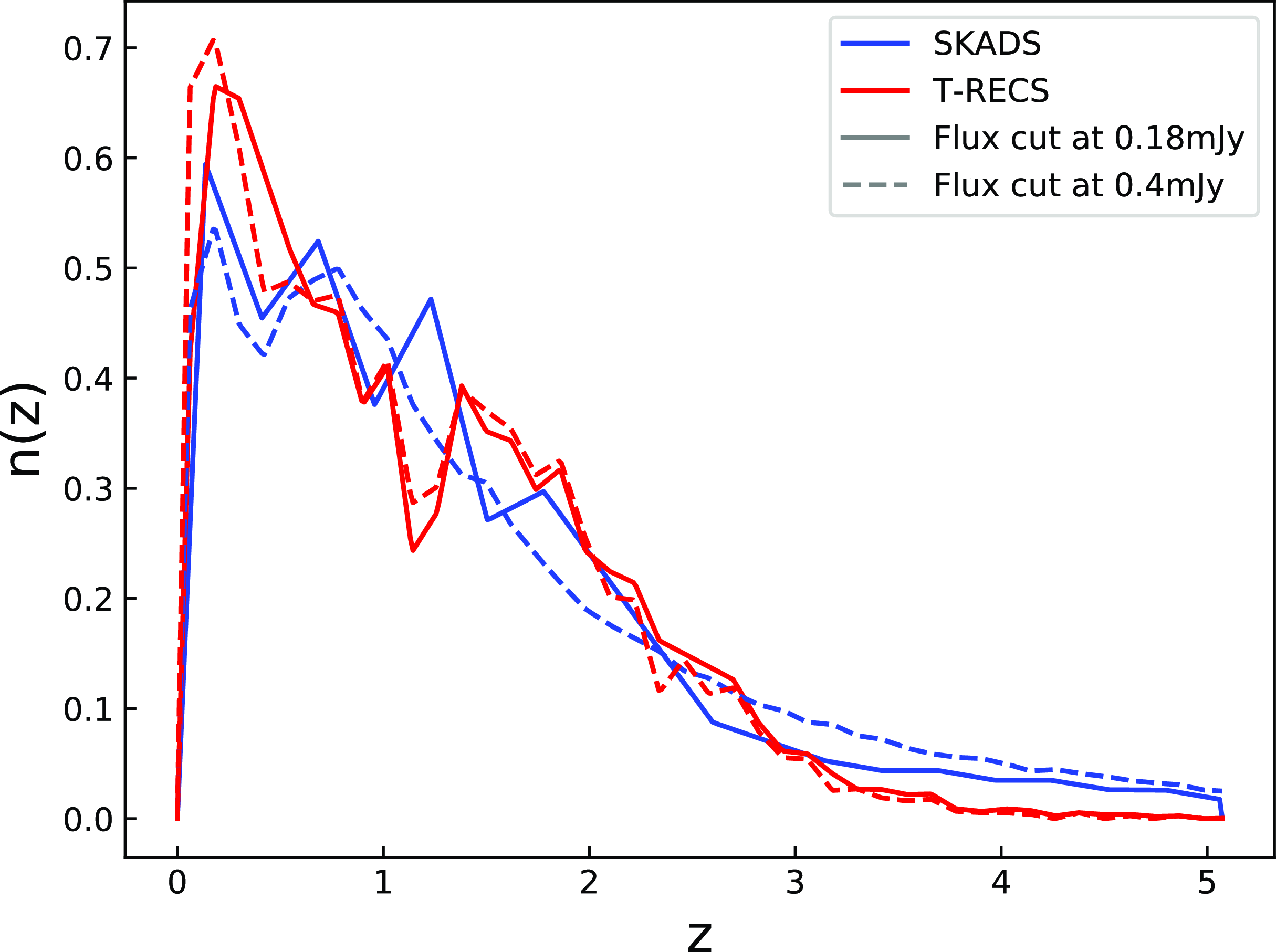
Figure 1. The normalised redshift distributions of radio continuum galaxies as estimated from the simulations SKADS (blue) and T-RECS (red) at the flux density cuts 0.18 (solid) and 0.4 mJy (dashed).
3.2. Planck PR4
We use the publicly available CMB lensing convergence map
 $\kappa$
from the Planck PR4 data (Carron et al. Reference Carron, Mirmelstein and Lewis2022). This map is constructed using an improved lensing quadratic estimator and contains
$\kappa$
from the Planck PR4 data (Carron et al. Reference Carron, Mirmelstein and Lewis2022). This map is constructed using an improved lensing quadratic estimator and contains
 $\sim$
8% more data than the previous release of 2018 Planck PR3 (Planck Collaboration et al. 2020b). The harmonic coefficients of the
$\sim$
8% more data than the previous release of 2018 Planck PR3 (Planck Collaboration et al. 2020b). The harmonic coefficients of the
 $\kappa$
mean-field subtracted map are transformed to a HEALPix map with
$\kappa$
mean-field subtracted map are transformed to a HEALPix map with
 $N_{\text{side}}=512$
corresponding to a pixel size of
$N_{\text{side}}=512$
corresponding to a pixel size of
 $\sim$
6.9 arcmin. This resolution is also used for the galaxy overdensity maps which is discussed in Section 4.1, and it is considered to be accurate enough for the scales we probe in this work. The convergence map covers
$\sim$
6.9 arcmin. This resolution is also used for the galaxy overdensity maps which is discussed in Section 4.1, and it is considered to be accurate enough for the scales we probe in this work. The convergence map covers
 $\sim$
67% of the sky and fully overlaps with the footprint of the EMU PS1 map. The convergence map has a few holes that remove less than 1% of the EMU-PS1 footprint (see Fig. 2).
$\sim$
67% of the sky and fully overlaps with the footprint of the EMU PS1 map. The convergence map has a few holes that remove less than 1% of the EMU-PS1 footprint (see Fig. 2).

Figure 2. A list of maps that was used in our work. Top left: The weights mask for Selavy. Top right: The galaxy overdensity map for Selavy. Middle left: The weights mask for PyBDSF. Middle right: The galaxy overdensity map for PyBDSF. Bottom: The CMB convergence map. All the galaxy maps here are for the flux density cut at
 $0.18$
mJy, while for the cut at
$0.18$
mJy, while for the cut at
 $0.4$
mJy, they look similar. In the overdensities and convergence panels, the mask is shown with grey color.
$0.4$
mJy, they look similar. In the overdensities and convergence panels, the mask is shown with grey color.
4. Methodology
4.1. Pseudo-
 $\boldsymbol{C}_{\boldsymbol\ell}$
s
$\boldsymbol{C}_{\boldsymbol\ell}$
s

The harmonic-space coefficients and the spectrum of Equation (1) are defined under the full-sky assumption. In reality, we are able to observe only a part of the sky. This is true both for the radio continuum galaxy maps and the CMB lensing convergence map as we have seen in Sections 3.1 and 3.2. Thus, the measured values of harmonic coefficients differ from the full-sky ones leading to the pseudo-
 $C_\ell$
spectrum which accounts for the partial sky. We do this by using the python package NaMaster (Alonso et al. Reference Alonso, Sanchez, Slosar and Collaboration2019).
$C_\ell$
spectrum which accounts for the partial sky. We do this by using the python package NaMaster (Alonso et al. Reference Alonso, Sanchez, Slosar and Collaboration2019).
To construct the weight maps for EMU-PS1, we create a mask that accounts for the rms of the EMU PS1 mosaic. To do so, we create a galaxy random catalogue by following the method described in Hale et al. (Reference Hale, Jarvis, Delvecchio, Hatfield, Novak, Smolčić and Zamorani2017). We start by drawing uniform random angular positions, and random flux densities from the SKADS simulation (Wilman et al. Reference Wilman2008) at a frequency of 1.4 GHz, scaled to 944 MHz. For each of the catalogs (Selavy or PyBDF), an rms image is produced respectively. These RMS images allow us to include the observational noise in each position of the map. We then only select random galaxies with flux densities with a significance
 $5\sigma$
above the rms level, given by each catalogue rms map, of the corresponding angular position. Once we have a random catalogue, we apply a flux density cut for the corresponding galaxy sample. The weights mask is just the ratio between the number of random galaxies in a given HEALPix pixel and the number of random galaxies from the original uniform randoms (before the rms flux density cut). The randoms are created in a set of realizations, producing
$5\sigma$
above the rms level, given by each catalogue rms map, of the corresponding angular position. Once we have a random catalogue, we apply a flux density cut for the corresponding galaxy sample. The weights mask is just the ratio between the number of random galaxies in a given HEALPix pixel and the number of random galaxies from the original uniform randoms (before the rms flux density cut). The randoms are created in a set of realizations, producing
 $20\,000$
uniform randoms for each realisation. The final number of random galaxies used was selected by checking the stability of the spectra measurements for a given number of realizations. We found that the pseudo-
$20\,000$
uniform randoms for each realisation. The final number of random galaxies used was selected by checking the stability of the spectra measurements for a given number of realizations. We found that the pseudo-
 $C_\ell$
s spectra are robust when the number of realisations to produce the randoms is above 500.
$C_\ell$
s spectra are robust when the number of realisations to produce the randoms is above 500.
The definition of the observed fluctuations in the galaxy number counts now becomes,
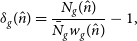 \begin{equation}\delta_g(\hat{n})=\frac{N_g(\hat{n})}{\bar{N}_g w_g(\hat{n})}-1,\end{equation}
\begin{equation}\delta_g(\hat{n})=\frac{N_g(\hat{n})}{\bar{N}_g w_g(\hat{n})}-1,\end{equation}
with
 $N_g(\hat{n})$
the number of galaxies in the pixel position
$N_g(\hat{n})$
the number of galaxies in the pixel position
 $\hat{n}$
and
$\hat{n}$
and
 $w_g(\hat{n})$
the weights in the same pixel position.
$w_g(\hat{n})$
the weights in the same pixel position.
 $\bar{N}_g$
is the weighted mean number of sources per pixel in our samples and reads:
$\bar{N}_g$
is the weighted mean number of sources per pixel in our samples and reads:
 $\bar{N}_g=\left\langle N_g(\hat{n})\right\rangle_n/{\left\langle w_g(\hat{n})\right\rangle}_n$
, with
$\bar{N}_g=\left\langle N_g(\hat{n})\right\rangle_n/{\left\langle w_g(\hat{n})\right\rangle}_n$
, with
 $\left\langle. \right\rangle_n$
denoting the mean over all the pixels in the map. We also avoid heavily masked pixels by setting
$\left\langle. \right\rangle_n$
denoting the mean over all the pixels in the map. We also avoid heavily masked pixels by setting
 $w_g(\hat{n})$
and
$w_g(\hat{n})$
and
 $\delta_g(\hat{n})$
pixels to zero where
$\delta_g(\hat{n})$
pixels to zero where
 $w_g(\hat{n})\lt0.5$
. The final number of galaxies for the Selavy catalogue is 166 801 at
$w_g(\hat{n})\lt0.5$
. The final number of galaxies for the Selavy catalogue is 166 801 at
 $\gt0.18$
mJy and 83 222 at
$\gt0.18$
mJy and 83 222 at
 $\gt0.4$
mJy, while for PyBDSF are 188 034 and 89 320, respectively. The weight footprints and galaxy overdensity maps for Selavy and PyBDSF are shown in Fig. 2 with the latter having 2% larger footprint than the former. This is due to the fact that Selavy has a stricter limit on the acceptable weights at the edges of the footprint truncating slightly the coverage.
$\gt0.4$
mJy, while for PyBDSF are 188 034 and 89 320, respectively. The weight footprints and galaxy overdensity maps for Selavy and PyBDSF are shown in Fig. 2 with the latter having 2% larger footprint than the former. This is due to the fact that Selavy has a stricter limit on the acceptable weights at the edges of the footprint truncating slightly the coverage.
After the construction of the overdensity maps, we transform the weight maps to binary masks and we couple the spectra with them using NaMaster. We verify that our results are stable when we perform this. The pseudo-
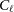 $C_\ell$
harmonic-space spectrum (Hivon et al. Reference Hivon2002) is defined as
$C_\ell$
harmonic-space spectrum (Hivon et al. Reference Hivon2002) is defined as
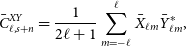 \begin{equation}\bar{C}^{XY}_{\ell,s+n}=\frac{1}{2\ell+1}\sum_{m=-\ell}^\ell \bar{X}_{\ell m} \bar{Y}^*_{\ell m}, \end{equation}
\begin{equation}\bar{C}^{XY}_{\ell,s+n}=\frac{1}{2\ell+1}\sum_{m=-\ell}^\ell \bar{X}_{\ell m} \bar{Y}^*_{\ell m}, \end{equation}
where
 $\bar{X}_{\ell m}$
and
$\bar{X}_{\ell m}$
and
 $\bar{Y}_{\ell m}$
denote the partial sky harmonic coefficients of the fields receiving contributions from signal and noise
$\bar{Y}_{\ell m}$
denote the partial sky harmonic coefficients of the fields receiving contributions from signal and noise
 $s+n$
. The observed harmonic-space spectrum is the ensemble average
$s+n$
. The observed harmonic-space spectrum is the ensemble average
 $\tilde{C}^{XY}_{\ell,s+n}=\langle \bar{C}^{XY}_{\ell,s+n} \rangle$
and is related to the true signal
$\tilde{C}^{XY}_{\ell,s+n}=\langle \bar{C}^{XY}_{\ell,s+n} \rangle$
and is related to the true signal
 $S_{\ell}$
(see again Equation 1) via
$S_{\ell}$
(see again Equation 1) via
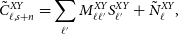 \begin{equation}\tilde{C}^{XY}_{\ell,s+n}=\sum_{\ell^{\prime}} M^{XY}_{\ell\ell^{\prime}} S^{XY}_{\ell^{\prime}}+\tilde{N}^{XY}_\ell, \end{equation}
\begin{equation}\tilde{C}^{XY}_{\ell,s+n}=\sum_{\ell^{\prime}} M^{XY}_{\ell\ell^{\prime}} S^{XY}_{\ell^{\prime}}+\tilde{N}^{XY}_\ell, \end{equation}
where
 $\tilde{N}^{XY}_\ell=\delta^{\textrm{K}}_{XY}\varOmega_{\text{p}}\bar{w}_g/\bar{N}_X$
is the shot noise (Nicola et al. Reference Nicola2020) with
$\tilde{N}^{XY}_\ell=\delta^{\textrm{K}}_{XY}\varOmega_{\text{p}}\bar{w}_g/\bar{N}_X$
is the shot noise (Nicola et al. Reference Nicola2020) with
 $\bar{w}_g$
the average value of the mask across the sky (see Equation 8) and
$\bar{w}_g$
the average value of the mask across the sky (see Equation 8) and
 $\varOmega_{\text{p}}$
the pixel area in units of steradians. The noise needs to be subtracted for auto-correlations to obtain the masked signal
$\varOmega_{\text{p}}$
the pixel area in units of steradians. The noise needs to be subtracted for auto-correlations to obtain the masked signal
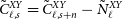 $\tilde{C}^{XY}_{\ell, s}=\tilde{C}^{XY}_{\ell, s+n}-\tilde{N}^{XY}_\ell$
. By rescaling it with the survey sky fraction
$\tilde{C}^{XY}_{\ell, s}=\tilde{C}^{XY}_{\ell, s+n}-\tilde{N}^{XY}_\ell$
. By rescaling it with the survey sky fraction
 $f_{\text{sky}}$
, we can get an estimate of the true spectrum as
$f_{\text{sky}}$
, we can get an estimate of the true spectrum as
 $\tilde{C}^{XY}_{\ell}\equiv S^{XY}_\ell=\tilde{C}^{XY}_{\ell, s}/f_{\text{sky}}$
, which is a good approximation for fairly flat power spectra, as we consider here (Nicola et al. Reference Nicola, García-García, Alonso, Dunkley, Ferreira, Slosar and Spergel2021). The quantity
$\tilde{C}^{XY}_{\ell}\equiv S^{XY}_\ell=\tilde{C}^{XY}_{\ell, s}/f_{\text{sky}}$
, which is a good approximation for fairly flat power spectra, as we consider here (Nicola et al. Reference Nicola, García-García, Alonso, Dunkley, Ferreira, Slosar and Spergel2021). The quantity
 $M_{\ell\ell^{\prime}}$
is the mode coupling matrix (Peebles 1973) due to the masked area and it is defined as,
$M_{\ell\ell^{\prime}}$
is the mode coupling matrix (Peebles 1973) due to the masked area and it is defined as,
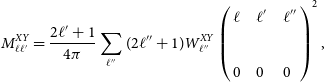 \begin{equation}M^{XY}_{\ell\ell^{\prime}} =\frac{2 \ell^{\prime} + 1}{4 \pi}\sum_{\ell^{\prime \prime}} (2 \ell^{\prime\prime} + 1){W_{\ell^{\prime \prime}}^{XY}\left (\begin{array}{l@{\quad}l@{\quad}l}\displaystyle{\ell} & \displaystyle{\ell^{\prime}} & \displaystyle{\ell^{\prime \prime}} \\& & \\\displaystyle{0} & \displaystyle{0} & \displaystyle{0} \\\end{array}\right)^2} \,, \end{equation}
\begin{equation}M^{XY}_{\ell\ell^{\prime}} =\frac{2 \ell^{\prime} + 1}{4 \pi}\sum_{\ell^{\prime \prime}} (2 \ell^{\prime\prime} + 1){W_{\ell^{\prime \prime}}^{XY}\left (\begin{array}{l@{\quad}l@{\quad}l}\displaystyle{\ell} & \displaystyle{\ell^{\prime}} & \displaystyle{\ell^{\prime \prime}} \\& & \\\displaystyle{0} & \displaystyle{0} & \displaystyle{0} \\\end{array}\right)^2} \,, \end{equation}
with
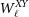 $W_\ell^{XY}$
the spectra of the masks which read,
$W_\ell^{XY}$
the spectra of the masks which read,
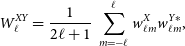 \begin{equation}W_\ell^{XY} = \frac{1}{2\ell+1}\,\sum_{m=-\ell}^{\ell} w_{\ell m}^X {w_{\ell m}^{Y\ast}}, \end{equation}
\begin{equation}W_\ell^{XY} = \frac{1}{2\ell+1}\,\sum_{m=-\ell}^{\ell} w_{\ell m}^X {w_{\ell m}^{Y\ast}}, \end{equation}
where
 $w_{\ell m}^X$
and
$w_{\ell m}^X$
and
 $w_{\ell m}^Y$
are the spherical harmonic coefficients of the masks of the fields under study.
$w_{\ell m}^Y$
are the spherical harmonic coefficients of the masks of the fields under study.
As we elaborate in Section 4.3 we need to compare the measured spectra with the model spectra from theory that we saw in Equation (2). To do this, we also account for the partial sky effect in the theory spectra by applying the same coupling matrix convolution and the rescaling correction as,
 \begin{equation}\tilde{S}^{XY}_\ell=\left(\sum_{\ell^{\prime}} M^{XY}_{\ell\ell^{\prime}} S^{XY}_{\ell^{\prime}, \text{th}}\right)/f_{\text{sky}}. \end{equation}
\begin{equation}\tilde{S}^{XY}_\ell=\left(\sum_{\ell^{\prime}} M^{XY}_{\ell\ell^{\prime}} S^{XY}_{\ell^{\prime}, \text{th}}\right)/f_{\text{sky}}. \end{equation}
4.2. Matter spectrum and galaxy bias models
We consider both a linear and a non-linear matter power spectrum
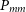 $P_{mm}$
for the theory harmonic-space spectrum of Equation (2). To obtain the linear model we use the Boltzmann solver CAMB (Lewis, Challinor, & Lasenby Reference Lewis, Challinor and Lasenby2000) and we get the non-linear model from it with HALOFIT (Smith et al. Reference Smith2003; Takahashi et al. Reference Takahashi, Sato, Nishimichi, Taruya and Oguri2012). Unless otherwise stated, we use the fiducial cosmology best-fit values by Planck Collaboration et al. (2020a), which are: present day cold dark mater fraction,
$P_{mm}$
for the theory harmonic-space spectrum of Equation (2). To obtain the linear model we use the Boltzmann solver CAMB (Lewis, Challinor, & Lasenby Reference Lewis, Challinor and Lasenby2000) and we get the non-linear model from it with HALOFIT (Smith et al. Reference Smith2003; Takahashi et al. Reference Takahashi, Sato, Nishimichi, Taruya and Oguri2012). Unless otherwise stated, we use the fiducial cosmology best-fit values by Planck Collaboration et al. (2020a), which are: present day cold dark mater fraction,
 $\Omega_{c,0}=0.26503$
; present day baryon fraction,
$\Omega_{c,0}=0.26503$
; present day baryon fraction,
 $\Omega_{b,0}=0.04939$
; rms variance of linear matter fluctuations at present in spheres of
$\Omega_{b,0}=0.04939$
; rms variance of linear matter fluctuations at present in spheres of
 $8\,h^{-1}\,\text{Mpc}$
,
$8\,h^{-1}\,\text{Mpc}$
,
 $\sigma_8=0.8111$
; dimensionless Hubble constant
$\sigma_8=0.8111$
; dimensionless Hubble constant
 $h\equiv H_{0}/(100\,\text{km,s}^{-1}\,\text{Mpc}^{-1}) = 0.6732$
and primordial power spectrum spectral index,
$h\equiv H_{0}/(100\,\text{km,s}^{-1}\,\text{Mpc}^{-1}) = 0.6732$
and primordial power spectrum spectral index,
 $n_s=0.96605$
. The theoretical calculations in this work are done using the code CosmoSIS (Zuntz et al. Reference Zuntz2015).
$n_s=0.96605$
. The theoretical calculations in this work are done using the code CosmoSIS (Zuntz et al. Reference Zuntz2015).
Regarding the galaxy bias redshift evolution we consider two models (Alonso et al. Reference Alonso, Bellini, Hale, Jarvis and Schwarz2021):
-
• A constant galaxy bias model with
$b(z)=b_g$
which represents a simple scenario, where the growth evolution with time of the galaxy clustering follows that of the matter fluctuations. -
• A constant amplitude galaxy bias model with
$b(z)=b_{g}/D(z)$
which evolves with the inverse of the linear growth factor defined as:
$D(z)=[P^\textrm{lin}_{mm}(k,z)/P^\textrm{lin}_{mm}(k,0)]^{1/2}$
in the linear regime
$k\rightarrow{0}$
. This model, though still simple with one parameter as well, preserves its large-scale properties unchanged and remains fixed at early times (since at linear scales
$\delta_m\propto D$
). At the same time, it is able to reproduce the expected rise in b(z) at high redshift for a flux density-limited galaxy sample (e.g. Bardeen et al. Reference Bardeen, Bond, Kaiser and Szalay1986; Mo & White Reference Mo and White1996; Tegmark & Peebles Reference Tegmark and Peebles1998; Coil et al. Reference Coil2004).





On top of these models, we also test another more flexible case, that of a quadratic galaxy bias model:
 $b(z)=b_0+b_1z + b_2z^2$
with three parameters
$b(z)=b_0+b_1z + b_2z^2$
with three parameters
 $\{b_0, b_1, b_2\}$
. However, as we later discuss in Appendix A the results of this model are consistent with those of the constant galaxy bias and, therefore we do not use it in our fiducial analysis of Section 5.
$\{b_0, b_1, b_2\}$
. However, as we later discuss in Appendix A the results of this model are consistent with those of the constant galaxy bias and, therefore we do not use it in our fiducial analysis of Section 5.
Finally, in our pipeline we consider scales up to
 $\ell_{\text{max}}=500$
. This corresponds to
$\ell_{\text{max}}=500$
. This corresponds to
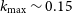 $k_{\text{max}}\sim 0.15$
Mpc
$k_{\text{max}}\sim 0.15$
Mpc
 $^{-1}$
at
$^{-1}$
at
 $z_{\text{med}}\sim 1$
which is the rough median redshift for both distributions (in particular,
$z_{\text{med}}\sim 1$
which is the rough median redshift for both distributions (in particular,
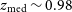 $z_{\text{med}}\sim0.98$
for T-RECS and
$z_{\text{med}}\sim0.98$
for T-RECS and
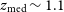 $z_{\text{med}}\sim 1.1$
for SKADS). In this mildly non-linear regime, the linear galaxy bias model is a good approximation, while we can neglect non-Gaussian contributions to the covariance matrix (e.g. Smith et al. Reference Smith, Zahn and Doré2007; Cooray Reference Cooray2004).
$z_{\text{med}}\sim 1.1$
for SKADS). In this mildly non-linear regime, the linear galaxy bias model is a good approximation, while we can neglect non-Gaussian contributions to the covariance matrix (e.g. Smith et al. Reference Smith, Zahn and Doré2007; Cooray Reference Cooray2004).
4.3. Covariance matrix and likelihood
Assuming that
 $\kappa$
and g are random variables, we can write the analytical covariance matrix
$\kappa$
and g are random variables, we can write the analytical covariance matrix
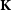 $\textbf{K}$
terms for the auto-correlation gg and the cross-correlation
$\textbf{K}$
terms for the auto-correlation gg and the cross-correlation
 $g\kappa$
spectra as follows,
$g\kappa$
spectra as follows,
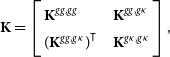 \begin{equation}\textbf{K}=\left [\begin{array}{l@{\quad}l}\displaystyle{\textbf{K}^{gg,gg}} & \displaystyle{\textbf{K}^{gg,g\kappa}} \\\displaystyle{(\textbf{K}^{gg,g\kappa})^{\sf T}} & \displaystyle{\textbf{K}^{g\kappa,g\kappa}} \\\end{array}\right], \end{equation}
\begin{equation}\textbf{K}=\left [\begin{array}{l@{\quad}l}\displaystyle{\textbf{K}^{gg,gg}} & \displaystyle{\textbf{K}^{gg,g\kappa}} \\\displaystyle{(\textbf{K}^{gg,g\kappa})^{\sf T}} & \displaystyle{\textbf{K}^{g\kappa,g\kappa}} \\\end{array}\right], \end{equation}
with each sub-block taking the form,
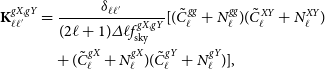 \begin{align}\textbf{K}^{gX,gY}_{\ell\ell^{\prime}}&=\frac{\delta_{\ell\ell^{\prime}}}{(2\ell+1)\varDelta\ell f_{\text{sky}}^{gX,gY}}[(\tilde{C}^{gg}_\ell+N^{gg}_\ell)(\tilde{C}^{XY}_{\ell}+N^{XY}_{\ell})\notag \\ &\quad +(\tilde{C}^{gX}_\ell+N^{gX}_\ell)(\tilde{C}^{gY}_{\ell}+N^{gY}_{\ell})],\end{align}
\begin{align}\textbf{K}^{gX,gY}_{\ell\ell^{\prime}}&=\frac{\delta_{\ell\ell^{\prime}}}{(2\ell+1)\varDelta\ell f_{\text{sky}}^{gX,gY}}[(\tilde{C}^{gg}_\ell+N^{gg}_\ell)(\tilde{C}^{XY}_{\ell}+N^{XY}_{\ell})\notag \\ &\quad +(\tilde{C}^{gX}_\ell+N^{gX}_\ell)(\tilde{C}^{gY}_{\ell}+N^{gY}_{\ell})],\end{align}
where X and Y can both be g or
 $\kappa$
and
$\kappa$
and
 $\varDelta\ell$
the multipole binwidth. The sky fractions read:
$\varDelta\ell$
the multipole binwidth. The sky fractions read:
 $f_{\text{sky}}^{gX,gY}=\sqrt{f_{\text{sky}}^{gX}\cdot f_{\text{sky}}^{gY}}$
and
$f_{\text{sky}}^{gX,gY}=\sqrt{f_{\text{sky}}^{gX}\cdot f_{\text{sky}}^{gY}}$
and
 $f_{\text{sky}}^{gg}\approx f_{\text{sky}}^{g\kappa}$
. We also bin the measured masked and rescaled
$f_{\text{sky}}^{gg}\approx f_{\text{sky}}^{g\kappa}$
. We also bin the measured masked and rescaled
 $\tilde{C}^{XY}_\ell$
as well as the theory
$\tilde{C}^{XY}_\ell$
as well as the theory
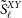 $\tilde{S}^{XY}_\ell$
power spectra with
$\tilde{S}^{XY}_\ell$
power spectra with
 $N_\ell$
=11 multipoles, linearly fromFootnote
d
$N_\ell$
=11 multipoles, linearly fromFootnote
d
 $\ell_{\text{min}}=2$
to
$\ell_{\text{min}}=2$
to
 $\ell_{\text{max}}=500$
. In addition, we verify that our results using the analytical covariance in Section 5 are robust by comparing them with the numerical covariance which is described in Appendix B.
$\ell_{\text{max}}=500$
. In addition, we verify that our results using the analytical covariance in Section 5 are robust by comparing them with the numerical covariance which is described in Appendix B.
Assuming that the spectra follow a Gaussian distribution, we can use the log-likelihood,
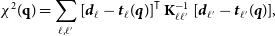 \begin{equation}\chi^2(\textbf{q})=\sum_{\ell,\ell^{\prime}}[\boldsymbol{d}_\ell-\boldsymbol{t}_\ell(\boldsymbol{q})]^{\sf T}\,\textbf{K}_{\ell\ell^{\prime}}^{-1}\,[\boldsymbol{d}_{\ell^{\prime}}-\boldsymbol{t}_{\ell^{\prime}}(\boldsymbol{q})], \end{equation}
\begin{equation}\chi^2(\textbf{q})=\sum_{\ell,\ell^{\prime}}[\boldsymbol{d}_\ell-\boldsymbol{t}_\ell(\boldsymbol{q})]^{\sf T}\,\textbf{K}_{\ell\ell^{\prime}}^{-1}\,[\boldsymbol{d}_{\ell^{\prime}}-\boldsymbol{t}_{\ell^{\prime}}(\boldsymbol{q})], \end{equation}
where
 $\boldsymbol{d}_\ell=\{\tilde{C}^{gg}_\ell, \tilde{C}^{g\kappa}_\ell\}$
and
$\boldsymbol{d}_\ell=\{\tilde{C}^{gg}_\ell, \tilde{C}^{g\kappa}_\ell\}$
and
 $\boldsymbol{t}_\ell=\{\tilde{S}^{gg}_\ell, \tilde{S}^{g\kappa}_\ell\}$
denote the data and theory model vectors and
$\boldsymbol{t}_\ell=\{\tilde{S}^{gg}_\ell, \tilde{S}^{g\kappa}_\ell\}$
denote the data and theory model vectors and
 $\boldsymbol{q}$
the parameter set of interest we want to fit. In our analysis we aim to constrain the galaxy bias
$\boldsymbol{q}$
the parameter set of interest we want to fit. In our analysis we aim to constrain the galaxy bias
 $b_g$
and
$b_g$
and
 $\sigma_8$
. For both parameters, we assume flat priors
$\sigma_8$
. For both parameters, we assume flat priors
 $b_g\in(0.01, 10)$
and
$b_g\in(0.01, 10)$
and
 $\sigma_8\in(0.01, 1.6)$
. To estimate the posterior distributions of the parameters we use publicly available Bayesian-based sampler emcee (Foreman-Mackey et al. Reference Foreman-Mackey, Hogg, Lang and Goodman2013).
$\sigma_8\in(0.01, 1.6)$
. To estimate the posterior distributions of the parameters we use publicly available Bayesian-based sampler emcee (Foreman-Mackey et al. Reference Foreman-Mackey, Hogg, Lang and Goodman2013).
5. Results
5.1. Differences between the source finding algorithms and deviations from shot noise
As discussed in Section 3.1.1 radio surveys can have multi-component structures that could affect the power spectrum and the Poissonian shot noise. At this point, we discuss the main difference between the two source finding algorithms, namely, the Selavy and PyBDSF, which we introduced in Section 3.1.1. In the island catalogue of Selavy, the algorithm categorises as single objects, structures that are quite large. However, these large objects could, in fact, contain smaller sub-structures which could be part of the same extended object (multi-component object) or could belong to different sources. The PyBDSF algorithm is able to find these structures and categorise them as different sources. This can result, of course, in a larger power spectrum (more clustering) as measured by PyBDSF at small scales, where many smaller sources could correspond to a single large source for Selavy. Indeed, this is what we find for the measurements from the two catalogues in Section 5.2 Finding more clustering with the PyBDSF is not necessarily the correct thing, as the algorithm can incorrectly consider small sub-structures that may belong to a single galaxy, as different galaxies. Furthermore, there are additional effects like halo exclusion, and non-local and stochastic effects in galaxy formation (Blake, Ferreira, & Borrill Reference Blake, Ferreira and Borrill2004, Tiwari et al. Reference Tiwari, Zhao, Zheng, Zhao, Bacon and Schwarz2022).
All of these contributions can also induce deviations from Poissonian shot noise. To account for these contributions, we marginalise over an extra free amplitude parameter for the shot noise
 $A_{\text{sn}}$
(Nakoneczny et al. 2024) when we subtract it in the data auto-correlation gg as
$A_{\text{sn}}$
(Nakoneczny et al. 2024) when we subtract it in the data auto-correlation gg as
 $\tilde{C}^{XY}_{\ell, s}=\tilde{C}^{XY}_{\ell, s+n}-A_{\text{sn}}\tilde{N}^{XY}_\ell$
, making the galaxy clustering auto-correlation sensitive to non-flat contributions. Based on the
$\tilde{C}^{XY}_{\ell, s}=\tilde{C}^{XY}_{\ell, s+n}-A_{\text{sn}}\tilde{N}^{XY}_\ell$
, making the galaxy clustering auto-correlation sensitive to non-flat contributions. Based on the
 $\sim$
20% difference that was found between the island and component number of sources by Norris et al. (Reference Norris2021) and as we consider other potential biases as described above, we deem reasonable to consider an informative prior in the range
$\sim$
20% difference that was found between the island and component number of sources by Norris et al. (Reference Norris2021) and as we consider other potential biases as described above, we deem reasonable to consider an informative prior in the range
 $A_{\text{sn}}\in(0.8, 1.2)$
, while we keep it fixed in the analytical covariance in Equation (14).
$A_{\text{sn}}\in(0.8, 1.2)$
, while we keep it fixed in the analytical covariance in Equation (14).
5.2. Measurements and detection significance
In the top left panel of Fig. 3, we show the measured signal for the auto-correlation spectra gg from the Selavy and PyBDSF catalogues for the flux density cut at
 $0.18$
mJy. With red points we denote Selavy and with blue points PyBDSF data, while the errorbars correspond to 1
$0.18$
mJy. With red points we denote Selavy and with blue points PyBDSF data, while the errorbars correspond to 1
 $\sigma$
uncertainties from the analytical covariance in Equation (15). The two catalogues are in agreement (within 1
$\sigma$
uncertainties from the analytical covariance in Equation (15). The two catalogues are in agreement (within 1
 $\sigma$
) until the scale
$\sigma$
) until the scale
 $\ell\sim 250$
, after which they start to deviate from each other. At
$\ell\sim 250$
, after which they start to deviate from each other. At
 $\ell \gtrsim 250$
, the PyBDSF data have more power than Selavy. This can be attributed to the existence of multi-structures at small scales which are considered to be different objects by PyBDSF, and if they are close enough, as a single larger object by Selavy, as already explained in Section 4.3. Therefore, we choose to apply a scale cut at
$\ell \gtrsim 250$
, the PyBDSF data have more power than Selavy. This can be attributed to the existence of multi-structures at small scales which are considered to be different objects by PyBDSF, and if they are close enough, as a single larger object by Selavy, as already explained in Section 4.3. Therefore, we choose to apply a scale cut at
 $\ell \leq 250$
, where the measurements from the two catalogues agree within
$\ell \leq 250$
, where the measurements from the two catalogues agree within
 $1\sigma$
, and neglect smaller scales, in which the two algorithms start to deviate and the disentangling between the multi-sources and multi-components is really hard. Then we use a theory model using the SKADS redshift distribution and the HALOFIT non-linear matter power spectrum leaving free the
$1\sigma$
, and neglect smaller scales, in which the two algorithms start to deviate and the disentangling between the multi-sources and multi-components is really hard. Then we use a theory model using the SKADS redshift distribution and the HALOFIT non-linear matter power spectrum leaving free the
 $b_g$
and
$b_g$
and
 $A_{\text{sn}}$
parameters and fixing
$A_{\text{sn}}$
parameters and fixing
 $\sigma_8$
in order to fit the Selavy and PyBDSF gg spectra alone (the theory fits are with orange and green curves, respectively). It turns out the models fitting the two catalogues agree very well with each other (with both models’ best-fit values differ at
$\sigma_8$
in order to fit the Selavy and PyBDSF gg spectra alone (the theory fits are with orange and green curves, respectively). It turns out the models fitting the two catalogues agree very well with each other (with both models’ best-fit values differ at
 $\lt 0.1\sigma$
within their posteriors).
$\lt 0.1\sigma$
within their posteriors).
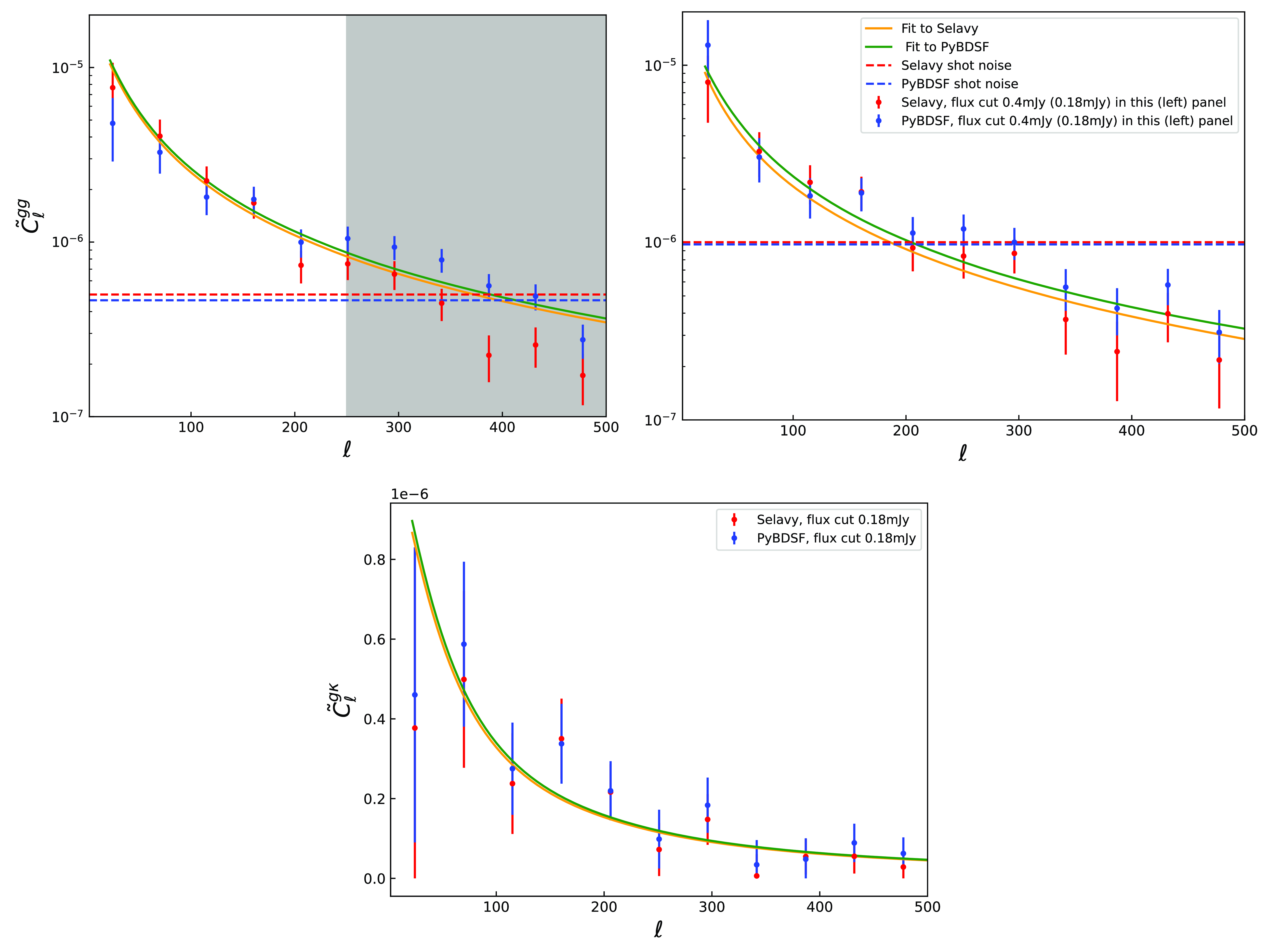
Figure 3. The auto-correlation
 $\tilde{C}^{gg}_\ell$
for the flux density cut at 0.18 (top left panel) and 0.4 mJy (top right panel). Red and blue points along with their 1
$\tilde{C}^{gg}_\ell$
for the flux density cut at 0.18 (top left panel) and 0.4 mJy (top right panel). Red and blue points along with their 1
 $\sigma$
uncertainties, correspond to the Selavy and PyBDSF catalogues. Their corresponding fitted theory models are denoted with orange and green curves, respectively, which are estimated assuming the Planck best-fit values (Planck Collaboration et al. 2020a), the SKADS redshift distribution and HALOFIT power spectrum. The colourful horizonal dashed lines are shot noise estimates for the two catalogues, and the grey shaded area (top left panel) denotes the scale cut at
$\sigma$
uncertainties, correspond to the Selavy and PyBDSF catalogues. Their corresponding fitted theory models are denoted with orange and green curves, respectively, which are estimated assuming the Planck best-fit values (Planck Collaboration et al. 2020a), the SKADS redshift distribution and HALOFIT power spectrum. The colourful horizonal dashed lines are shot noise estimates for the two catalogues, and the grey shaded area (top left panel) denotes the scale cut at
 $\ell=250$
for the flux density cut at 0.18 mJy. The bottom panel shows the cross-correlation of galaxies with the CMB lensing convergence
$\ell=250$
for the flux density cut at 0.18 mJy. The bottom panel shows the cross-correlation of galaxies with the CMB lensing convergence
 $\tilde{C}^{g\kappa}_\ell$
at the flux density cut 0.18 mJy.
$\tilde{C}^{g\kappa}_\ell$
at the flux density cut 0.18 mJy.
In the bottom panel of Fig. 3 we see the
 $g\kappa$
cross-spectra between the radio galaxies and the CMB convergence
$g\kappa$
cross-spectra between the radio galaxies and the CMB convergence
 $\kappa$
again for the two catalogues in a separate fit with
$\kappa$
again for the two catalogues in a separate fit with
 $g\kappa$
data alone. It is evident that the data agree at all scales now up to
$g\kappa$
data alone. It is evident that the data agree at all scales now up to
 $\ell=500$
(well within
$\ell=500$
(well within
 $1\sigma$
) and the theory models agree as well (again with both models’ best-fit values differ at
$1\sigma$
) and the theory models agree as well (again with both models’ best-fit values differ at
 $\lt 0.1\sigma$
within their posteriors).
$\lt 0.1\sigma$
within their posteriors).
Thus, in the main analysis of Sections 5.3 and 5.4 with the
 $0.18$
mJy flux density cut, we opt to use the scale range
$0.18$
mJy flux density cut, we opt to use the scale range
 $\ell\in(2, 250)$
for the auto-correlation gg
Footnote
e
and the full range
$\ell\in(2, 250)$
for the auto-correlation gg
Footnote
e
and the full range
 $\ell\in(2, 500)$
for the cross-correlation
$\ell\in(2, 500)$
for the cross-correlation
 $g\kappa$
. Also, since Selavy and PyBDSF agree at the scales we mentioned (as we saw at 1
$g\kappa$
. Also, since Selavy and PyBDSF agree at the scales we mentioned (as we saw at 1
 $\sigma$
), we proceed in the analysis of the main results of Sections 5.3 and 5.4 using the Selavy catalogue alone.
$\sigma$
), we proceed in the analysis of the main results of Sections 5.3 and 5.4 using the Selavy catalogue alone.
We quantify the significance of detection as:
 $\text{SNR}=\sqrt{\chi^2_{\text{null}}-\chi^2_{b.f.}}$
, in terms of
$\text{SNR}=\sqrt{\chi^2_{\text{null}}-\chi^2_{b.f.}}$
, in terms of
 $\sigma$
, where
$\sigma$
, where
 $\chi^2_{\text{null}}$
is the
$\chi^2_{\text{null}}$
is the
 $\chi^2$
of the null hypothesis (zero theory vector) and
$\chi^2$
of the null hypothesis (zero theory vector) and
 $\chi^2_{\text{b.f.}}$
the best-fit model
$\chi^2_{\text{b.f.}}$
the best-fit model
 $\chi^2$
. Regarding the scale cut at
$\chi^2$
. Regarding the scale cut at
 $\ell=250$
for gg, most of the signal is at
$\ell=250$
for gg, most of the signal is at
 $\ell\lt 250$
, since there, we obtain a detection of
$\ell\lt 250$
, since there, we obtain a detection of
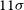 $11\sigma$
, while at the full scale range the detection is
$11\sigma$
, while at the full scale range the detection is
 $14 \sigma$
. The cross-correlation
$14 \sigma$
. The cross-correlation
 $g\kappa$
detection significance up to
$g\kappa$
detection significance up to
 $\ell=500$
is
$\ell=500$
is
 $5.5\sigma$
.
$5.5\sigma$
.
We repeat the same for the more conservative flux density cut at
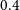 $0.4$
mJy and show the results for the gg in the top right panel of Fig. 3. Now, the catalogues agree with each other at the full scale range up to
$0.4$
mJy and show the results for the gg in the top right panel of Fig. 3. Now, the catalogues agree with each other at the full scale range up to
 $\ell=500$
always within 1
$\ell=500$
always within 1
 $\sigma$
, even though PyBDSF has again slightly (
$\sigma$
, even though PyBDSF has again slightly (
 $\sim0.5\sigma$
) more power than Selavy at small scales. This is further confirmed by the theoretical models which yield consistent results. Therefore, we opt to use the full scale range for gg and use the Selavy catalogue alone for the galaxy bias and cosmology analysis of Section 5. At this point, we mention that the agreement we see now at the flux density cut
$\sim0.5\sigma$
) more power than Selavy at small scales. This is further confirmed by the theoretical models which yield consistent results. Therefore, we opt to use the full scale range for gg and use the Selavy catalogue alone for the galaxy bias and cosmology analysis of Section 5. At this point, we mention that the agreement we see now at the flux density cut
 $0.4$
mJy between the catalogues can be attributed to the fact that we consider a more conservative galaxy sample which at the same time contains less galaxies (and in turn, larger uncertainties inflating the errorbars) than the sample with flux density cut at
$0.4$
mJy between the catalogues can be attributed to the fact that we consider a more conservative galaxy sample which at the same time contains less galaxies (and in turn, larger uncertainties inflating the errorbars) than the sample with flux density cut at
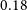 $0.18$
mJy (see Section 3.1.1). Regarding, the cross-correlation spectra
$0.18$
mJy (see Section 3.1.1). Regarding, the cross-correlation spectra
 $g\kappa$
for the flux density cut at
$g\kappa$
for the flux density cut at
 $0.4$
mJy, we find very similar results at the whole scale range with those obtained at
$0.4$
mJy, we find very similar results at the whole scale range with those obtained at
 $0.18$
mJy and therefore we do not show them in the panel to avoid repetition. The cross-correlation detection significance for
$0.18$
mJy and therefore we do not show them in the panel to avoid repetition. The cross-correlation detection significance for
 $0.4$
mJy is
$0.4$
mJy is
 $5.4\sigma$
$5.4\sigma$
5.3. Constraints on galaxy bias
By using the measurements and scale cuts discussed in Section 5.2, first we present the constraints on the galaxy bias
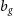 $b_g$
while we fix the cosmological parameters, including
$b_g$
while we fix the cosmological parameters, including
 $\sigma_8$
, to the Planck Collaboration et al. (2020a) best-fit values (see again Section 4.2). The results are shown in the left panel of Fig. 4 and the values are in Tables C1–C4. For our baseline results here we assume the SKADS distribution. We also repeated the analysis with the T-RECS distribution and the results are in agreement with those using SKADS finding a shift at most of
$\sigma_8$
, to the Planck Collaboration et al. (2020a) best-fit values (see again Section 4.2). The results are shown in the left panel of Fig. 4 and the values are in Tables C1–C4. For our baseline results here we assume the SKADS distribution. We also repeated the analysis with the T-RECS distribution and the results are in agreement with those using SKADS finding a shift at most of
 $\sim0.5\sigma$
for the 0.18 mJy flux density cut and the constant galaxy bias (lower galaxy bias values and higher
$\sim0.5\sigma$
for the 0.18 mJy flux density cut and the constant galaxy bias (lower galaxy bias values and higher
 $\sigma_8$
values with T-RECS) and even less for the rest of the cases. Therefore, we show the T-RECS results and how they compare to SKADS ones in detail in Appendix C.
$\sigma_8$
values with T-RECS) and even less for the rest of the cases. Therefore, we show the T-RECS results and how they compare to SKADS ones in detail in Appendix C.
Figure 4.
Left: The best-fit values along with their 68% confidence intervals on the galaxy bias parameter
 $b_g$
for the auto-correlation
$b_g$
for the auto-correlation
 $\tilde{C}^{gg}$
, the cross-correlation
$\tilde{C}^{gg}$
, the cross-correlation
 $\tilde{C}^{g\kappa}$
and their combination
$\tilde{C}^{g\kappa}$
and their combination
 $\tilde{C}^{gg}+\tilde{C}^{g\kappa}$
, assuming the redshift distribution SKADS, a linear (denoted with ‘lin’) and HALOFIT power spectrum (denoted with ‘nl’), and fixing the cosmology to the fiducial values. Blue (orange) errorbars correspond to the flux density cut 0.18 (0.4) mJy and solid (dashed) lines to the constant bias model (constant amplitude model). Right: Same as in the left panel but now for the
$\tilde{C}^{gg}+\tilde{C}^{g\kappa}$
, assuming the redshift distribution SKADS, a linear (denoted with ‘lin’) and HALOFIT power spectrum (denoted with ‘nl’), and fixing the cosmology to the fiducial values. Blue (orange) errorbars correspond to the flux density cut 0.18 (0.4) mJy and solid (dashed) lines to the constant bias model (constant amplitude model). Right: Same as in the left panel but now for the
 $\sigma_8$
constraints on the combined spectra. The bottom lines present the Planck (Planck Collaboration et al. 2020a), DES (Abbott et al. Reference Abbott2022) and KiDS (Heymans, Catherine et al. 2021) measurements with red, magenta and green color, respectively.
$\sigma_8$
constraints on the combined spectra. The bottom lines present the Planck (Planck Collaboration et al. 2020a), DES (Abbott et al. Reference Abbott2022) and KiDS (Heymans, Catherine et al. 2021) measurements with red, magenta and green color, respectively.
In the left panel of Fig. 4, we report the constant galaxy bias best fit and 68% confidence interval model constraints with blue solid lines for the flux density cut at
 $0.18$
mJy. We find that the auto-correlation gives higher bias than the cross-correlation by
$0.18$
mJy. We find that the auto-correlation gives higher bias than the cross-correlation by
 $\sim 1\sigma$
, while the combination of the two gives intermediate estimates. In all these results the linear model yields higher bias values than HALOFIT by
$\sim 1\sigma$
, while the combination of the two gives intermediate estimates. In all these results the linear model yields higher bias values than HALOFIT by
 $\sim0.5\sigma$
to compensate for the smaller power at the mildly non-linear regime. Also, we do not observe deviations from the shot noise estimates given the reported constraints on the nuisance amplitude parameter
$\sim0.5\sigma$
to compensate for the smaller power at the mildly non-linear regime. Also, we do not observe deviations from the shot noise estimates given the reported constraints on the nuisance amplitude parameter
 $A_{\text{sn}}$
, verifying in this way that there is no evidence of multi-component contamination in the Selavy island catalogue we use. Additionally, it could mean that our low density sample is not affected by other contributions like halo exclusion. Regarding the goodness of fit, we report reduced
$A_{\text{sn}}$
, verifying in this way that there is no evidence of multi-component contamination in the Selavy island catalogue we use. Additionally, it could mean that our low density sample is not affected by other contributions like halo exclusion. Regarding the goodness of fit, we report reduced
 $\chi^2$
(
$\chi^2$
(
 $\chi^2_\nu$
), defined as,
$\chi^2_\nu$
), defined as,
 $\chi^2_\nu=\chi^2_{\text{min}}/\nu$
, with
$\chi^2_\nu=\chi^2_{\text{min}}/\nu$
, with
 $\chi^2_{\text{min}}$
the
$\chi^2_{\text{min}}$
the
 $\chi^2$
of the best-fit value and
$\chi^2$
of the best-fit value and
 $\nu$
the degrees of freedom which is the number of our measurements minus the number of fitted parameters. We also report the ‘probability to exceed’ which is defined as
$\nu$
the degrees of freedom which is the number of our measurements minus the number of fitted parameters. We also report the ‘probability to exceed’ which is defined as
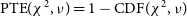 $\text{PTE}(\chi^2,\nu)=1-\text{CDF}(\chi^2,\nu)$
, where CDF is the cumulative distribution of
$\text{PTE}(\chi^2,\nu)=1-\text{CDF}(\chi^2,\nu)$
, where CDF is the cumulative distribution of
 $\chi^2$
. Overall, all the measurements provide good fits to the data at
$\chi^2$
. Overall, all the measurements provide good fits to the data at
 $\chi^2_\nu \sim 1$
(or equialently a PTE of 10–90%) with the auto-correlation results giving worse
$\chi^2_\nu \sim 1$
(or equialently a PTE of 10–90%) with the auto-correlation results giving worse
 $\chi^2_\nu$
than the cross-correlation and the combined ones (see Table C1). We opt to report in the text for clarity (and do so for the rest of the galaxy models and flux density cuts in the paragraphs below) only the combined measurements
$\chi^2_\nu$
than the cross-correlation and the combined ones (see Table C1). We opt to report in the text for clarity (and do so for the rest of the galaxy models and flux density cuts in the paragraphs below) only the combined measurements
 $(gg+g\kappa)$
galaxy bias values from SKADS for the HALOFIT model, which is
$(gg+g\kappa)$
galaxy bias values from SKADS for the HALOFIT model, which is
 $b_g=2.32^{+0.41}_{-0.33}$
. The rest of the results are shown Table C1.
$b_g=2.32^{+0.41}_{-0.33}$
. The rest of the results are shown Table C1.
Turing our attention to the constant amplitude model results (see values at Table C2), which are shown with dashed blue lines of the left panel of Fig. 4, the aspects we discussed for the constant galaxy bias model, apply similarly here. However, the constraints on the amplitude parameter are lower than the simple constant bias, as expected, since we now take into account the growth evolution with redshift in the bias model (see again Section 4.2). We quote here the combined measurement galaxy bias estimate from SKADS for HALOFIT as
 $b_g=1.72^{+0.31}_{-0.21}$
.
$b_g=1.72^{+0.31}_{-0.21}$
.
The same picture concerning the differences between the linear and non-linear power spectrum recipes also applies for the constant galaxy bias model constraints at the more conservative flux density cut of
 $0.4$
mJy (see Table C3) presented with the solid orange lines in the left panel of Fig. 4. Although in this sample we have fewer radio galaxies than for the flux density cut at
$0.4$
mJy (see Table C3) presented with the solid orange lines in the left panel of Fig. 4. Although in this sample we have fewer radio galaxies than for the flux density cut at
 $0.18$
mJy (see again Section 3.1.1 for the reported number of sources), at the same time at the
$0.18$
mJy (see again Section 3.1.1 for the reported number of sources), at the same time at the
 $0.4$
mJy flux density cut we consider scales up to
$0.4$
mJy flux density cut we consider scales up to
 $\ell=500$
and do not cut at
$\ell=500$
and do not cut at
 $\ell=250$
as we do for the less conservative cut, gaining in this way more constraining power. Thus, the resulting constraints shrink by up to
$\ell=250$
as we do for the less conservative cut, gaining in this way more constraining power. Thus, the resulting constraints shrink by up to
 $\sim$
30% for the auto-correlation. It is noteworthy that this increase of the constraining power that we see in the galaxy bias using the brighter and less dense sample (0.4 mJy) compared to the fainter one (0.18 mJy) may be a critical point for future radio continuum data which consider auto-correlations. This can be clearly seen by the fact that the increase of uncertainty of the power spectrum per multipole can be overcompensated by pushing more towards smaller scales which we can still trust given the agreement between the different catalogues (Selavy and PyBDSF, see again Fig. 3), leading this way to tighter parameter constraints.Footnote
f
We should also mention that apart from the larger errorbars in the brighter sample, also the measurements themselves are in better agreement (between Selavy and PyBDSF at
$\sim$
30% for the auto-correlation. It is noteworthy that this increase of the constraining power that we see in the galaxy bias using the brighter and less dense sample (0.4 mJy) compared to the fainter one (0.18 mJy) may be a critical point for future radio continuum data which consider auto-correlations. This can be clearly seen by the fact that the increase of uncertainty of the power spectrum per multipole can be overcompensated by pushing more towards smaller scales which we can still trust given the agreement between the different catalogues (Selavy and PyBDSF, see again Fig. 3), leading this way to tighter parameter constraints.Footnote
f
We should also mention that apart from the larger errorbars in the brighter sample, also the measurements themselves are in better agreement (between Selavy and PyBDSF at
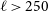 $\ell\gt 250$
), which could be indicative of a possible mitigation of the source finding problem for brighter and denser radio samples. Going now back to the results, for this flux density cut, the auto-correlation and the combined measurements galaxy bias estimates are now lower, while the cross-correlation alone estimates are larger than the results with the previous less conservative flux density cut. Here, the reported combined measurement estimate of the galaxy bias from SKADS for HALOFIT reads
$\ell\gt 250$
), which could be indicative of a possible mitigation of the source finding problem for brighter and denser radio samples. Going now back to the results, for this flux density cut, the auto-correlation and the combined measurements galaxy bias estimates are now lower, while the cross-correlation alone estimates are larger than the results with the previous less conservative flux density cut. Here, the reported combined measurement estimate of the galaxy bias from SKADS for HALOFIT reads
 $b_g=2.18^{+0.17}_{-0.25}$
.
$b_g=2.18^{+0.17}_{-0.25}$
.
Finally, we display the constraints for the constant amplitude galaxy bias at
 $0.4$
mJy (see Table C4) which correspond to the dashed orange lines of the left panel of Fig. 4. The trends in the results here for the various modelling assumptions are again consistent with the picture seen for the same galaxy model at
$0.4$
mJy (see Table C4) which correspond to the dashed orange lines of the left panel of Fig. 4. The trends in the results here for the various modelling assumptions are again consistent with the picture seen for the same galaxy model at
 $0.18$
mJy, with two noteworthy differences. The first is that the auto-correlation constraints remain about the same irrespective of the flux density cut and the combined spectra results give slightly higher bias at the 0.4 mJy cut. Now, the combined data assuming SKADS and HALOFIT give
$0.18$
mJy, with two noteworthy differences. The first is that the auto-correlation constraints remain about the same irrespective of the flux density cut and the combined spectra results give slightly higher bias at the 0.4 mJy cut. Now, the combined data assuming SKADS and HALOFIT give
 $b_g=1.78^{+0.22}_{-0.15}$
.
$b_g=1.78^{+0.22}_{-0.15}$
.
In Fig. 5 we show the best-fit and the 68% confidence intervals on the constant galaxy bias and the constant amplitude model as a function of redshift for our combined spectra with the linear and HALOFIT power spectrum and assuming a SKADS redshift distribution at the flux density cut of
 $0.18$
mJy (the results are also very similar with the other flux density cut at
$0.18$
mJy (the results are also very similar with the other flux density cut at
 $0.4$
mJy). We also illustrate the bias measurements from different and mixed populations of galaxies found in other radio continuum works in the literature (Nusser & Tiwari Reference Nusser and Tiwari2015; Hale et al. Reference Hale, Jarvis, Delvecchio, Hatfield, Novak, Smolčić and Zamorani2017; Alonso et al. Reference Alonso, Bellini, Hale, Jarvis and Schwarz2021; Hale et al. Reference Hale2023; Nakoneczny et al. 2024, see caption for details), though a direct comparison with them is impossible due to the different combinations of spectra assumed as well as the different effective flux density limits. However, the results slightly hint that the our constant amplitude model for the galaxy bias is a better description for the deep radio continuum galaxy data compared to the constant redshift-independent model. In order to compare the galaxy bias values of the constant galaxy bias and the constant amplitude model we estimate the constant amplitude constraints at the effective redshift of the SKADS and T-RECS distributions and report them as an extra column (see second column of Tables C2 and C4). By comparing the results of the constant amplitude model at the effective redshift with the constant one, we see that the values are higher. This is not surprising given that the constant amplitude model accounts for the linear growth factor whose inverse is greater than unity at high redshifts.
$0.4$
mJy). We also illustrate the bias measurements from different and mixed populations of galaxies found in other radio continuum works in the literature (Nusser & Tiwari Reference Nusser and Tiwari2015; Hale et al. Reference Hale, Jarvis, Delvecchio, Hatfield, Novak, Smolčić and Zamorani2017; Alonso et al. Reference Alonso, Bellini, Hale, Jarvis and Schwarz2021; Hale et al. Reference Hale2023; Nakoneczny et al. 2024, see caption for details), though a direct comparison with them is impossible due to the different combinations of spectra assumed as well as the different effective flux density limits. However, the results slightly hint that the our constant amplitude model for the galaxy bias is a better description for the deep radio continuum galaxy data compared to the constant redshift-independent model. In order to compare the galaxy bias values of the constant galaxy bias and the constant amplitude model we estimate the constant amplitude constraints at the effective redshift of the SKADS and T-RECS distributions and report them as an extra column (see second column of Tables C2 and C4). By comparing the results of the constant amplitude model at the effective redshift with the constant one, we see that the values are higher. This is not surprising given that the constant amplitude model accounts for the linear growth factor whose inverse is greater than unity at high redshifts.
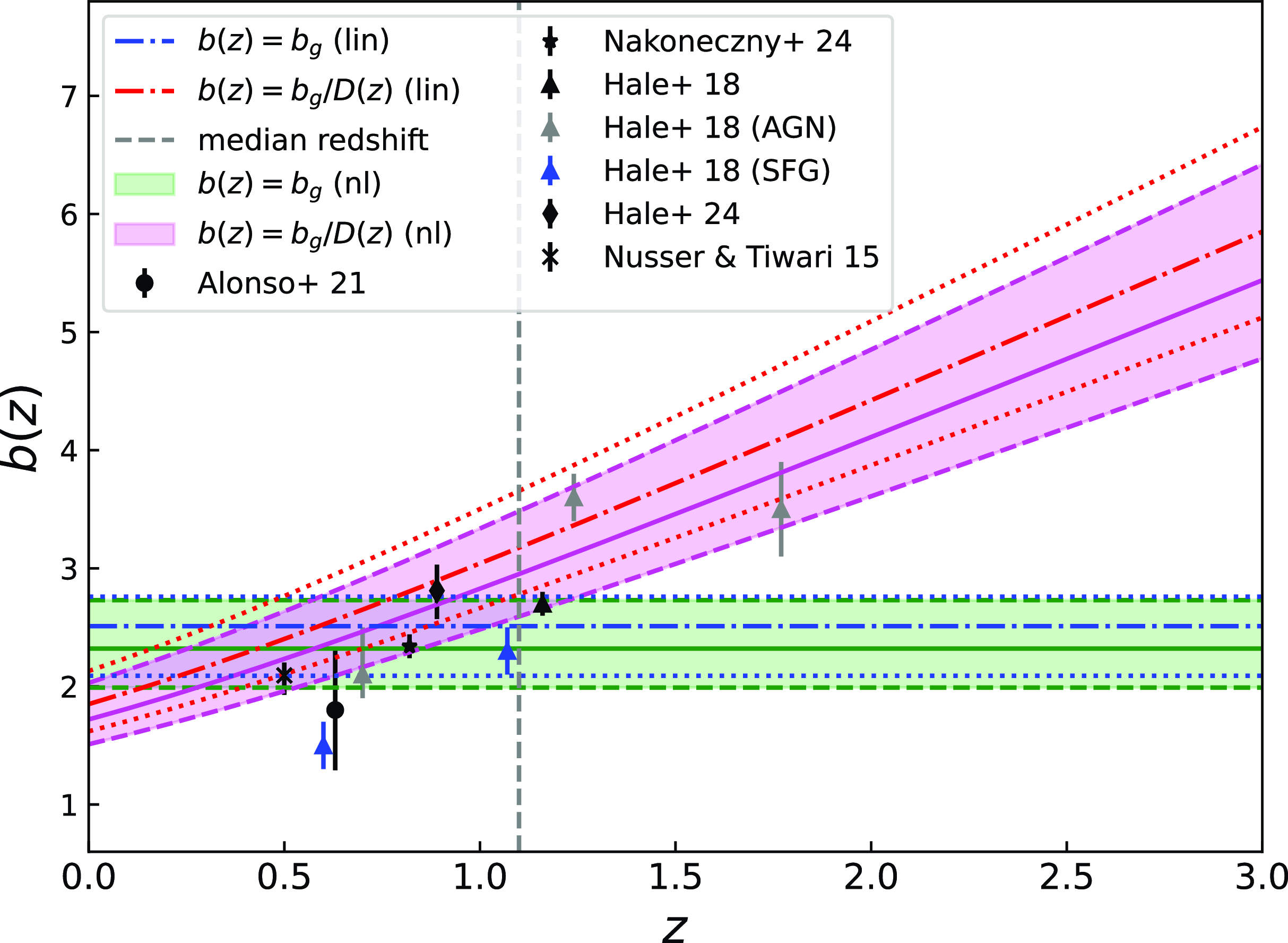
Figure 5. Best-fit values along with the 68% confidence interval constraints on the constant bias (green and blue) and constant amplitude (magenta and red) model for the combined spectra
 $\tilde{C}^{gg}+\tilde{C}^{g\kappa}$
assuming a SKADS distribution, a HALOFIT (filled intervals) as well as a linear (empty intervals) spectrum and a flux density cut at 0.18 mJy. The errorbars with the different marker styles represent galaxy bias measurements from different radio galaxy surveys in the literature. Grey and blue triangular markers correspond to AGN and SFG constraints as from H18 (Hale et al. Reference Hale, Jarvis, Delvecchio, Hatfield, Novak, Smolčić and Zamorani2017) while the black triangular marker to the combined sample in the same work. The rest of the different shape black markers show mixed populations from the works (Nusser & Tiwari Reference Nusser and Tiwari2015; Hale et al. Reference Hale, Jarvis, Delvecchio, Hatfield, Novak, Smolčić and Zamorani2017; Alonso et al. Reference Alonso, Bellini, Hale, Jarvis and Schwarz2021; Hale et al. Reference Hale2023; Nakoneczny et al. 2024). The vertical dashed line is the median redshift of the sample.
$\tilde{C}^{gg}+\tilde{C}^{g\kappa}$
assuming a SKADS distribution, a HALOFIT (filled intervals) as well as a linear (empty intervals) spectrum and a flux density cut at 0.18 mJy. The errorbars with the different marker styles represent galaxy bias measurements from different radio galaxy surveys in the literature. Grey and blue triangular markers correspond to AGN and SFG constraints as from H18 (Hale et al. Reference Hale, Jarvis, Delvecchio, Hatfield, Novak, Smolčić and Zamorani2017) while the black triangular marker to the combined sample in the same work. The rest of the different shape black markers show mixed populations from the works (Nusser & Tiwari Reference Nusser and Tiwari2015; Hale et al. Reference Hale, Jarvis, Delvecchio, Hatfield, Novak, Smolčić and Zamorani2017; Alonso et al. Reference Alonso, Bellini, Hale, Jarvis and Schwarz2021; Hale et al. Reference Hale2023; Nakoneczny et al. 2024). The vertical dashed line is the median redshift of the sample.
Additionally, it is important to note that one would expect a higher galaxy bias value for a brighter sample (
 $0.4$
mJy) than a fainter one (
$0.4$
mJy) than a fainter one (
 $0.18$
mJy) given that the brighter more luminous sources reside in more massive halos which have larger bias. However, it could be that the fainter sample contains more high-redshift sources which naturally have larger galaxy bias. The latter, could explain our findings here and they agree with the results of Nakoneczny et al. (2024). In any case, further studies would be needed to investigate this.
$0.18$
mJy) given that the brighter more luminous sources reside in more massive halos which have larger bias. However, it could be that the fainter sample contains more high-redshift sources which naturally have larger galaxy bias. The latter, could explain our findings here and they agree with the results of Nakoneczny et al. (2024). In any case, further studies would be needed to investigate this.
A crucial point here is that similarly to the uncertainties in the redshift distribution, there exist uncertainties on the validity of the linear galaxy bias models we employ (constant galaxy bias and constant amplitude). These stem from the fact that the redshift distribution of radio samples, though broad enough and extending to high redshift with long tails where linearity can be assumed, they still start near redshift zero, where non-linearities enter even in the larger scales (since smaller physical scales of nearby structures look larger in the sky). This should be kept in mind given the slight differences we see when we compare results from the different galaxy bias models and the linear and the non-linear matter power spectrum recipes we use. Nevertheless, we can safely assume that the impact of non-linearities in our analysis is small, a fact that can be supported by the agreement of the constraints within
 $1\sigma$
(see again Fig. 5). In subsequent future works, and as the number density of the EMU sample will increase as well as its sky coverage and constraining power, we will investigate these effects in more detail by considering non-linear galaxy bias models and pushing to smaller angular scales (
$1\sigma$
(see again Fig. 5). In subsequent future works, and as the number density of the EMU sample will increase as well as its sky coverage and constraining power, we will investigate these effects in more detail by considering non-linear galaxy bias models and pushing to smaller angular scales (
 $\ell\gt 500$
).
$\ell\gt 500$
).
5.4. Constraints on
$\sigma_8$

Now, we place constraints on the
 $\sigma_8$
parameter by leaving it free during the fitting, and we do this for the combined measurements
$\sigma_8$
parameter by leaving it free during the fitting, and we do this for the combined measurements
 $gg+g\kappa$
in order to break the degeneracy between the galaxy bias
$gg+g\kappa$
in order to break the degeneracy between the galaxy bias
 $b_g$
and
$b_g$
and
 $\sigma_8$
. We assume for our baseline the SKADS distribution. Also, we consider the different cuts and the models we discussed in Section 5.3. The results are shown from Tables C1 to C4 in the row denoted with ‘
$\sigma_8$
. We assume for our baseline the SKADS distribution. Also, we consider the different cuts and the models we discussed in Section 5.3. The results are shown from Tables C1 to C4 in the row denoted with ‘
 $gg+g\kappa (\sigma_8 \text{ free})$
’ and in the right panel of Fig. 4. For completeness, in Fig. C2 of the Appendix C, we present the marginalised posterior contours along with their 68% and 95% confidence intervals and the one-dimensional posteriors for the
$gg+g\kappa (\sigma_8 \text{ free})$
’ and in the right panel of Fig. 4. For completeness, in Fig. C2 of the Appendix C, we present the marginalised posterior contours along with their 68% and 95% confidence intervals and the one-dimensional posteriors for the
 $b_g$
,
$b_g$
,
 $\sigma_8$
and
$\sigma_8$
and
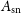 $A_{\text{sn}}$
.
$A_{\text{sn}}$
.
Overall, the constraints are not competitive due to the low density sample we consider here, the small sky coverage and the large uncertainties in the redshift distribution. Nonetheless, this work serves as a sanity check and a complementary cosmological constraint on one hand and on the other hand, it demonstrates the potential of the full EMU survey and also of other radio continuum galaxy surveys for cosmological studies (similar to Alonso et al. Reference Alonso, Bellini, Hale, Jarvis and Schwarz2021; Nakoneczny et al. 2024 and Piccirilli et al. 2023).
Regarding the results themselves and focusing on the flux density cut at
 $0.18$
mJy and the constant bias model, we show its constraints with solid blue lines in the right panel of Fig. 4 (see also top left figure of the contour plot in Fig. C2). We report here the best-fit value using HALOFIT and SKADS, which gives
$0.18$
mJy and the constant bias model, we show its constraints with solid blue lines in the right panel of Fig. 4 (see also top left figure of the contour plot in Fig. C2). We report here the best-fit value using HALOFIT and SKADS, which gives
 $\sigma_8=0.68^{+0.16}_{-0.14}$
. The measurements obtained with the linear and the non-linear HALOFIT are in agreement with each other. Also, they agree with the Planck (Planck Collaboration et al. 2020a), DES (Abbott et al. Reference Abbott2022) and KiDS (Heymans et al. 2021) measurements. We note that we observe a trend for lower
$\sigma_8=0.68^{+0.16}_{-0.14}$
. The measurements obtained with the linear and the non-linear HALOFIT are in agreement with each other. Also, they agree with the Planck (Planck Collaboration et al. 2020a), DES (Abbott et al. Reference Abbott2022) and KiDS (Heymans et al. 2021) measurements. We note that we observe a trend for lower
 $\sigma_8$
values, although they are consistent with the other surveys’ results at
$\sigma_8$
values, although they are consistent with the other surveys’ results at
 $1\sigma$
. The linear model estimates can be found in Table C1.
$1\sigma$
. The linear model estimates can be found in Table C1.
Turning now to the dashed blue lines of the right panel of Fig. 4, we see the constant amplitude model constraints at the same flux density cut. Here the
 $\sigma_8$
estimates are sightly lower compared to the constant bias results enhancing marginally the preference for lower
$\sigma_8$
estimates are sightly lower compared to the constant bias results enhancing marginally the preference for lower
 $\sigma_8$
, but again remain consistent within
$\sigma_8$
, but again remain consistent within
 $1\sigma$
with the estimates from the other surveys. The result for HALOFIT is
$1\sigma$
with the estimates from the other surveys. The result for HALOFIT is
 $\sigma_8=0.61^{+0.18}_{-0.20}$
. The exact values for the rest of the models are shown in Table C2 and the marginalised contours are presented in the top right panel of Fig. C2.
$\sigma_8=0.61^{+0.18}_{-0.20}$
. The exact values for the rest of the models are shown in Table C2 and the marginalised contours are presented in the top right panel of Fig. C2.
Concerning the results of the constant galaxy bias model at
 $0.4$
mJy, these are shown with solid orange lines in the right panel of Fig. 4 (see Table C3 and bottom left panel of Fig. C2 for the results of all the models). Now, the most striking difference compared to the results obtained at
$0.4$
mJy, these are shown with solid orange lines in the right panel of Fig. 4 (see Table C3 and bottom left panel of Fig. C2 for the results of all the models). Now, the most striking difference compared to the results obtained at
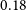 $0.18$
mJy, is that the
$0.18$
mJy, is that the
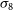 $\sigma_8$
is higher, although still consistent at 1
$\sigma_8$
is higher, although still consistent at 1
 $\sigma$
. We report the
$\sigma$
. We report the
 $\sigma_8$
result with HALOFIT which is
$\sigma_8$
result with HALOFIT which is
 $0.82\pm0.10$
, centered on the Planck result.
$0.82\pm0.10$
, centered on the Planck result.
Finally, the picture for the constant amplitude model at the
 $0.4$
mJy flux density cut is as expected and consistent with what we described for the variety of models before. These constraints are shown with dashed orange lines in the right panel of Fig. 4. The SKADS result for HALOFIT is
$0.4$
mJy flux density cut is as expected and consistent with what we described for the variety of models before. These constraints are shown with dashed orange lines in the right panel of Fig. 4. The SKADS result for HALOFIT is
 $\sigma_8=0.78^{+0.11}_{-0.09}$
(linear model values in Table C4 and the variety of models again shown in the bottom right panel of Fig. C2). The higher estimated value and the increased constraining power for
$\sigma_8=0.78^{+0.11}_{-0.09}$
(linear model values in Table C4 and the variety of models again shown in the bottom right panel of Fig. C2). The higher estimated value and the increased constraining power for
 $\sigma_8$
when a more conservative flux density cut is applied are related to the opposite behavior of the galaxy bias and the reasons we discussed, respectively in Section 5.3. The higher galaxy bias values for brighter samples has also been seen by Nakoneczny et al. (2024), however, we cannot make a direct comparison with their work, since it concerned an analysis using a denser radio continuum sample of the LoTSS survey (Shimwell et al. Reference Shimwell2019) and also applied different flux density cuts.
$\sigma_8$
when a more conservative flux density cut is applied are related to the opposite behavior of the galaxy bias and the reasons we discussed, respectively in Section 5.3. The higher galaxy bias values for brighter samples has also been seen by Nakoneczny et al. (2024), however, we cannot make a direct comparison with their work, since it concerned an analysis using a denser radio continuum sample of the LoTSS survey (Shimwell et al. Reference Shimwell2019) and also applied different flux density cuts.
Another important point, is the performance of T-RECS compared to the SKADS. Although we discuss the comparison between them in detail in Appendix C, it is interesting to mention here, that similarly to what we saw for the galaxy bias also applies on
 $\sigma_8$
but with an opposite behavior. By looking at the right panel of Fig. C1, it is evident that the different redshift distributions can yield up to
$\sigma_8$
but with an opposite behavior. By looking at the right panel of Fig. C1, it is evident that the different redshift distributions can yield up to
 $\sim0.5\sigma$
parameter shift, assuming a constant galaxy bias model and the 0.18 mJy flux density cut.
$\sim0.5\sigma$
parameter shift, assuming a constant galaxy bias model and the 0.18 mJy flux density cut.
6. Conclusions
In this work we measured the galaxy clustering auto-correlation harmonic-space power spectrum of the EMU PS1 data and its cross-correlation with the CMB lensing convergence from Planck PR4. Then we used these spectra in order to place constraints on the galaxy bias
 $b_g$
and the amplitude of matter fluctuations
$b_g$
and the amplitude of matter fluctuations
 $\sigma_8$
.
$\sigma_8$
.
We studied this for a variety of models. First, we included in our theoretical modelling a linear and a non-linear matter power spectrum using HALOFIT and linear to mildly non-linear scale range from
 $\ell=2$
to 500. We also used the redshift distribution from the SKADS simulation in our baseline analysis since we found that using the T-RECS distribution gives consistent results. Then, we assumed two galaxy bias models: a constant redshift-independent galaxy bias
$\ell=2$
to 500. We also used the redshift distribution from the SKADS simulation in our baseline analysis since we found that using the T-RECS distribution gives consistent results. Then, we assumed two galaxy bias models: a constant redshift-independent galaxy bias
 $b(z)=b_g$
, and a constant amplitude galaxy bias
$b(z)=b_g$
, and a constant amplitude galaxy bias
 $b(z)=b_g/D(z)$
, with D(z) the linear growth factor, which accounts for the redshift evolution of the clustering of radio galaxies.
$b(z)=b_g/D(z)$
, with D(z) the linear growth factor, which accounts for the redshift evolution of the clustering of radio galaxies.
For the data, we considered a flux density cut at
 $0.18$
mJy and an alternative more strict cut at
$0.18$
mJy and an alternative more strict cut at
 $0.4$
mJy, while we used the Selavy and PyBDSF as our source detection algorithms. After we constructed the weight maps for the two catalogues and propagated their effect in a pseudo-
$0.4$
mJy, while we used the Selavy and PyBDSF as our source detection algorithms. After we constructed the weight maps for the two catalogues and propagated their effect in a pseudo-
 $C_\ell$
analysis, we fitted our data with our theory models in order to put constraints on
$C_\ell$
analysis, we fitted our data with our theory models in order to put constraints on
 $b_g$
and
$b_g$
and
 $\sigma_8$
. This was achieved with an MCMC analysis and using a Gaussian covariance matrix. Below we summarise the most important results we found:
$\sigma_8$
. This was achieved with an MCMC analysis and using a Gaussian covariance matrix. Below we summarise the most important results we found:
-
• The auto-correlation spectra for EMU PS1 using the Selavy and PyBDSF detection algorithms start to deviate significantly (more than our measurement errors) for
$\ell \gtrsim 250$
at the
$0.18$
mJy flux density cut. This is due to the fact that the former algorithm categorises large structures as single objects, while the latter categorises possible sub-structures near a main object as different objects. This way, more detected sources lead to a higher power spectrum as measured by PyBDSF. Nonetheless, since both algorithms could be right or wrong on this aspect (finding false negatives or false positives), we ignore scales above 250. To account for any residual uncertainty remaining on the number of sources, we add an extra shot-noise parameter
$A_{\text{sn}}$
in our modelling. We did not report any difference for the
$0.4$
mJy flux density cut where we kept all the scale range a fact that resulted later in increasing the constraining power by
$\sim 30\%$
on galaxy bias and
$\sigma_8$
. -
• We found a
$\sim$
5.5
$\sigma$
detection between the EMU PS1 and the CMB lensing independent of flux density cut. -
• At the scale regime where our algorithms agreed, we chose Selavy for our baseline analysis and we placed constraints on the galaxy bias by fixing the cosmological parameters using auto-correlation, cross-correlation spectra and their combination. All the different models and flux density cuts yield consistent results. We found that there is a shift of
$\sim0.5\sigma$
depending on the linear and non-linear HALOFIT matter power spectrum which is a systematic effect, related to the non-linear galaxy bias modelling. Assuming a HALOFIT model and the
$0.18$
mJy (
$0.4$
mJy) flux density cut on the combined spectra, we report a constant galaxy bias of
$b_g=2.32^{+0.41}_{-0.33}$
(
$b_g=2.18^{+0.17}_{-0.25}$
) and a constant amplitude galaxy bias of
$b_g=1.72^{+0.31}_{-0.21}$
(
$b_g=1.78^{+0.22}_{-0.15}$
). -
• After freeing
$\sigma_8$
for the same theory model and flux density cut choices we found
$\sigma_8=0.68^{+0.16}_{-0.14}$
for the constant bias and
$\sigma_8=0.61^{+0.18}_{-0.20}$
for the constant amplitude model. These values increase slightly for the
$0.4$
mJy flux density cut at
$\sigma_8=0.82\pm0.10$
and
$\sigma_8=0.78^{+0.11}_{-0.09}$
, respectively. These values are in very good agreement with the Planck CMB measurements (Planck Collaboration et al. 2020a), and the weak lensing surveys of Dark Energy Survey (DES; Abbott et al. Reference Abbott2022) and Kilo Degree Survey (KiDS; Heymans et al. 2021).





















This paper highlights the possibility to break the degeneracy between the galaxy bias
 $b_g$
and the amplitude of the matter fluctuations
$b_g$
and the amplitude of the matter fluctuations
 $\sigma_8$
by using auto-correlation and cross-correlation of the radio continuum galaxy sample from the EMU PS1 with the CMB lensing convergence as from Planck PR4. The largest bottleneck for the deep radio continuum samples remains the insufficient information on their redshift distribution. There is ongoing work on the cross-correlation of EMU PS1 data with optical galaxies from DES dealing with the modelling of the redshift distribution (Saraf et al. Reference Saraf, Parkinson, Asorey, Hale, Bahr-Kalus, Camera and Tanidis2025). In coming years there will be more data covering a larger fraction of the sky (
$\sigma_8$
by using auto-correlation and cross-correlation of the radio continuum galaxy sample from the EMU PS1 with the CMB lensing convergence as from Planck PR4. The largest bottleneck for the deep radio continuum samples remains the insufficient information on their redshift distribution. There is ongoing work on the cross-correlation of EMU PS1 data with optical galaxies from DES dealing with the modelling of the redshift distribution (Saraf et al. Reference Saraf, Parkinson, Asorey, Hale, Bahr-Kalus, Camera and Tanidis2025). In coming years there will be more data covering a larger fraction of the sky (
 $\sim$
50%), which will certainly reduce the uncertainties on the galaxy bias and the cosmological parameters. In addition, large optical surveys like Euclid can help in reducing the uncertainties on the redshift estimates of the radio galaxy sample (Bahr-Kalus et al., in preparation). This will be achieved by cross-matching radio galaxies with their optical counterparts at known redshifts. This work is only a first step of what EMU survey can achieve even with the pilot survey data covering a relatively small and contiguous patch of sky (
$\sim$
50%), which will certainly reduce the uncertainties on the galaxy bias and the cosmological parameters. In addition, large optical surveys like Euclid can help in reducing the uncertainties on the redshift estimates of the radio galaxy sample (Bahr-Kalus et al., in preparation). This will be achieved by cross-matching radio galaxies with their optical counterparts at known redshifts. This work is only a first step of what EMU survey can achieve even with the pilot survey data covering a relatively small and contiguous patch of sky (
 $\sim 270$
deg
$\sim 270$
deg
 $^{2}$
). Eventually, by combining its deep observations with the large sky area, EMU will manage to probe the matter distribution of the large-scale structure at huge volumes, which will be ideal for studies on extensions to the
$^{2}$
). Eventually, by combining its deep observations with the large sky area, EMU will manage to probe the matter distribution of the large-scale structure at huge volumes, which will be ideal for studies on extensions to the
 $\Lambda$
CDM model (e.g. Alonso et al. Reference Alonso, Bull, Ferreira, Maartens and Santos2015; Camera et al. Reference Camera, Santos, Bacon, Jarvis, McAlpine, Norris, Raccanelli and Röttgering2012; Bernal et al. Reference Bernal, Raccanelli, Kovetz, Parkinson, Norris, Danforth and Schmitt2019).
$\Lambda$
CDM model (e.g. Alonso et al. Reference Alonso, Bull, Ferreira, Maartens and Santos2015; Camera et al. Reference Camera, Santos, Bacon, Jarvis, McAlpine, Norris, Raccanelli and Röttgering2012; Bernal et al. Reference Bernal, Raccanelli, Kovetz, Parkinson, Norris, Danforth and Schmitt2019).
Acknowledgements
The authors thank David Alonso for the enlightening discussions and feedback which were invaluable for the realisation of this project. We also thank the anonymous referee for their constructive comments which improved the presentation of this manuscript. KT is supported by the STFC grant ST/W000903/1 and by the European Structural and Investment Fund. KT also acknowledges the use of the PHOEBE computing facility in Czech Republic. JA is supported by MICIIN-European Union NextGenerationEU María Zambrano program (UCM CT33/21), the UCM project PR3/23-30808, MICINN (Spain) grant PID2022-138263NB-I0 (AEI/FEDER, UE) and the Diputación General de Aragón-Fondo Social Europeo (DGA-FSE) Grant No. 2020-E21-17R of the Aragon Government. JA acknowledges the use of Aljuarismi UCM computing facility. CLH acknowledges generous support from the Hintze Family Charitable Foundation through the Oxford Hintze Centre for Astrophysical Surveys. BB-K acknowledges support from INAF for the project ‘Paving the way to radio cosmology in the SKA Observatory era: synergies between SKA pathfinders/precursors and the new generation of optical/near-infrared cosmological surveys’ (CUP C54I19001050001). SC acknowledges support from the Italian Ministry of University and Research (mur), PRIN 2022 ‘EXSKALIBUR – Euclid-Cross-SKA: Likelihood Inference Building for Universe’s Research’, Grant No. 20222BBYB9, CUP D53D2300252 0006, from the Italian Ministry of Foreign Affairs and International Cooperation (maeci), Grant No. ZA23GR03, and from the European Union – Next Generation EU. MB is supported by the Polish National Science Center through grants no. 2020/38/E/ST9/00395, 2018/30/E/ST9/00698, 2018/31/G/ST9/03388 and 2020/39/B/ST9/03494.
The Australian SKA Pathfinder is part of the Australia Telescope National Facility (https://ror.org/05qajvd42) which is managed by CSIRO. Operation of ASKAP is funded by the Australian Government with support from the National Collaborative Research Infrastructure Strategy. ASKAP uses the resources of the Pawsey Supercomputing Centre. Establishment of ASKAP, the Murchison Radio-astronomy Observatory and the Pawsey Supercomputing Centre are initiatives of the Australian Government, with support from the Government of Western Australia and the Science and Industry Endowment Fund. We acknowledge the Wajarri Yamatji people as the traditional owners of the Observatory site.
Data Availability statement
None.
Appendix A. Quadratic galaxy bias model
Here, we test the quadratic galaxy bias model, which as we saw in Section 4.2 is a polynomial function in redshift
 $b(z)=b_0+b_1z+b_2z^2$
that has three free parameters:
$b(z)=b_0+b_1z+b_2z^2$
that has three free parameters:
 $b_0$
,
$b_0$
,
 $b_1$
and
$b_1$
and
 $b_2$
. We assume a positive flat prior for
$b_2$
. We assume a positive flat prior for
 $b_0$
, while we allow both negative and positive values for the flat priors of
$b_0$
, while we allow both negative and positive values for the flat priors of
 $b_1$
and
$b_1$
and
 $b_2$
, which correspond to the redshift dependence and the evolution of the galaxy bias. In Fig. A1 we show the constraints of the quadratic galaxy bias model parameters and keep
$b_2$
, which correspond to the redshift dependence and the evolution of the galaxy bias. In Fig. A1 we show the constraints of the quadratic galaxy bias model parameters and keep
 $\sigma_8$
to its fiducial value. These are shown with the grey contours for which we assume only the auto-correlation
$\sigma_8$
to its fiducial value. These are shown with the grey contours for which we assume only the auto-correlation
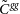 $\tilde{C}^{gg}$
, a HALOFIT power spectrum, the redshift distribution of SKADS and the flux density cut of
$\tilde{C}^{gg}$
, a HALOFIT power spectrum, the redshift distribution of SKADS and the flux density cut of
 $0.18$
mJy. The results are similar, whether we consider a linear power spectrum, a T-RECS distribution or a flux density cut at
$0.18$
mJy. The results are similar, whether we consider a linear power spectrum, a T-RECS distribution or a flux density cut at
 $0.4$
mJy. On top of these results, we present the constraints of the same fiducial case for the constant galaxy bias model, which are shown with the orange contour. We can appreciate that the results we obtain with the considerably less constraining quadratic model are consistent with those from the constant galaxy bias. That is, the parameter
$0.4$
mJy. On top of these results, we present the constraints of the same fiducial case for the constant galaxy bias model, which are shown with the orange contour. We can appreciate that the results we obtain with the considerably less constraining quadratic model are consistent with those from the constant galaxy bias. That is, the parameter
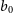 $b_0$
, while poorly constrained, agrees with the
$b_0$
, while poorly constrained, agrees with the
 $b_g$
estimate of the simple model and the other higher order parameters (
$b_g$
estimate of the simple model and the other higher order parameters (
 $b_1,b_2$
) are consistent with the zero value.
$b_1,b_2$
) are consistent with the zero value.

Figure A1. The 68% and 95% confidence intervals of the marginalised contours and the one-dimensional posteriors for the galaxy bias parameters of the quadratic (grey), the constant model (orange) and
 $A_{\text{sn}}$
. Also, the Selavy catalogue was used and we considered a flux density cut at 0.18 mJy. We assumed a fixed cosmology, an SKADS distribution and a HALOFIT power spectrum.
$A_{\text{sn}}$
. Also, the Selavy catalogue was used and we considered a flux density cut at 0.18 mJy. We assumed a fixed cosmology, an SKADS distribution and a HALOFIT power spectrum.
These results mean that the data are not constraining enough to show any other preference for the galaxy bias apart from the single parameter models. This is also verified by the large value in the goodness-of-fit, which is found to be
 $\chi^2_\nu \sim 3$
. Therefore, we opt not to consider the quadratic model for the fiducial analysis in Section 5.
$\chi^2_\nu \sim 3$
. Therefore, we opt not to consider the quadratic model for the fiducial analysis in Section 5.
Finally, we note that another possibility could be to use an intermediate linear model
 $b(z)=b_0+b_1z$
which is empirical, but we do not opt to do so here, since we still have an extra parameter compared to the constant bias and the constant amplitude models we use in our fiducial analysis which have only a single parameter. However, we plan to explore this intermediate model in a future work using more data that will improve our constraining power.
$b(z)=b_0+b_1z$
which is empirical, but we do not opt to do so here, since we still have an extra parameter compared to the constant bias and the constant amplitude models we use in our fiducial analysis which have only a single parameter. However, we plan to explore this intermediate model in a future work using more data that will improve our constraining power.
Appendix B. Comparison with sample covariance
In order to test the robustness of our fiducial analysis against the analytical covariance of Equation (14), we compare our pipeline with one set of models using the sample covariance. We construct
 $1\,000$
mock realisations of correlated Planck PR4 CMB convergence and galaxy density field using GLASS (Tessore et al. Reference Tessore, Loureiro, Joachimi, von Wietersheim-Kramsta and Jeffrey2023). The galaxy number density and survey area in simulations are consistent with EMU PS1 (see Section 3.1). The redshifts of the simulated set of galaxies follow the SKADS redshift distribution with flux density cut at
$1\,000$
mock realisations of correlated Planck PR4 CMB convergence and galaxy density field using GLASS (Tessore et al. Reference Tessore, Loureiro, Joachimi, von Wietersheim-Kramsta and Jeffrey2023). The galaxy number density and survey area in simulations are consistent with EMU PS1 (see Section 3.1). The redshifts of the simulated set of galaxies follow the SKADS redshift distribution with flux density cut at
 $0.18$
mJy.
$0.18$
mJy.

We compute the pseudo-
 $C_\ell$
power spectra from simulations with the same method described in Section 4.1. Then, we construct the sample covariance as B
$C_\ell$
power spectra from simulations with the same method described in Section 4.1. Then, we construct the sample covariance as B
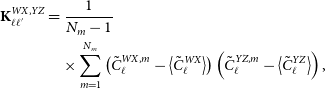 \begin{align}\textbf{K}^{WX,YZ}_{\ell\ell^{\prime}}&=\frac{1}{N_{m}-1} \notag \\ &\quad\times \sum_{m=1}^{N_m}\left(\tilde{C}^{WX,m}_\ell-\left\langle \tilde{C}^{WX}_{\ell} \right \rangle\right)\left(\tilde{C}^{YZ,m}_\ell-\left\langle \tilde{C}^{YZ}_{\ell}\right\rangle\right),\end{align}
\begin{align}\textbf{K}^{WX,YZ}_{\ell\ell^{\prime}}&=\frac{1}{N_{m}-1} \notag \\ &\quad\times \sum_{m=1}^{N_m}\left(\tilde{C}^{WX,m}_\ell-\left\langle \tilde{C}^{WX}_{\ell} \right \rangle\right)\left(\tilde{C}^{YZ,m}_\ell-\left\langle \tilde{C}^{YZ}_{\ell}\right\rangle\right),\end{align}
where
 $N_{m}$
is the total number of simulations,
$N_{m}$
is the total number of simulations,
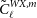 $\tilde{C}^{WX,m}_\ell$
is the power spectrum estimated from the
$\tilde{C}^{WX,m}_\ell$
is the power spectrum estimated from the
 $m\text{th}$
simulation and
$m\text{th}$
simulation and
 \begin{equation} \left\langle \tilde{C}^{WX}_{\ell} \right\rangle= \frac{1}{N_{m}}\sum_{m=1}^{N_m}\tilde{C}^{WX,m}_\ell.\end{equation}
\begin{equation} \left\langle \tilde{C}^{WX}_{\ell} \right\rangle= \frac{1}{N_{m}}\sum_{m=1}^{N_m}\tilde{C}^{WX,m}_\ell.\end{equation}
Although the numerical covariance can be an unbiased estimator of the true covariance, its inverse is not and a correction must be applied, known as the Anderson-Hartlap factor (Parvin Reference Parvin2004; Hartlap, Simon, & Schneider 2007) which is
 \begin{equation}\textbf{K}^{-1} \rightarrow{\frac{N_m-N_d-2}{N_m-2}\textbf{K}^{-1}}, \end{equation}
\begin{equation}\textbf{K}^{-1} \rightarrow{\frac{N_m-N_d-2}{N_m-2}\textbf{K}^{-1}}, \end{equation}
with
 $N_d$
the size of the data vector. We find excellent agreement between the results using the analytical Gaussian covariance of Equation (14) with HALOFIT and the sample covariance of Equation (B1) for the same fiducial cosmological model. These are shown in Fig. B1.
$N_d$
the size of the data vector. We find excellent agreement between the results using the analytical Gaussian covariance of Equation (14) with HALOFIT and the sample covariance of Equation (B1) for the same fiducial cosmological model. These are shown in Fig. B1.
Appendix C. Analysis with the T-RECS redshift distribution and comparison with SKADS
As we can see in Figs. C1 and C2, the galaxy bias and
 $\sigma_8$
results obtained with the T-RECS redshift distribution are in total agreement (very well within 1
$\sigma_8$
results obtained with the T-RECS redshift distribution are in total agreement (very well within 1
 $\sigma$
) with those obtained in our baseline analysis with the SKADS which we discussed in Sections 5.3 and 5.4. In addition, we can appreciate that the interplay between the different flux density cuts, the galaxy bias models and the linear and non-linear HALOFIT matter power spectra also applies for the T-RECS. However, there is some systematic noticeable difference compared to the results obtained with SKADS.
$\sigma$
) with those obtained in our baseline analysis with the SKADS which we discussed in Sections 5.3 and 5.4. In addition, we can appreciate that the interplay between the different flux density cuts, the galaxy bias models and the linear and non-linear HALOFIT matter power spectra also applies for the T-RECS. However, there is some systematic noticeable difference compared to the results obtained with SKADS.
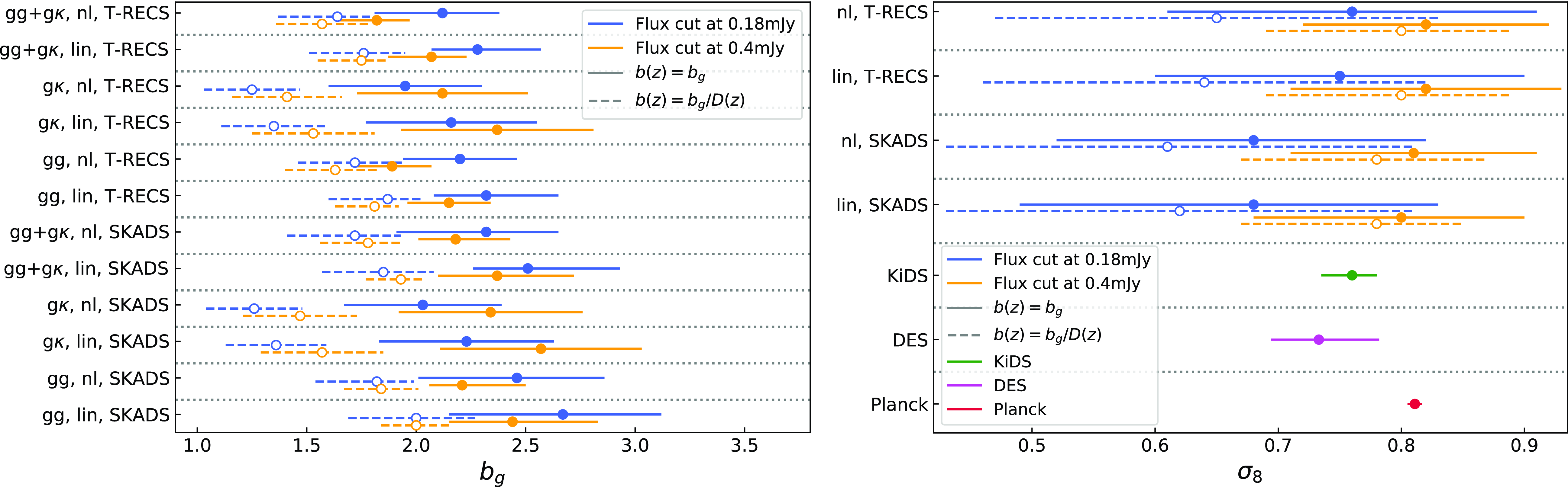
Figure C1. Same as Fig. 4 but now showing on top also the constraints using the T-RECS redshift distribution.
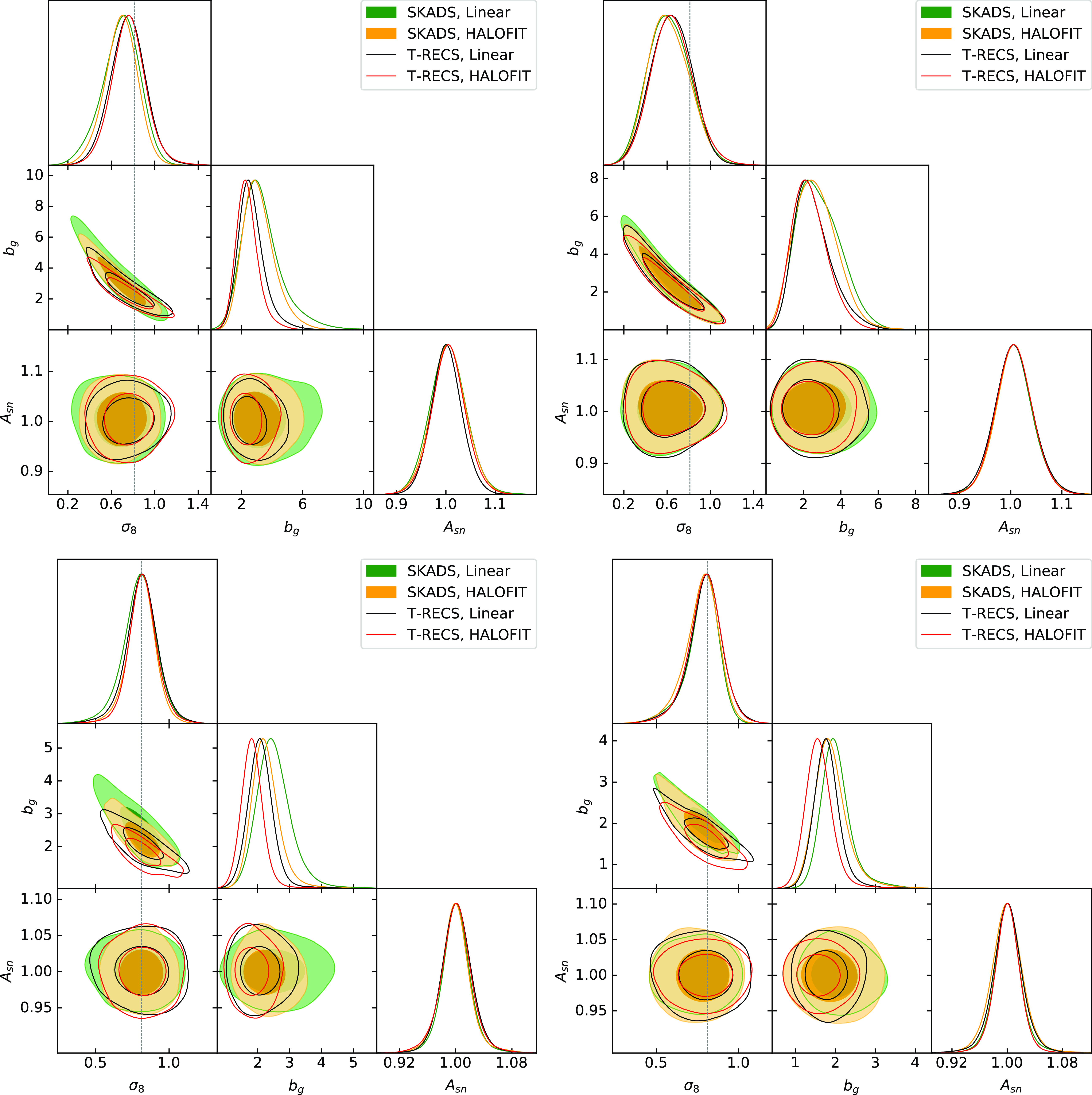
Figure C2. The 68% and 95% confidence intervals of the marginalised contours and the one-dimensional posteriors for the parameters
 $b_g$
,
$b_g$
,
 $\sigma_8$
and
$\sigma_8$
and
 $A_{\text{sn}}$
for the Selavy catalogue. Top and bottom panels show the results for the flux density cut of 0.18 and 0.4 mJy, while left and right panels correspond to the constant galaxy bias and the constant amplitude model, respectively. Filled contours show constraints from SKADS and empty contours from T-RECS. Cold colours (black and green) denote the linear and warm colours (red and orange) the HALOFIT power spectrum. Again, we remind the reader that the vertical dashed black line marks the best-fit value as from Planck Collaboration et al. (2020a).
$A_{\text{sn}}$
for the Selavy catalogue. Top and bottom panels show the results for the flux density cut of 0.18 and 0.4 mJy, while left and right panels correspond to the constant galaxy bias and the constant amplitude model, respectively. Filled contours show constraints from SKADS and empty contours from T-RECS. Cold colours (black and green) denote the linear and warm colours (red and orange) the HALOFIT power spectrum. Again, we remind the reader that the vertical dashed black line marks the best-fit value as from Planck Collaboration et al. (2020a).
Regarding the galaxy bias constraints at fixed cosmology, we note that for all the models with the T-RECS redshift distribution give lower galaxy bias results than SKADS to compensate for its higher power. This is explained, as we already mentioned in Section 3.1.2, due to the longer high-z tail of the SKADS, and the more localized distribution of the T-RECS. Again, we choose to report here only the values of the constant galaxy bias model for the combined measurements
 $(gg+g\kappa)$
of T-RECS with the HALOFIT power spectrum. For the rest of the models we refer the reader again to see from Tables C1 to C4. For the flux density cut at
$(gg+g\kappa)$
of T-RECS with the HALOFIT power spectrum. For the rest of the models we refer the reader again to see from Tables C1 to C4. For the flux density cut at
 $0.18$
mJy, the constant model gives
$0.18$
mJy, the constant model gives
 $b_g=2.12^{+0.31}_{-0.26}$
, while for the constant amplitude model we find
$b_g=2.12^{+0.31}_{-0.26}$
, while for the constant amplitude model we find
 $1.64^{+0.27}_{-0.17}$
. As for the flux density cut at
$1.64^{+0.27}_{-0.17}$
. As for the flux density cut at
 $0.4$
mJy, T-RECS gives a constant bias of
$0.4$
mJy, T-RECS gives a constant bias of
 $b_g=1.82^{+0.18}_{-0.15}$
and a constant amplitude bias of
$b_g=1.82^{+0.18}_{-0.15}$
and a constant amplitude bias of
 $1.57\pm0.21$
.
$1.57\pm0.21$
.
Focusing on the
 $b_g-\sigma_8$
results we shall discuss them in slightly more detail here. Starting for the flux density cut at
$b_g-\sigma_8$
results we shall discuss them in slightly more detail here. Starting for the flux density cut at
 $0.18$
mJy and the constant bias model in the top left panel of Fig. C2 (and with solid blue lines in the right panel of Fig. C1), we see that the SKADS model gives larger bias estimates compared to the T-RECS model, which was also found to be the case in the fixed cosmology case we discussed in the previous paragraph, Now, in turn, this affects the
$0.18$
mJy and the constant bias model in the top left panel of Fig. C2 (and with solid blue lines in the right panel of Fig. C1), we see that the SKADS model gives larger bias estimates compared to the T-RECS model, which was also found to be the case in the fixed cosmology case we discussed in the previous paragraph, Now, in turn, this affects the
 $\sigma_8$
constraint which has a slightly opposite behavior (being larger) to balance the effect. We can also notice here that the linear model has a similar effect when it is compared to HALOFIT but to a lesser extent. We report again here the best-fit values using HALOFIT and SKADS for comparison, which gave
$\sigma_8$
constraint which has a slightly opposite behavior (being larger) to balance the effect. We can also notice here that the linear model has a similar effect when it is compared to HALOFIT but to a lesser extent. We report again here the best-fit values using HALOFIT and SKADS for comparison, which gave
 $\sigma_8=0.68^{+0.16}_{-0.14}$
, while now T-RECS gives
$\sigma_8=0.68^{+0.16}_{-0.14}$
, while now T-RECS gives
 $\sigma_8=0.76\pm0.15$
. It is evident that these measurements are in great agreement with each other as well as with the Planck best-fit value (vertical dashed black line in the panel), while we observe a trend for lower
$\sigma_8=0.76\pm0.15$
. It is evident that these measurements are in great agreement with each other as well as with the Planck best-fit value (vertical dashed black line in the panel), while we observe a trend for lower
 $\sigma_8$
values in the degeneracy direction of the
$\sigma_8$
values in the degeneracy direction of the
 $b_g-\sigma_8$
space. The linear model estimates can be found in Table C1.
$b_g-\sigma_8$
space. The linear model estimates can be found in Table C1.
As for the constraints of the constant amplitude model for the same flux density cut (shown with dashed blue lines in the right panel of Fig. C1), we can appreciate a similar behavior between the different models but now at a smaller extent, while the whole contour set (top right panel of Fig. C2) moves below and slightly to the left from the contours we found for the constant bias model (top left panel of Fig. C2) in the
 $b_g-\sigma_8$
plane, as expected due to the lower values found for the amplitude bias. Similarly to what we saw with the SKADS, there is a preference for lower
$b_g-\sigma_8$
plane, as expected due to the lower values found for the amplitude bias. Similarly to what we saw with the SKADS, there is a preference for lower
 $\sigma_8$
values in the degenerate direction and the best-fit value for T-RECS and HALOFIT is
$\sigma_8$
values in the degenerate direction and the best-fit value for T-RECS and HALOFIT is
 $\sigma_8=0.65\pm0.18$
, in agreement at
$\sigma_8=0.65\pm0.18$
, in agreement at
 $1\sigma$
with Planck (also see linear model results are in Table C2).
$1\sigma$
with Planck (also see linear model results are in Table C2).
Then, the results for the
 $0.4$
mJy flux density cut and the constant galaxy bias are along the same line concerning the interplay between the linear and non-linear models, similarly to what we showed for SKADS. As we discussed in Section 5.4, the most important difference is the fact that in all the cases the galaxy bias values are lower than those at the
$0.4$
mJy flux density cut and the constant galaxy bias are along the same line concerning the interplay between the linear and non-linear models, similarly to what we showed for SKADS. As we discussed in Section 5.4, the most important difference is the fact that in all the cases the galaxy bias values are lower than those at the
 $0.18$
mJy flux density cut and the
$0.18$
mJy flux density cut and the
 $\sigma_8$
constraints are higher. The HALOFIT model estimate for T-RECS is
$\sigma_8$
constraints are higher. The HALOFIT model estimate for T-RECS is
 $\sigma_8=0.82\pm0.10$
(again for the results of the linear model see Table C3 and all the relevant models with the solid orange lines in the right panel of Fig. C1). It is clear that now there is no preference for lower values for
$\sigma_8=0.82\pm0.10$
(again for the results of the linear model see Table C3 and all the relevant models with the solid orange lines in the right panel of Fig. C1). It is clear that now there is no preference for lower values for
 $\sigma_8$
and the Planck best-fit value is at the centre of our contours.
$\sigma_8$
and the Planck best-fit value is at the centre of our contours.
Finally, the constant amplitude bias values for T-RECS follow the rational of what we have found for SKADS in Section 5.4. For HALOFIT we get
 $\sigma_8=0.80^{+0.11}_{-0.09}$
(see Table C4 and dashed orange lines in the right panel of Fig. C2).
$\sigma_8=0.80^{+0.11}_{-0.09}$
(see Table C4 and dashed orange lines in the right panel of Fig. C2).
Table C1. Summary of the best-fit values and their 68% confidence intervals for the constant galaxy bias parameter
 $b_g$
, the amplitude shot noise parameter
$b_g$
, the amplitude shot noise parameter
 $A_{\text{sn}}$
and the cosmological parameter
$A_{\text{sn}}$
and the cosmological parameter
 $\sigma_8$
, at the flux density cut of 0.18 mJy. The last two columns show the
$\sigma_8$
, at the flux density cut of 0.18 mJy. The last two columns show the
 $\chi^2_\nu$
and the PTE, respectively. These results concern gg,
$\chi^2_\nu$
and the PTE, respectively. These results concern gg,
 $g\kappa$
and their combination
$g\kappa$
and their combination
 $gg+g\kappa$
assuming the redshift distributions SKADS and T-RECS and the linear and HALOFIT matter power spectrum. (denoted in the table with ‘lin’ and ‘nl’, respectively.)
$gg+g\kappa$
assuming the redshift distributions SKADS and T-RECS and the linear and HALOFIT matter power spectrum. (denoted in the table with ‘lin’ and ‘nl’, respectively.)
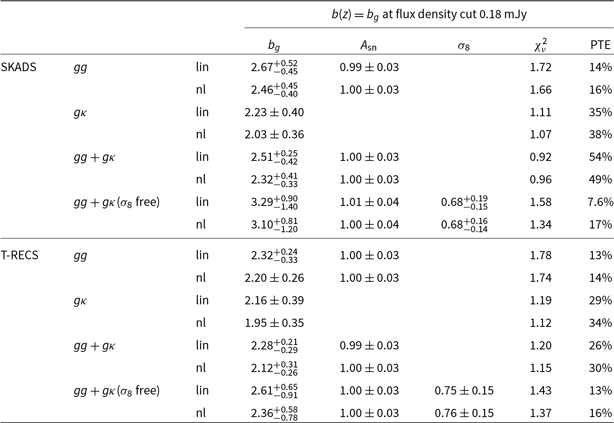
Table C2. Same as Table C1 but for the constant amplitude galaxy bias model. Note that we also add an extra column that shows the galaxy bias constraints at the effective redshift
 $z_{\text{eff}}=\int z n(z) dz / {\int n(z) dz}$
given the SKADS and T-RECS n(z) distributions.
$z_{\text{eff}}=\int z n(z) dz / {\int n(z) dz}$
given the SKADS and T-RECS n(z) distributions.
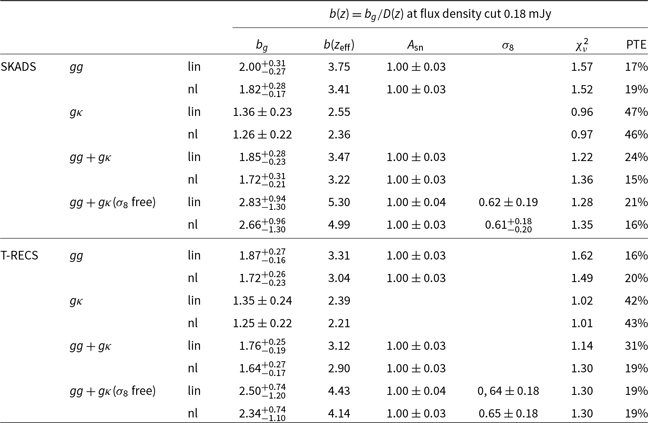
Table C3. Same as Table C1 but for the flux density cut of 0.4 mJy.
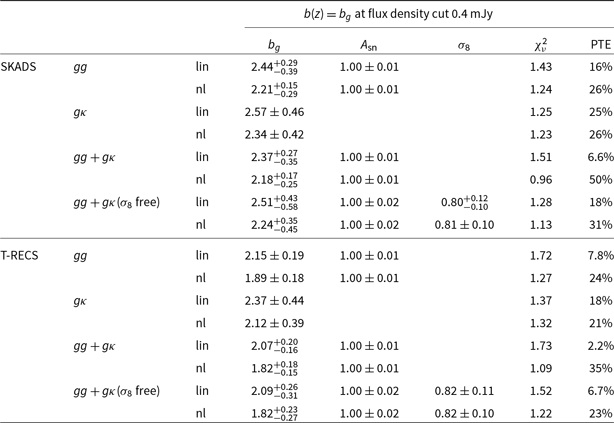
Table C4. Same as Table C2 but for the flux density cut of 0.4 mJy.
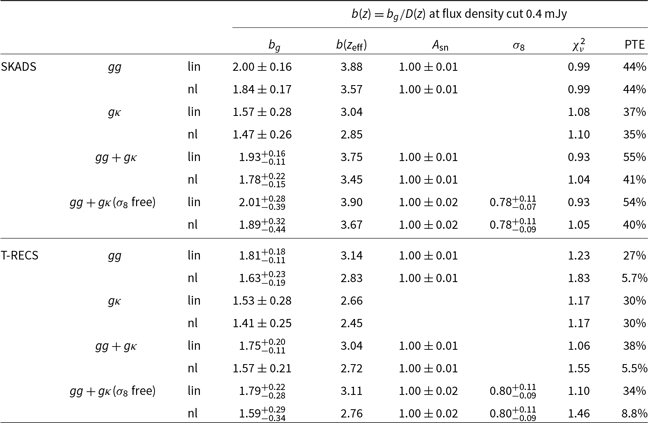


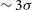






































 Open access
Open access