Refine search
Actions for selected content:
122 results
The effects of fiscal policy shocks: evidence from a Bayesian SVAR model with uncertain identifying assumptions
-
- Journal:
- Macroeconomic Dynamics / Volume 30 / 2026
- Published online by Cambridge University Press:
- 29 January 2026, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We explore the effects of fiscal policy shocks on aggregate output and inflation. We use the Bayesian econometric methodology of Baumeister and Hamilton applied to the fiscal structural vector autoregressive model to evaluate key elasticities and fiscal multipliers using U.S. data. In our baseline specification that ends before Covid pandemic, the government spending multiplier is equal to approximately
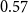 $0.57$ and tax multiplier is approximately
$0.57$ and tax multiplier is approximately 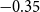 $-0.35$ after one year. The short-term output elasticity of government spending is statistically insignificant and the output elasticity of taxes is approximately equal to
$-0.35$ after one year. The short-term output elasticity of government spending is statistically insignificant and the output elasticity of taxes is approximately equal to 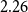 $2.26$.
$2.26$.
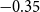
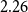
Actively inferring methane sources with drones
- Part of
-
- Journal:
- Environmental Data Science / Volume 5 / 2026
- Published online by Cambridge University Press:
- 28 January 2026, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Shiny-MAGEC: A Bayesian R shiny application for meta-analysis of censored adverse events
-
- Journal:
- Research Synthesis Methods ,
- Published online by Cambridge University Press:
- 24 November 2025, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Statistical Inference and Experimental Data Analysis
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 117-160
-
- Chapter
- Export citation

Probability Theory for Quantitative Scientists
-
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025
A Bayesian framework to investigate radiation reaction in strong fields
-
- Journal:
- High Power Laser Science and Engineering / Volume 13 / 2025
- Published online by Cambridge University Press:
- 08 May 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Market-based insurance ratemaking: Application to pet insurance
- Part of
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 11 April 2025, pp. 263-286
- Print publication:
- May 2025
-
- Article
- Export citation
Bayesian reasoning for qualitative replication analysis: Examples from climate politics
-
- Journal:
- Political Science Research and Methods , First View
- Published online by Cambridge University Press:
- 07 April 2025, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 16 - Probabilistic Beliefs about the State of the World
- from Part III - Mathematical Theories
-
- Book:
- Looking Ahead
- Published online:
- 20 March 2025
- Print publication:
- 06 March 2025, pp 174-187
-
- Chapter
- Export citation
Simulation-based inference of surface accumulation and basal melt rates of an Antarctic ice shelf from isochronal layers
-
- Journal:
- Journal of Glaciology / Volume 71 / 2025
- Published online by Cambridge University Press:
- 27 February 2025, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Adding Regularized Horseshoes to the Dynamics of Latent Variable Models
-
- Journal:
- Political Analysis / Volume 33 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 17 January 2025, pp. 171-177
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Scalable data assimilation with message passing
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 08 January 2025, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bayesian Inference for Finite Mixtures of Generalized Linear Models with Random Effects
-
- Journal:
- Psychometrika / Volume 65 / Issue 1 / March 2000
- Published online by Cambridge University Press:
- 02 January 2025, pp. 93-119
-
- Article
- Export citation
Direct Estimation of Diagnostic Classification Model Attribute Mastery Profiles via a Collapsed Gibbs Sampling Algorithm
-
- Journal:
- Psychometrika / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1390-1421
-
- Article
- Export citation
Going Deep in Diagnostic Modeling: Deep Cognitive Diagnostic Models (DeepCDMs)
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 118-150
-
- Article
- Export citation
-
Cognitive diagnostic models (CDMs) are discrete latent variable models popular in educational and psychological measurement. In this work, motivated by the advantages of deep generative modeling and by identifiability considerations, we propose a new family of DeepCDMs, to hunt for deep discrete diagnostic information. The new class of models enjoys nice properties of identifiability, parsimony, and interpretability. Mathematically, DeepCDMs are entirely identifiable, including even fully exploratory settings and allowing to uniquely identify the parameters and discrete loading structures (the “\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}
 -matrices”) at all different depths in the generative model. Statistically, DeepCDMs are parsimonious, because they can use a relatively small number of parameters to expressively model data thanks to the depth. Practically, DeepCDMs are interpretable, because the shrinking-ladder-shaped deep architecture can capture cognitive concepts and provide multi-granularity skill diagnoses from coarse to fine grained and from high level to detailed. For identifiability, we establish transparent identifiability conditions for various DeepCDMs. Our conditions impose intuitive constraints on the structures of the multiple \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}
-matrices”) at all different depths in the generative model. Statistically, DeepCDMs are parsimonious, because they can use a relatively small number of parameters to expressively model data thanks to the depth. Practically, DeepCDMs are interpretable, because the shrinking-ladder-shaped deep architecture can capture cognitive concepts and provide multi-granularity skill diagnoses from coarse to fine grained and from high level to detailed. For identifiability, we establish transparent identifiability conditions for various DeepCDMs. Our conditions impose intuitive constraints on the structures of the multiple \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document} -matrices and inspire a generative graph with increasingly smaller latent layers when going deeper. For estimation and computation, we focus on the confirmatory setting with known \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}
-matrices and inspire a generative graph with increasingly smaller latent layers when going deeper. For estimation and computation, we focus on the confirmatory setting with known \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\textbf{Q}$$\end{document}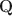 -matrices and develop Bayesian formulations and efficient Gibbs sampling algorithms. Simulation studies and an application to the TIMSS 2019 math assessment data demonstrate the usefulness of the proposed methodology.
-matrices and develop Bayesian formulations and efficient Gibbs sampling algorithms. Simulation studies and an application to the TIMSS 2019 math assessment data demonstrate the usefulness of the proposed methodology.
Latent Class Dynamic Mediation Model with Application to Smoking Cessation Data
-
- Journal:
- Psychometrika / Volume 84 / Issue 1 / 15 March 2019
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1-18
-
- Article
- Export citation
Joint Bayesian Estimation of Voxel Activation and Inter-regional Connectivity in fMRI Experiments
-
- Journal:
- Psychometrika / Volume 85 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 845-869
-
- Article
- Export citation
Bayesian Estimation and Testing of Structural Equation Models
-
- Journal:
- Psychometrika / Volume 64 / Issue 1 / March 1999
- Published online by Cambridge University Press:
- 01 January 2025, pp. 37-52
-
- Article
- Export citation
Bayes Factor Covariance Testing in Item Response Models
-
- Journal:
- Psychometrika / Volume 82 / Issue 4 / December 2017
- Published online by Cambridge University Press:
- 01 January 2025, pp. 979-1006
-
- Article
- Export citation
