Refine search
Actions for selected content:
22 results
Large Language Model-Assisted Research Question Development in Public Health: A Case Study in the Special Supplemental Nutrition Program for Women, Infants, and Children (WIC)
-
- Journal:
- Public Health Nutrition / Accepted manuscript
- Published online by Cambridge University Press:
- 02 February 2026, pp. 1-23
-
- Article
-
- You have access
- Open access
- Export citation
Accelerating water distribution systems planning and design with generative artificial intelligence models
-
- Journal:
- Cambridge Prisms: Water / Volume 4 / 2026
- Published online by Cambridge University Press:
- 05 January 2026, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimizing the key information section of informed consent documents in biomedical research: A multi-phased study using large language models
-
- Journal:
- Journal of Clinical and Translational Science / Volume 10 / Issue 1 / 2026
- Published online by Cambridge University Press:
- 02 January 2026, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Large language model driven development of turbulence models
-
- Journal:
- Flow: Applications of Fluid Mechanics / Volume 5 / 2025
- Published online by Cambridge University Press:
- 21 November 2025, E40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Beyond human gold standards: A multimodel framework for automated abstract classification and information extraction
-
- Journal:
- Research Synthesis Methods / Volume 17 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 17 November 2025, pp. 365-377
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing designer creativity through human–AI co-ideation: a co-creation framework for design ideation with custom GPT
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Relative importance of lexical features in word processing during L2 English reading
-
- Journal:
- Studies in Second Language Acquisition / Volume 47 / Issue 5 / December 2025
- Published online by Cambridge University Press:
- 29 August 2025, pp. 1383-1406
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Decoding the grammar of design theory for large language models: the case of axiomatic design theory
-
- Journal:
- Proceedings of the Design Society / Volume 5 / August 2025
- Published online by Cambridge University Press:
- 27 August 2025, pp. 1121-1130
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Can large language models support machine learning implementation in product development? A comparative analysis and perspectives
-
- Journal:
- Proceedings of the Design Society / Volume 5 / August 2025
- Published online by Cambridge University Press:
- 27 August 2025, pp. 861-870
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Creating design catalog from patent documents with large language model for design concept generation
-
- Journal:
- Proceedings of the Design Society / Volume 5 / August 2025
- Published online by Cambridge University Press:
- 27 August 2025, pp. 1051-1060
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
6 - LLMs Meet the AI Act
- from Part II - Evolving Regulatory and Governance Frameworks
-
-
- Book:
- The Cambridge Handbook of Generative AI and the Law
- Published online:
- 08 August 2025
- Print publication:
- 07 August 2025, pp 85-98
-
- Chapter
- Export citation
Enhancing TRIZ through environment-based design methodology supported by a large language model
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A novel idea generation tool using a structured conversational AI (CAI) system
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Promises and pitfalls of large language models in psychiatric diagnosis and knowledge tasks
-
- Journal:
- The British Journal of Psychiatry / Volume 226 / Issue 4 / April 2025
- Published online by Cambridge University Press:
- 29 April 2025, pp. 243-244
- Print publication:
- April 2025
-
- Article
-
- You have access
- HTML
- Export citation
A large language model based data generation framework to improve mild cognitive impairment detection sensitivity
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 26 March 2025, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generalizable and scalable multistage biomedical concept normalization leveraging large language models
-
- Journal:
- Research Synthesis Methods / Volume 16 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 12 March 2025, pp. 479-490
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Background
Biomedical entity normalization is critical to biomedical research because the richness of free-text clinical data, such as progress notes, can often be fully leveraged only after translating words and phrases into structured and coded representations suitable for analysis. Large Language Models (LLMs), in turn, have shown great potential and high performance in a variety of natural language processing (NLP) tasks, but their application for normalization remains understudied.
MethodsWe applied both proprietary and open-source LLMs in combination with several rule-based normalization systems commonly used in biomedical research. We used a two-step LLM integration approach, (1) using an LLM to generate alternative phrasings of a source utterance, and (2) to prune candidate UMLS concepts, using a variety of prompting methods. We measure results by
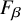 $F_{\beta }$, where we favor recall over precision, and F1.Results
$F_{\beta }$, where we favor recall over precision, and F1.ResultsWe evaluated a total of 5,523 concept terms and text contexts from a publicly available dataset of human-annotated biomedical abstracts. Incorporating GPT-3.5-turbo increased overall
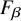 $F_{\beta }$ and F1 in normalization systems +16.5 and +16.2 (OpenAI embeddings), +9.5 and +7.3 (MetaMapLite), +13.9 and +10.9 (QuickUMLS), and +10.5 and +10.3 (BM25), while the open-source Vicuna model achieved +20.2 and +21.7 (OpenAI embeddings), +10.8 and +12.2 (MetaMapLite), +14.7 and +15 (QuickUMLS), and +15.6 and +18.7 (BM25).Conclusions
$F_{\beta }$ and F1 in normalization systems +16.5 and +16.2 (OpenAI embeddings), +9.5 and +7.3 (MetaMapLite), +13.9 and +10.9 (QuickUMLS), and +10.5 and +10.3 (BM25), while the open-source Vicuna model achieved +20.2 and +21.7 (OpenAI embeddings), +10.8 and +12.2 (MetaMapLite), +14.7 and +15 (QuickUMLS), and +15.6 and +18.7 (BM25).ConclusionsExisting general-purpose LLMs, both propriety and open-source, can be leveraged to greatly improve normalization performance using existing tools, with no fine-tuning.
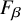
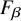
ChatGPT as an inventor: eliciting the strengths and weaknesses of current large language models against humans in engineering design
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Reliable Common-Sense Reasoning Socialbot Built Using LLMs and Goal-Directed ASP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 606-627
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evaluating large-language-model chatbots to engage communities in large-scale design projects
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Copilots for Linguists
- AI, Constructions, and Frames
-
- Published online:
- 20 December 2023
- Print publication:
- 01 February 2024
-
- Element
- Export citation
