


1. Introduction
Natural language generation (NLG) (Gatt and Krahmer Reference Gatt and Krahmer2018) is a subfield of natural language processing aiming to enable computers the ability to write correct, coherent, and appealing texts. NLG includes popular tasks like machine translation (Bahdanau, Cho, and Bengio Reference Bahdanau, Cho and Bengio2015), summarization (Rush, Chopra, and Weston Reference Rush, Chopra and Weston2015), and dialogue response generation (Yarats and Lewis Reference Yarats and Lewis2018).
An increasingly prominent task in NLG is text style transfer (TST). TST aims at transferring a sentence from one style to another without appreciably changing the content (Hu et al. Reference Hu, Lee, Aggarwal and Zhang2022; Jin et al. Reference Jin, Jin, Hu, Vechtomova and Mihalcea2022). TST encompasses several sub-tasks, including sentiment transfer, news rewriting, storytelling, text simplification, and writing assistants, among others. For example, author imitation (Xu et al. Reference Xu, Ritter, Dolan, Grishman and Cherry2012) is the task of paraphrasing a sentence to fit another author’s style. Automatic poetry generation (Ghazvininejad et al. Reference Ghazvininejad, Shi, Choi and Knight2016) applies style transfer to create poetry in different fashions.
TST inherits the challenges of NLG, namely the lack of parallel training corpora and reliable evaluation metrics (Reiter and Belz Reference Reiter and Belz2009; Gatt and Krahmer Reference Gatt and Krahmer2018). Since parallel examples from each domain style are usually unavailable, most style transfer works focus on the unsupervised configuration (Han, Wu, and Niu Reference Han, Wu and Niu2017; He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020; Malmi, Severyn, and Rothe Reference Malmi, Severyn and Rothe2020a). Our work also follows the unsupervised style transfer setting, learning from non-parallel data only.
Most previous models that address the style transfer problem adopt the sequence-to-sequence encoder-decoder framework (Shen et al. Reference Shen, Lei, Barzilay and Jaakkola2017; Hu et al. Reference Hu, Yang, Liang, Salakhutdinov and Xing2017; Fu et al. Reference Fu, Tan, Peng, Zhao and Yan2018). The encoder aims at extracting a style-independent latent representation while the decoder generates the text conditioned on the disentangled latent representation plus a style attribute. This family of methods learns how to disentangle the content and style in the latent space. Disengaging the content from the style means that it is impossible to recover the style from the content. Nevertheless, Lample et al. (Reference Lample, Subramanian, Smith, Denoyer, Ranzato and Boureau2019) show that disentanglement is hard to do, difficult to judge the quality, and particularly unnecessary. Thus, following previous work (Lample et al. Reference Lample, Subramanian, Smith, Denoyer, Ranzato and Boureau2019; Dai et al. Reference Dai, Liang, Qiu and Huang2019), we make no assumptions about the disentangled latent representations of the input sentences.
We rely on transformer (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) as our base neural sequence-to-sequence (Seq2Seq) architecture. The transformer is a deep neural network that has succeeded in many NLP tasks, particularly when it allies with pretrained masked language models (MLM), such as BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). However, using MLM in text generation tasks is less prevalent. This is because models like BERT focus on encoding bidirectional representations through the masked language modeling task, while text generation better fits an auto-regressive decoding process.
We explore training the Seq2Seq model with two procedures. One approach trains it from scratch with the dataset itself, and the other pretrains the model using available paraphrased data before presenting it to the dataset examples. We show that pretraining a Seq2Seq model on a massive paraphrase data benefits TST tasks, mainly the ones that can be considered rewriting tasks. Furthermore, we investigate if we can leverage masked language models to benefit the style transfer task, even though their use is less widespread than auto-regressive models for language generation-based tasks. Notably, we want to investigate if TST with a masked language model can output texts with the desired style while still preserving the input text main topic or theme. The investigation considers the following research questions:
RQ1: Does extracting knowledge from a Masked Language Model improve the performance of Seq2Seq models in the style transfer task and consequently generate high-quality texts?
RQ2: What is the impact of pretraining the Seq2Seq model on paraphrase data to the style transfer task?
To answer the research questions, we build our model upon the neural architecture block proposed in Dai et al. (Reference Dai, Liang, Qiu and Huang2019). We leverage their transformer neural network and training strategies. Our adopted transformer network is similar to the original one (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017), except for an additional style embedding inserted into the encoder as the first embedding component. Regarding the training techniques, we inherited the adversarial training and the back-translation techniques of Dai et al. (Reference Dai, Liang, Qiu and Huang2019). Nevertheless, we formulate the main cost function to extract knowledge from a MLM.
To show we can take advantage of an MLM to improve the performance of the style transfer task, we try to distill the knowledge of a pretrained MLM to leverage its learned bidirectional representations. We modify the training objective by transferring the knowledge it contains to the Seq2Seq model. We hypothesize that the predictive power of an MLM improves the performance of TST. As our model uses both Transformers and a MLM for training, we call it MATTES (MAsked Transformer for TExt Style transfer).Footnote a Furthermore, to evaluate if pretraining the Seq2Seq model benefits the TST task, we select a large-scale collection of diverse paraphrase data, namely, the PARABANK 2 dataset (Hu et al. Reference Hu, Singh, Holzenberger, Post and Van Durme2019). For comparison, we experimented training from scratch with the dataset examples and starting from the pretrained model.
For evaluating the proposed model and learning strategies, we select the author imitation (Xu et al. Reference Xu, Ritter, Dolan, Grishman and Cherry2012), formality transfer (Rao and Tetreault Reference Rao and Tetreault2018), and the polarity swap (Li et al. Reference Li, Jia, He and Liang2018) tasks, all in English, given the availability of benchmark datasets. The first task aims at paraphrasing a sentence in an author’s style. The second task consists of rewriting a formal sentence into its informal counterpart and vice-versa. The remaining task, also known as sentiment transfer, aims at reversing the sentiment of a text from positive to negative and vice-versa, preserving the overall theme. These tasks are usually gathered in the literature under the general style transfer label and addressed with the same methods. However, they have critical differences: author imitation and formality transfer imply rephrasing a sentence to match the desired target style without changing its meaning. On the other hand, polarity swap aims to change a text with positive polarity into a text with negative polarity (or vice-versa). In this case, while the general topic must be preserved, the meaning is not maintained (e.g., turning “I had a bad experience” into “I had a great experience”). In this sense, author imitation and formality transfer can be seen much more as rewriting than polarity swap. This way, it is possible to consider them similar to the broader objective of paraphrasing. In this manuscript, we also address these tasks similarly, but this is to investigate how their different nature affects the models, task modeling, and evaluation.
Regarding task evaluation, the literature commonly assesses the performance of TST on style strength and content preservation. To verify that the generated text agrees with the desired style, we train a classifier using texts of both styles, with style as the class, and measure its accuracy. To measure content preservation, the most important feature a style transfer model should possess, three metrics were used: BLEU (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002), semantic similarity (SIM) (Wieting et al. Reference Wieting, Berg-Kirkpatrick, Gimpel and Neubig2019), and BARTScore (Yuan, Neubig, and Liu Reference Yuan, Neubig and Liu2021). The results pointed out that using a pretrained Seq2Seq as starting point and using a pretrained MLM throughout the main training of the model improves the quality of the generated texts. We show that the former is extremely helpful for rewriting tasks while the latter is more task agnostic oriented but slightly impacts the performance.
The contributions of this paper are:
-
1. A novel unsupervised training method that distills knowledge from a pretrained MLM. To our knowledge, this is the first study that uses an MLM within the training objective on the style transfer task. We show that extracting the rich bidirectional representations of an MLM benefits the TST task.
-
2. An evaluation of two training strategies of the Seq2Seq model. We show that rewriting tasks, such as author imitation and formality transfer, benefit from a Seq2seq model pretrained with paraphrase data.
-
3. In the experiments with author imitation and formality transfer, we achieve state-of-the-art results when pretraining the Seq2Seq model with paraphrase data and using our distillation training technique.
The rest of the manuscript is organized as follows. Section 2 briefly describes basic concepts related to our proposal. Section 3 reviews related work to highlight how MATTES is placed within the literature on the theme. Next, we state the problem tackled here and present our approach in Section 4. Section 5 devises the experiments, and Section 6 concludes the manuscript and points out future directions.
2. Key concepts
This section reviews essential concepts that form the architectural backbone of our proposal. We describe the general paradigm widely used to handle NLP tasks that demand transforming a sequence of tokens into another sequence. Next, we review the Transformer architecture, which relies on the attention mechanism to enhance the sequence generation. Finally, we discuss the autoregressive and MLMs, as we rely on the latter to build MATTES.
2.1 Sequence-to-sequence models with the transformer architecture
Sequence-to-Sequence (Seq2Seq) models are frameworks based on deep learning to address tasks that require obtaining a sequence of values as output from a sequence of input values (Sutskever, Vinyals, and Le Reference Sutskever, Vinyals and Le2014). At a high level, a Seq2Seq model comprises two neural networks, one encoding the input and the other decoding the encoded representation to produce the output.
Early models included recurrent neural networks as the encoder and decoder components. In this case, the encoder’s role is to read the input sequence
 $X = < x_1, \ldots, x_n>$
, where
$X = < x_1, \ldots, x_n>$
, where
 $x_i$
is a token, and generate a fixed-dimension vector
$x_i$
is a token, and generate a fixed-dimension vector
 $C$
representing the context. Then, the decoder generates the output sequence
$C$
representing the context. Then, the decoder generates the output sequence
 $Y = < y_1, \ldots, y_m>$
, starting from the context vector
$Y = < y_1, \ldots, y_m>$
, starting from the context vector
 $C$
. However, compressing a variable-length sequence into a single context vector is challenging, especially when the input sequence is long. Thus, Seq2Seq models with vanilla recurrent networks fail to capture long textual dependencies due to the information bottleneck when relying on a single context vector.
$C$
. However, compressing a variable-length sequence into a single context vector is challenging, especially when the input sequence is long. Thus, Seq2Seq models with vanilla recurrent networks fail to capture long textual dependencies due to the information bottleneck when relying on a single context vector.
The attention mechanism emerged to address the information bottleneck problem of seq2seq recurrent neural networks (Bahdanau et al. Reference Bahdanau, Cho and Bengio2015). Instead of using only one context vector at the end of the encoding process, the attention vector provides the decoding network with a full view of the input sequence at every step of the decoding process. Thus, in the output generation process, the decoder can decide which tokens are important at any given time.
Using only attention mechanisms and dismissing recurrent and convolutional components, Vaswani et al. (Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) created an architecture named Transformer, which was successful in numerous NLP tasks (Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018; Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). The Transformer architecture follows the Seq2Seq paradigm comprising an encoder–decoder architecture. The encoder consists of six identical encoding layers. Each comprises a multihead self-attention mechanism, residual connections, an add-norm mechanism, and a feed-forward network. The decoder also consists of six identical layers similar to the encoding layers. However, the decoder gets two inputs and applies the attention twice, where, in one of them, the input is masked. This prevents the token in a certain position from having access to tokens after it during the generation process. Also, the final decoder layer has a size equal to the number of words in the vocabulary.
2.2 Autorregressive and masked language models
Language models compute the probability of the occurrence of a token given a context. Autoregressive language models compute the probability of occurrence of a token, given the previous tokens in the sequence. Thus, given a sequence
 $\textbf{x} = (x_1, x_2, \ldots, x_m)$
, an autoregressive language model calculates the probability
$\textbf{x} = (x_1, x_2, \ldots, x_m)$
, an autoregressive language model calculates the probability
 $p(x_t| x_{< t})$
. The probability of a sequence of
$p(x_t| x_{< t})$
. The probability of a sequence of
 $m$
tokens
$m$
tokens
 $x_1, x_2, \ldots, x_m$
is given by
$x_1, x_2, \ldots, x_m$
is given by
 $P(x_1, x_2, \ldots, x_m)$
. Since it is computationally expensive to enumerate all possible combinations of tokens that come before a token,
$P(x_1, x_2, \ldots, x_m)$
. Since it is computationally expensive to enumerate all possible combinations of tokens that come before a token,
 $P(x_1, x_2, \ldots, x_m)$
is usually conditioned to a window of
$P(x_1, x_2, \ldots, x_m)$
is usually conditioned to a window of
 $n$
previous tokens instead of all the previous ones. In these cases,
$n$
previous tokens instead of all the previous ones. In these cases,
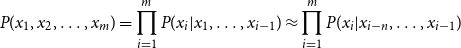 \begin{equation} \begin{split} P(x_1, x_2, \ldots, x_m) = \prod _{i=1}^{m} P(x_i|x_1, \ldots, x_{i-1}) \approx \prod _{i=1}^{m} P(x_i|x_{i-n}, \ldots, x_{i-1}) \end{split} \end{equation}
\begin{equation} \begin{split} P(x_1, x_2, \ldots, x_m) = \prod _{i=1}^{m} P(x_i|x_1, \ldots, x_{i-1}) \approx \prod _{i=1}^{m} P(x_i|x_{i-n}, \ldots, x_{i-1}) \end{split} \end{equation}
Pretraining neural language models using self-supervision from a large volume of texts has been highly effective in improving the performance of various NLP tasks (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018; Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018; Howard and Ruder Reference Howard and Ruder2018; Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). The pretrained language models can be later adjusted with fine-tuning to handle specific downstream tasks or domains.
Different self-supervised goals were explored in the literature to pretrain a language model, including autoregressive and MLM strategies (Yang et al. Reference Yang, Dai, Yang, Carbonell, Salakhutdinov and Le2019, Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019; Yang et al. Reference Yang, Dai, Yang, Carbonell, Salakhutdinov and Le2019; Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020; Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020). An autoregressive language model, given a sequence
 $\textbf{x} = (x_1, x_2, \ldots, x_m)$
, factors the probability into a left-to-right product
$\textbf{x} = (x_1, x_2, \ldots, x_m)$
, factors the probability into a left-to-right product
 $p(\textbf{x}) = \prod _{t=1}^{T}p(x_t| x_{< t})$
or from right-to-left
$p(\textbf{x}) = \prod _{t=1}^{T}p(x_t| x_{< t})$
or from right-to-left
 $p(\textbf{x}) = \prod _{t=T}^{1}p(x_t| x_{> t})$
. The problem with these models is unidirectionality since, during training, a token can only be aware of the tokens to its left or right. Many works point out that it is fundamental for several tasks to obtain bidirectional representations incorporating the context of both the left and the right (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019).
$p(\textbf{x}) = \prod _{t=T}^{1}p(x_t| x_{> t})$
. The problem with these models is unidirectionality since, during training, a token can only be aware of the tokens to its left or right. Many works point out that it is fundamental for several tasks to obtain bidirectional representations incorporating the context of both the left and the right (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019).
Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019) introduced the task of masked language modeling (MLM) with BERT, a transformer-encoder. MLM consists of replacing a percentage (in the original work,
 $15\%$
) of the sequence tokens with a token [MASK] and then predicting those masked tokens. In BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), the probability distribution of the masked tokens regards both the left and right contexts of the sentence.
$15\%$
) of the sequence tokens with a token [MASK] and then predicting those masked tokens. In BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), the probability distribution of the masked tokens regards both the left and right contexts of the sentence.
2.2.1 ALBERT: A lite version of BERT
Overall, increasing the size of a pretrained neural language model positively impacts subsequent tasks. However, growing the model becomes unfeasible at some point due to GPU/TPU memory limitations and huge training time. ALBERT (Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020) addressed these problems with two techniques for reducing parameters. This manuscript relies on an ALBERT model to extract knowledge from its rich contextualized representations. Although any other MLM model could have been selected, we adopt ALBERT because it uses fewer computational resources when compared to a BERT of the same size.
The architectural skeleton of ALBERT is similar to BERT, which means that it uses a transformer encoder with GELU activation function (Hendrycks and Gimpel Reference Hendrycks and Gimpel2016). ALBERT makes three main contributions to BERT design choices, as follows. Following BERT notation,
 $E$
is the size of the vocabulary vector representations,
$E$
is the size of the vocabulary vector representations,
 $L$
is the number of encoder layers, and
$L$
is the number of encoder layers, and
 $H$
is the hidden layers’ representation size.
$H$
is the hidden layers’ representation size.
Parameter factorization
BERT ties
 $E$
to the size of the hidden states representation
$E$
to the size of the hidden states representation
 $H$
, that is,
$H$
, that is,
 $E = H$
, which is not efficient, both for modeling and practical reasons. From a modeling point of view, the learned representations for vocabulary tokens are context-independent, while the hidden layers of learned representations are context-dependent. As the representational power of BERT lies in the possibility of obtaining rich contextualized representations from non-contextualized representations, untying
$E = H$
, which is not efficient, both for modeling and practical reasons. From a modeling point of view, the learned representations for vocabulary tokens are context-independent, while the hidden layers of learned representations are context-dependent. As the representational power of BERT lies in the possibility of obtaining rich contextualized representations from non-contextualized representations, untying
 $E$
from
$E$
from
 $H$
is a more efficient use of model parameters. From a practical point of view, as in most NLP tasks, the vocabulary size
$H$
is a more efficient use of model parameters. From a practical point of view, as in most NLP tasks, the vocabulary size
 $V$
is usually large; if
$V$
is usually large; if
 $E = H$
, increasing
$E = H$
, increasing
 $H$
increases the representation matrix of vocabulary tokens, which is of length
$H$
increases the representation matrix of vocabulary tokens, which is of length
 $V \times E$
. This can result in a model with billions of parameters, many of which are sparsely updated during training. Thus, ALBERT decomposes the matrix of vocabulary representations into two smaller matrices, reducing the parameters from
$V \times E$
. This can result in a model with billions of parameters, many of which are sparsely updated during training. Thus, ALBERT decomposes the matrix of vocabulary representations into two smaller matrices, reducing the parameters from
 $O(V \times H)$
to
$O(V \times H)$
to
 $O(V \times E + E \times H)$
. This is a significant reduction when
$O(V \times E + E \times H)$
. This is a significant reduction when
 $H \gg E$
.
$H \gg E$
.
Shared parameters between layers
ALBERT has a scheme for sharing parameters between layers to improve handling parameters efficiently. Although it is possible to share the parameters between the layers partially, the default configuration shares all the parameters, both neural network and attention parameters. With this, it is possible to increase the depth without increasing the number of parameters.
Coherence component between sentences in the loss function
BERT has an extra component in the loss function besides predicting the masked tokens, called next-sentence prediction (NSP). During training, NSP learns whether two sentences appear consecutively in the original text. Arguing that this component is not practical as a task when compared to the MLM task, Lan et al. (Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020) proposed a component called sentence-order prediction (SOP). This component uses as a positive example two consecutive text segments from the same document (such as BERT). As a negative example, the same two segments, but with the order changed. The results indicated that ALBERT improved performance in subsequent tasks that involved coding more than one sentence.
Although masked pretrained models, such as BERT and ALBERT, benefit several NLP tasks, they fit less text generation tasks since they are transformer encoders, and decoders are more suitable to generate texts. However, it is common when writing a text that words that appeared before can be changed after writing a later sequence, giving an intuitive idea of context and bidirectionality. In order to make use of rich bidirectional representations from a MLM, MATTES distills knowledge from ALBERT to benefit the TST task.
3. Literature review and related work
TST aims to automatically change stylistic features, such as formality, sentiment, author style, humor, and complexity, while trying to preserve the content. This manuscript focuses on unsupervised TST, given that creating a parallel corpus of texts with different styles is challenging and requires much human effort. In this scenario, the approaches differ in investigating how to disentangle style and content or not disentangling them at all (Hu et al. Reference Hu, Lee, Aggarwal and Zhang2022). Lample et al. (Reference Lample, Subramanian, Smith, Denoyer, Ranzato and Boureau2019) argued that it is difficult to judge whether content and style representations obtained are disentangled and that disentanglement is not necessary for the TST task either. Recent studies, including this manuscript, explore the TST task without disentangling content and style. Next, we elicit works that explicitly decouple the content from the style, try to detach them implicitly using latent variables, or do not rely on disentanglement strategies to position our work within the current TST literature.
3.1 Explicit disentanglement
Models following this strategy generate texts through direct replacement of keywords associated with the style (Li et al. Reference Li, Jia, He and Liang2018; Xu et al. Reference Xu, Sun, Zeng, Zhang, Ren, Wang and Li2018; Zhang et al. Reference Zhang, Xu, Yang and Sun2018a; Sudhakar, Upadhyay, and Maheswaran Reference Sudhakar, Upadhyay and Maheswaran2019; Wu et al. Reference Wu, Ren, Luo and Sun2019a, Reference Wu, Zhang, Zang, Han and Hu2019b; Malmi, Severyn, and Rothe Reference Malmi, Severyn and Rothe2020b).
The method Delete, Retrieve, Generate (Li et al. Reference Li, Jia, He and Liang2018) explicitly replaces keywords in a text with words of the target style. First, it removes the words that best represent the original style. Then, it fetches the text most similar to the input from the target corpus. Next, it extracts the words most closely associated with the target style from the returned text and combines them with the sentence acquired in the first step to generate the output text using a sequence-to-sequence neural network model. Sudhakar et al. (Reference Sudhakar, Upadhyay and Maheswaran2019) extended the model Delete, Retrieve, Generate to improve the Delete step using a transformer (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). The method POINT-THEN-OPERATE (Wu et al. Reference Wu, Ren, Luo and Sun2019) also changes the input sentence but relies on hierarchical reinforcement learning. One RL agent points out the positions that should be edited in the sentence, and another RL agent changes it.
Zhang et al. (Reference Zhang, Xu, Yang and Sun2018a) adopted a keyword substitution technique similar to Delete, Retrieve, Generate to transfer sentiment in texts. Also focusing on sentiment transfer, Xu et al. (Reference Xu, Sun, Zeng, Zhang, Ren, Wang and Li2018) developed a model with a neutralization and an emotionalization components. The former extracts semantic information without emotional content, while the latter adds sentiment content to the neutralized positions.
The Mask and Infill method (Wu et al. Reference Wu, Zhang, Zang, Han and Hu2019b) works in two stages. First, it masks words associated with the style using frequency rates. Next, it fills the masked positions with the target style using a pretrained MLM. Malmi et al. (Reference Malmi, Severyn and Rothe2020b) also used a pretrained MLM to remove snippets and generate the replacement snippets. Although these works rely on MLMs, they differ from our proposal as they use language models only to predict tokens to replace previously removed ones.
3.2 Implicit disentanglement
Models focusing on implicit disentanglement detach content and style from the original sentence but do not explicitly alter the original sentence. They learn latent content and style representations for a given text to separate content from style. Then, the content representation is combined with the target style representation to generate the text in the target style.
Most recent solutions leverage adversarial learning (Hu et al. Reference Hu, Yang, Liang, Salakhutdinov and Xing2017; Shen et al. Reference Shen, Lei, Barzilay and Jaakkola2017; Fu et al. Reference Fu, Tan, Peng, Zhao and Yan2018; Zhao et al. Reference Zhao, Kim, Zhang, Rush and LeCun2018b; Chen et al. Reference Chen, Dai, Tao, Shen, Gan, Zhang, Zhang, Zhang, Wang and Carin2018; Logeswaran, Lee, and Bengio Reference Logeswaran, Lee and Bengio2018; Lai et al. Reference Lai, Hong, Chen, Lu and Lin2019; John et al. Reference John, Mou, Bahuleyan and Vechtomova2019; Yin et al. Reference Yin, Huang, Dai and Chen2019) to obtain style-agnostic representations of the sentence content. After learning the latent content representation, the decoder receives as input that representation along with the label of the desired style to generate a variation of the input text with the desired style. Yang et al. (Reference Yang, Hu, Dyer, Xing and Berg-Kirkpatrick2018) followed that strategy and used two language models, one for each stylistic domain. The model minimizes the perplexity of sentences generated according to these pretrained language models.
Other techniques separate content from the style by artificially generating parallel data via back-translation, then converting them back to the original domain, forcing them to be the same as the input. Besides addressing the lack of parallel data, such a strategy can normalize the input sentence by stripping away information that is predictive of its original style. With back-translation, one-direction outputs and inputs can be used as pairs to train the model of the opposite transfer direction. Prabhumoye et al. (Reference Prabhumoye, Tsvetkov, Salakhutdinov and Black2018) used an English-French neural translation model to rephrase the sentence and remove the stylistic properties of the text. The English sentence is initially translated into French. The French text is then translated back to English using a French-English neural model. Finally, this style-independent latent representation learned is used to generate texts in a different style using a multiple-decoder approach. Zhang et al. (Reference Zhang, Ren, Liu, Wang, Chen, Li, Zhou and Chen2018b) followed back-translation first to create pseudo-parallel data. Then, those data initialize an iterative back-translation pipeline to train two style transfer systems based on neural translation models. Krishna et al. (Reference Krishna, Wieting and Iyyer2020) used a paraphrasing model to create pseudo-parallel data and then trained style-specific inverse paraphrase models that convert these paraphrased sentences back into the original stylized sentence. Despite adopting back-translation, our proposal does not expect that the model output is deprived of style information. On the contrary, during training, we try to control the style of the generated output.
Some disentanglement strategies explore learning a style attribute to control the generation of texts in different styles. The method presented in (Hu et al. Reference Hu, Yang, Liang, Salakhutdinov and Xing2017) induces a model that uses a variational autoencoder (VAE) to learn latent representations of sentences. These representations are composed of unstructured variables (content)
 $z$
and structured variables (style)
$z$
and structured variables (style)
 $c$
that aim to represent salient and independent features of the sentence semantics. Finally,
$c$
that aim to represent salient and independent features of the sentence semantics. Finally,
 $z$
and
$z$
and
 $c$
are inserted into a decoder to generate text in the desired style. Tian et al. (Reference Tian, Hu and Yu2018) extended this approach, adding constraints to preserve style-independent content, using Part-of-speech categories and a content-conditioned language model. Zhao, Kim, Zhang, Rush and LeCun (2018) proposed a regularized adversarial autoencoder that expands the use of adversarial autoencoders to discrete sequences. Park et al. (Reference Park, Hwang, Chen, Choo, Ha, Kim and Yim2019) relied on adversarial training and VAE to expand previous methods to generate paraphrases guided by a target style.
$c$
are inserted into a decoder to generate text in the desired style. Tian et al. (Reference Tian, Hu and Yu2018) extended this approach, adding constraints to preserve style-independent content, using Part-of-speech categories and a content-conditioned language model. Zhao, Kim, Zhang, Rush and LeCun (2018) proposed a regularized adversarial autoencoder that expands the use of adversarial autoencoders to discrete sequences. Park et al. (Reference Park, Hwang, Chen, Choo, Ha, Kim and Yim2019) relied on adversarial training and VAE to expand previous methods to generate paraphrases guided by a target style.
3.3 Non-disentanglement approaches
Although the models included in this category do not assume the need to disentangle content and style from input sentences, they also rely on controlled generation, adversarial learning, reinforcement learning, back-translation, and probabilistic models, similar to some models in the previous categories.
Jain et al. (Reference Jain, Mishra, Azad and Sankaranarayanan2019) proposed a framework for controlled natural language transformation that consists of an encoder–decoder neural network reinforced by transformations carried out through auxiliary modules. Zhang, Ding, and Soricut (Reference Zhang, Ding and Soricut2018) devised the SHAPED method with an architecture that has shared parameters updated from all training examples and not-shared parameters updated with only examples from their respective distributions. Zhou et al. (Reference Zhou, Chen, Liu, Xiao, Su, Guo and Wu2020) proposed a Seq2Seq model that dynamically evaluates the relevance of each output word for the target style. Lample et al. (Reference Lample, Subramanian, Smith, Denoyer, Ranzato and Boureau2019) also used the strategy of learning attribute representations to control text generation. They demonstrated that it is difficult to prove that the style is separated from the disentangled content representation and that performing this disentanglement is unnecessary for the TST task to succeed. Dai et al. (Reference Dai, Liang, Qiu and Huang2019) proposed a transformer-based architecture with trainable style vectors. Our proposal follows this architecture, but it differs in the training strategy since it alters the loss function of the generating network to extract knowledge from a MLM.
The methods presented in Mueller, Gifford, and Jaakkola (Reference Mueller, Gifford and Jaakkola2017); Wang, Hua, and Wan (Reference Wang, Hua and Wan2019); Liu et al. (Reference Liu, Fu, Zhang, Pal and Lv2020); Xu, Cheung, and Cao (Reference Xu, Cheung and Cao2020) have in common the fact that they manipulate the hidden representations obtained from the input sentence to generate texts in the desired style. The method proposed in Mueller et al. (Reference Mueller, Gifford and Jaakkola2017) comprises a recurrent VAE and an output predictor neural network. By imposing boundary conditions during optimization and using the VAE decoder to generate the revised sentences, the method ensures that the transformation is similar to the original sentence, is associated with better outputs, and looks natural. The method devised in Liu et al. (Reference Liu, Fu, Zhang, Pal and Lv2020) has three components: (1) a VAE, which has an encoder that maps the sentence to a smooth continuous vector space and a decoder that maps back the continuous representation to a sentence; (2) attribute predictors, which use the continuous representation obtained by the VAE as input and predict the attributes of the output sentence; and (3) content predictors of a Bag-of-word (BoW) variable for the output sentence. The method proposed in Wang et al. (Reference Wang, Hua and Wan2019) comprises an autoencoder based on Transformers to learn a hidden input representation. Next, the task becomes an optimization problem that edits the obtained hidden representation according to the target attribute. VAE is also the core of the method proposed in Xu et al. (Reference Xu, Cheung and Cao2020) to control text generation. The method proposed in He et al. (Reference He, Wang, Neubig and Berg-Kirkpatrick2020) addresses the TST task with unsupervised learning, formulating it as a probabilistic deep generative model, where the optimization objective arises naturally, without the need to create artificial custom objectives.
Gong et al. (Reference Gong, Bhat, Wu, Xiong and Hwu2019) leveraged reinforcement learning with a generator and an evaluator network. The evaluator is an adversarially trained style discriminator with semantic and syntactic constraints punctuating the sentence generated by style, content preservation, and fluency. The method proposed in Luo et al. (Reference Luo, Li, Zhou, Yang, Chang, Sun and Sui2019) also uses reinforcement learning and considers the problem of transferring style from one domain to another as a dual task. To this end, two rewards are modeled based on this framework to reflect style control and content preservation.
Lai et al. (Reference Lai, Toral and Nissim2021) created a three-step procedure on top of the large pretrained seq2seq model BART (Lewis et al. Reference Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov and Zettlemoyer2020). First, they further pretrain the BART model on an existing collection of generic paraphrases and synthetic pairs created using a general-purpose lexical resource. Second, they use iterative back-translation with several reward strategies to train two models simultaneously, each in a transfer direction. Third, using their best systems from the previous step, they create a static resource of parallel data. These pairs are used to fine-tune the original BART with all reward strategies in a supervised way. As this model, ours also has a preliminary pretraining phase on the same paraphrase data. Nevertheless, our main training procedure differs, relying mostly on adversarial and distillation techniques for style control.
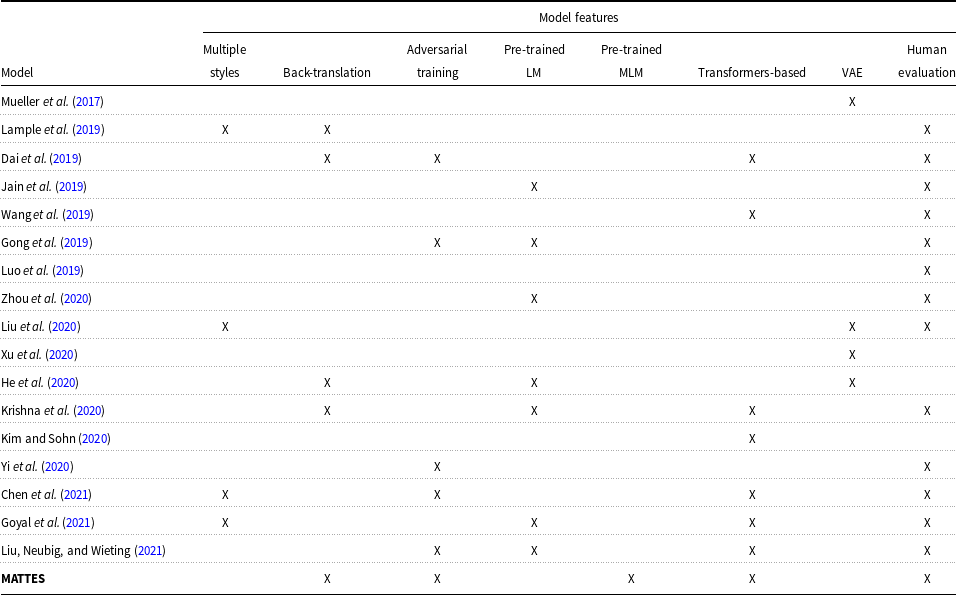
Table 1 exhibits different features of some works from the last 5 years that, like MATTES, do not follow any disentanglement strategy to decouple content from style in the unsupervised TST task.
Table 1. Non-disentaglemet publications according to model characteristics
4. MATTES: Masked transformer for text style transfer
This Section presents MATTES, our proposed approach that distills knowledge from a MLM aiming at improving the quality of the text generated by a Seq2Seq model for the TST task. The MLM adopted here is ALBERT (Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020), a lighter version of the popular BERT that still gets better or competitive results but relies on parameter reduction techniques to improve training efficiency and reduce memory costs.
MATTES follows the architecture established in Dai et al. (Reference Dai, Liang, Qiu and Huang2019), which in turn uses an adversarial training framework (Radford, Metz, and Chintala Reference Radford, Metz and Chintala2016). Training adopts two neural networks. One is a discriminator network operating only during training. The discriminator is a style classifier aiming at making the model learn to differentiate the original and the reconstructed sentences from the translated sentences. The other neural network is the text generator. It comprises an encoder and a decoder, based on a transformer architecture. The generator network receives as input a sentence
 $X$
and a target output style
$X$
and a target output style
 $s^{\text{tgt}}$
and produces a sentence
$s^{\text{tgt}}$
and produces a sentence
 $Y$
in the target style, making the proposed model a mapping function
$Y$
in the target style, making the proposed model a mapping function
 $Y = f_\theta (X,s^{\text{tgt}})$
. The final model learned by MATTES and used for inference is the generator network, while the discriminator network is used only during training.
$Y = f_\theta (X,s^{\text{tgt}})$
. The final model learned by MATTES and used for inference is the generator network, while the discriminator network is used only during training.
Before going into further details about the specific components of MATTES, Section 4.1 formalizes how we investigate the textual style transfer task in this manuscript. Afterward, the main paradigms that constitute the proposed method are presented: Section 4.2 presents the Seq2Seq learning component, and Section 4.3 devises the MLM and the knowledge distillation method that extracts knowledge from the MLM. Finally, Section 4.4 describes the adversarial learning algorithm proposed here and gives additional details about the model architecture and design choices.
4.1 Problem formulation
This manuscript assumes the styles as elements of a set
 $S$
. For example, S = {positive, negative} for the polarity swap task, where the text style can be positive or negative. For training the model, there is a set of sentences
$S$
. For example, S = {positive, negative} for the polarity swap task, where the text style can be positive or negative. For training the model, there is a set of sentences
 $D = \{(X_1,s_1),\ldots,(X_k,s_k)\}$
labeled with their style, that is,
$D = \{(X_1,s_1),\ldots,(X_k,s_k)\}$
labeled with their style, that is,
 $X_i$
is a sentence and
$X_i$
is a sentence and
 $s_i \in S$
is the style attribute of the sentence. From
$s_i \in S$
is the style attribute of the sentence. From
 $D$
, we extract a set of style sentences
$D$
, we extract a set of style sentences
 $D_s = \{ X : (X,s) \in D\}$
, which represent all the sentences of
$D_s = \{ X : (X,s) \in D\}$
, which represent all the sentences of
 $D$
with attribute
$D$
with attribute
 $s$
. In the polarity swap task, it would be all sentences with attribute positive, for example. All sequences in the same dataset
$s$
. In the polarity swap task, it would be all sentences with attribute positive, for example. All sequences in the same dataset
 $D_i$
share specific characteristics related to the style of the sequences.
$D_i$
share specific characteristics related to the style of the sequences.
The goal of the textual style transfer learning task tackled in this manuscript is to build a model that receives as input a sentence
 $X$
and a target style
$X$
and a target style
 $s^{\text{tgt}}$
, where
$s^{\text{tgt}}$
, where
 $X$
is a sentence with style
$X$
is a sentence with style
 $s^{\text{src}} \neq s^{\text{tgt}}$
, and produces a sentence
$s^{\text{src}} \neq s^{\text{tgt}}$
, and produces a sentence
 $Y$
that preserves as much as possible the content of
$Y$
that preserves as much as possible the content of
 $X$
while incorporating the style
$X$
while incorporating the style
 $s^{\text{tgt}}$
. MATTES addresses the problem of style transfer with unsupervised machine learning. Thus, the only data available for training are the sequences
$s^{\text{tgt}}$
. MATTES addresses the problem of style transfer with unsupervised machine learning. Thus, the only data available for training are the sequences
 $X$
and their style source
$X$
and their style source
 $s^{\text{src}}$
. MATTES do not have access to a template sentence
$s^{\text{src}}$
. MATTES do not have access to a template sentence
 $X^{*}$
, which would be the conversion of
$X^{*}$
, which would be the conversion of
 $X$
to the target style
$X$
to the target style
 $s^{\text{tgt}}$
.
$s^{\text{tgt}}$
.
When we adopt the strategy of pretraining the Seq2Seq model, there is another style element in the set
 $S$
that we call the paraphrase style. For the polarity swap task,
$S$
that we call the paraphrase style. For the polarity swap task,
 $S$
would be S = {positive, negative, paraphrase}, for example. This new style is not part of the domain dataset, and it only exists to make it possible to start from the pretrained model in the overall training.
$S$
would be S = {positive, negative, paraphrase}, for example. This new style is not part of the domain dataset, and it only exists to make it possible to start from the pretrained model in the overall training.
4.2 Sequence-to-sequence model
This section describes the sequence-to-sequence architecture and how it is pretrained on a large amount of generic data to improve the model.
4.2.1 Sequence-to-sequence learning architecture
As usual, we adopt the Seq2Seq encoder–decoder paradigm to solve the TST task. Formally, during learning, the model trains to generate an output sequence
 $Y = (y_1, \ldots, y_N )$
of length
$Y = (y_1, \ldots, y_N )$
of length
 $N$
, conditioned on the input sequence
$N$
, conditioned on the input sequence
 $X = (x_1, \ldots, x_M)$
of length
$X = (x_1, \ldots, x_M)$
of length
 $M$
, where
$M$
, where
 $x_i \in X$
and
$x_i \in X$
and
 $y_i \in Y$
are tokens. The encoder–decoder neural network achieves the goal of generating the output sequence by learning a conditional probability distribution
$y_i \in Y$
are tokens. The encoder–decoder neural network achieves the goal of generating the output sequence by learning a conditional probability distribution
 $P_{\theta }(Y|X)$
, by minimizing the cross entropy loss function
$P_{\theta }(Y|X)$
, by minimizing the cross entropy loss function
 $\mathcal{L}(\theta )$
$\mathcal{L}(\theta )$
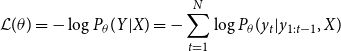 \begin{equation} \begin{split} \mathcal{L}(\theta ) = -\log P_{\theta }(Y|X) = - \sum _{t=1}^{N}\log P_{\theta }(y_t|y_{1:t-1},X) \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}(\theta ) = -\log P_{\theta }(Y|X) = - \sum _{t=1}^{N}\log P_{\theta }(y_t|y_{1:t-1},X) \end{split} \end{equation}
where
 $\theta$
are the model parameters.
$\theta$
are the model parameters.
Following (Dai et al. Reference Dai, Liang, Qiu and Huang2019), in this manuscript, the Transformer (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) architecture is adopted as the Seq2Seq model. During the training and inference process, in addition to the embeddings of the input sentence
 $X$
, the model also receives as input an embedding of the target style. Hence, the input embeddings passed to the encoder are the target style embedding followed by the embeddings of the input sentence, which is the sum of the token embeddings and the positional embeddings, following the Transformer architecture. Thus, the method aims to learn a model that represents a probability distribution conditioned not only on
$X$
, the model also receives as input an embedding of the target style. Hence, the input embeddings passed to the encoder are the target style embedding followed by the embeddings of the input sentence, which is the sum of the token embeddings and the positional embeddings, following the Transformer architecture. Thus, the method aims to learn a model that represents a probability distribution conditioned not only on
 $X$
but also on the desired target style
$X$
but also on the desired target style
 $s^{\text{tgt}}$
. Thus, Equation (2) is modified to meet this characteristic, giving rise to the loss function
$s^{\text{tgt}}$
. Thus, Equation (2) is modified to meet this characteristic, giving rise to the loss function
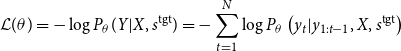 \begin{equation} \begin{split} \mathcal{L}(\theta ) = -\log P_{\theta }(Y|X,s^{\text{tgt}}) = - \sum _{t=1}^{N}\log P_{\theta }\left(y_t|y_{1:t-1},X,s^{\text{tgt}}\right) \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}(\theta ) = -\log P_{\theta }(Y|X,s^{\text{tgt}}) = - \sum _{t=1}^{N}\log P_{\theta }\left(y_t|y_{1:t-1},X,s^{\text{tgt}}\right) \end{split} \end{equation}
4.2.2 Sequence-to-sequence pre-training
Pretraining and fine-tuning are usually adopted when target tasks have few examples available (Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018; Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). Several pretraining approaches adopt MLM, a kind of denoising auto-encoder trained to reconstruct the text where some random words have been masked. This kind of pretraining has mainly improved the performance of natural language understanding tasks, which can be justified by the fact that MLMs are composed only of a bidirectional encoder, while generation tasks adopt a left-to-right decoder. In this sense, the model BART (Lewis et al. Reference Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov and Zettlemoyer2020) combined bidirectional and auto-regressive transformers to show that sequence-to-sequence pretraining can benefit downstream language generation tasks.
Following this rationale, we pretrain our Seq2Seq model in a large collection of paraphrase pairs (Hu et al. Reference Hu, Singh, Holzenberger, Post and Van Durme2019). With that, we expect the model to learn the primary task of rewriting, allowing the generation of pseudo-parallel data and, consequently, handling the style transfer in a supervised fashion. We added another style embedding inside our style embedding layer to adapt this technique to our training framework. This way, besides the actual styles of the sentences, there is an additional one that we refer to as
 $s^{\text{para}}$
. It is the only style inserted into the model during the pretraining phase. During this phase, we minimize the following loss function
$s^{\text{para}}$
. It is the only style inserted into the model during the pretraining phase. During this phase, we minimize the following loss function
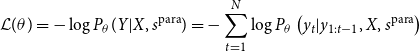 \begin{equation} \begin{split} \mathcal{L}(\theta ) = -\log P_{\theta }(Y|X,s^{\text{para}}) = - \sum _{t=1}^{N}\log P_{\theta }\left(y_t|y_{1:t-1},X,s^{\text{para}}\right) \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}(\theta ) = -\log P_{\theta }(Y|X,s^{\text{para}}) = - \sum _{t=1}^{N}\log P_{\theta }\left(y_t|y_{1:t-1},X,s^{\text{para}}\right) \end{split} \end{equation}
4.3 Knowledge distillation
This section starts by describing the MLM adopted in this manuscript. Next, it devised the knowledge distillation strategy proposed here to leverage the MLM.
4.3.1 Masked language model
One of the main contributions of this manuscript is to introduce the ability to transfer knowledge contained in the rich bidirectional contextualized representations provided by a MLM to a Seq2Seq model. MATTES adopts ALBERT (Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020) as the MLM, whose architecture is similar to the popular BERT model (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) but has fewer parameters.
From the language model learned by ALBERT, one can obtain the probability distribution of the masked tokens according to
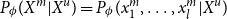 \begin{equation} \begin{split} P_{\phi }(X^m|X^u) = P_{\phi }(x_1^m, \ldots, x_l^m|X^u) \end{split} \end{equation}
\begin{equation} \begin{split} P_{\phi }(X^m|X^u) = P_{\phi }(x_1^m, \ldots, x_l^m|X^u) \end{split} \end{equation}
where
 $x_*^m \in X^m$
are the masked tokens,
$x_*^m \in X^m$
are the masked tokens,
 $l$
is the number of masked tokens in
$l$
is the number of masked tokens in
 $X$
,
$X$
,
 $X^u$
are the unmasked tokens, and
$X^u$
are the unmasked tokens, and
 $\phi$
are ALBERT parameters.
$\phi$
are ALBERT parameters.
Before training the main model, we fine-tuned ALBERT with the available training dataset. Although ALBERT is prepared to handle a couple of sentences as inputs, given the problem definition, only one sentence is required. This is true either when fine-tuning or when training the main Seq2Seq model. Because of that, MATTES does not adopt ALBERT Sentence-order prediction loss component during the fine-tuning. When training the main TST model, ALBERT parameters do not change. As the next section explains, MATTES uses the probability distribution provided by ALBERT for each token of the input sentence as a label for training the model in one of the components of the loss function. Thus, instead of forcing the model to generate a probability distribution with the entire probability mass in a single token, the model is forced to have a smoother probability distribution, injecting probability mass into several tokens.
4.3.2 Knowledge distillation from the masked language model
This section details how we introduce the knowledge distillation strategy into the model loss function. To preserve the content of the original message, several previous TST methods adopt a back-translation (BT) strategy (Lample et al. Reference Lample, Subramanian, Smith, Denoyer, Ranzato and Boureau2019; Dai et al. Reference Dai, Liang, Qiu and Huang2019; He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020; Lai et al. Reference Lai, Toral and Nissim2021), proposed in Sennrich, Haddow, and Birch (Reference Sennrich, Haddow and Birch2016) for the machine translation task. BT generates pseudo-parallel sequences for training when no parallel sentences are available in the examples, thus generating latent parallel data. Thus, in the context of the TST task, pairs of sentences are created to train the model by automatically converting sentences from the training set to another style.
During training, the BT component takes a sentence
 $X$
and its style
$X$
and its style
 $s$
as input and converts it to a target style target
$s$
as input and converts it to a target style target
 $\hat{s}\neq s$
, generating the sentence
$\hat{s}\neq s$
, generating the sentence
 $\hat{Y} = f_\theta (X, \hat{s})$
. After that, the generated sentence
$\hat{Y} = f_\theta (X, \hat{s})$
. After that, the generated sentence
 $\hat{Y}$
is passed as input to the model along with the original style
$\hat{Y}$
is passed as input to the model along with the original style
 $s$
, and the network is trained to learn to predict the original input sentence
$s$
, and the network is trained to learn to predict the original input sentence
 $X$
. The input sentence is first converted to the target style and then converted back to its original style.
$X$
. The input sentence is first converted to the target style and then converted back to its original style.
The method proposed in Dai et al. (Reference Dai, Liang, Qiu and Huang2019) adopts the back-translation strategy to learn a TST model, minimizing the negative value of the logarithm of the probability that the generated sentence is equal to the original sentence with
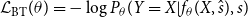 \begin{equation} \begin{split} \mathcal{L}_{\text{BT}}(\theta ) = -\log P_{\theta }(Y=X|f_\theta (X,\hat{s}),s) \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}_{\text{BT}}(\theta ) = -\log P_{\theta }(Y=X|f_\theta (X,\hat{s}),s) \end{split} \end{equation}
where
 $f_\theta (X, \hat{s})$
indicates the converted sentence and
$f_\theta (X, \hat{s})$
indicates the converted sentence and
 $s$
is the original input style.
$s$
is the original input style.
Sequence-to-sequence models are normally trained from left to right. Thus, when generating each token to compose the sentence, the vocabulary probability distribution is conditioned only to the previous tokens in the sentence. This is to avoid each token seeing itself and the others after it. However, such an approach has the disadvantage of estimating the probability distribution only with the left context.
MATTES uses a configuration called masked transformer during training to overcome this limitation and generate a distribution that includes bidirectional information. The adoption of this architecture in the style transfer task comes from the observation that the probability distribution of a masked token
 $x_t^{m}$
given by an MLM contains both past and future context information. Thus, as no sentence pairs are available to perform supervised training, the central idea is to force MATTES to generate a distribution provided by ALBERT for each token. By doing that, MATTES smooths the probability curve and spreads probability mass over more tokens. Such additional information can improve the quality of the generated texts and, in particular, the style control of the model. Thus, during the optimization of the loss function component related to the back-translation (Equation 6), the target is no longer the distribution in which the entire probability mass is in a single token. Instead, it becomes the probability distribution given by the MLM
$x_t^{m}$
given by an MLM contains both past and future context information. Thus, as no sentence pairs are available to perform supervised training, the central idea is to force MATTES to generate a distribution provided by ALBERT for each token. By doing that, MATTES smooths the probability curve and spreads probability mass over more tokens. Such additional information can improve the quality of the generated texts and, in particular, the style control of the model. Thus, during the optimization of the loss function component related to the back-translation (Equation 6), the target is no longer the distribution in which the entire probability mass is in a single token. Instead, it becomes the probability distribution given by the MLM
 $P_{\phi }(x_t^m|X^u)$
(Equation 5), for each token
$P_{\phi }(x_t^m|X^u)$
(Equation 5), for each token
 $x_t$
of the sentence input. The distribution provided by the MLM becomes a softer target for text generation during training, moving the model away from learning a more abrupt and unreal distribution, where the entire probability mass is in a single token.
$x_t$
of the sentence input. The distribution provided by the MLM becomes a softer target for text generation during training, moving the model away from learning a more abrupt and unreal distribution, where the entire probability mass is in a single token.
Another point that MATTES leverages with MLM is the use of a knowledge distillation scheme (Hinton, Vinyals, and Dean Reference Hinton, Vinyals and Dean2015). Distilling consists of extracting the knowledge contained in one model through a specific training technique. This technique is commonly used to transfer information from a large, already trained model, a teacher, to a smaller model, a student, better suited for production. In such a scheme, the student uses the teacher’s output values as the goal, instead of relying on the training set labels. The distillation process controls better the optimization and regularization of the training process (Phuong and Lampert Reference Phuong and Lampert2019).
Several previous distillation methods train both the teacher and the student in the same task, aiming at model compression (Hinton et al. Reference Hinton, Vinyals and Dean2015; Sun et al. Reference Sun, Cheng, Gan and Liu2019). Here, we have a different goal, as we use distillation to take advantage of pretrained bidirectional representations generated through a MLM. Thus, ALBERT provides smoother labels to be used as targets during training in the knowledge distillation component of the Seq2Seq loss function, inspired by the method proposed in Chen et al. (Reference Chen, Gan, Cheng, Liu and Liu2020), to improve the quality of the generated text.
MATTES benefits from the distillation scheme by making the MLM assume the teacher’s role, while the unsupervised Seq2Seq model behaves like the student. Equation (7) shows how we adapt the back-translation component to be a bidirectional knowledge distillation component:
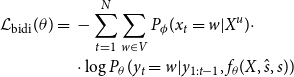 \begin{equation} \begin{aligned} \mathcal{L}_{\text{bidi}}(\theta ) ={} & -\sum _{t=1}^{N} \sum _{w \in V}P_{\phi }(x_t = w |X^u) \cdot \\ &\cdot \log P_{\theta }(y_t = w |y_{1:t-1},f_\theta (X,\hat{s},s)) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \mathcal{L}_{\text{bidi}}(\theta ) ={} & -\sum _{t=1}^{N} \sum _{w \in V}P_{\phi }(x_t = w |X^u) \cdot \\ &\cdot \log P_{\theta }(y_t = w |y_{1:t-1},f_\theta (X,\hat{s},s)) \end{aligned} \end{equation}
where
 $P_{\phi }(x_t)$
is the soft target provided by the MLM with learned parameters
$P_{\phi }(x_t)$
is the soft target provided by the MLM with learned parameters
 $\phi$
,
$\phi$
,
 $N$
is the sentence length, and
$N$
is the sentence length, and
 $V$
denotes the vocabulary. Note that the parameters of the MLM are fixed during the training process. Figure 1 illustrates the learning process, where the objective is to make the probability distribution of the word
$V$
denotes the vocabulary. Note that the parameters of the MLM are fixed during the training process. Figure 1 illustrates the learning process, where the objective is to make the probability distribution of the word
 $P_\theta (y_t)$
, provided by the student, be closer to the distribution provided by the teacher,
$P_\theta (y_t)$
, provided by the student, be closer to the distribution provided by the teacher,
 $ P_\phi (x_t)$
.
$ P_\phi (x_t)$
.
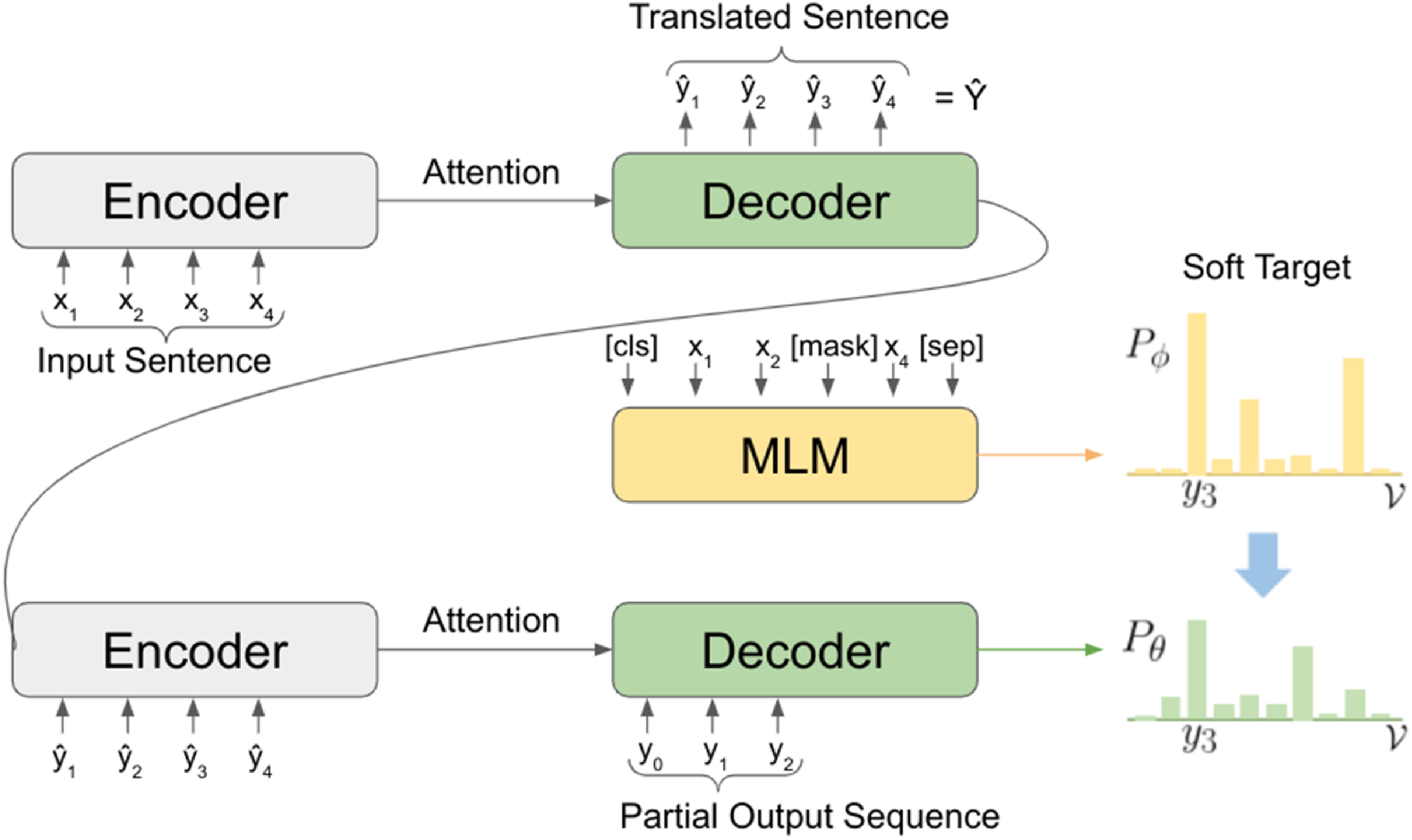
Figure 1. Training illustration when the model is predicting the token
 $y_3$
using an MLM.
$y_3$
using an MLM.
 $P_\theta$
is the student distribution, while
$P_\theta$
is the student distribution, while
 $P_\phi$
is the teacher soft distribution provided by the MLM.
$P_\phi$
is the teacher soft distribution provided by the MLM.
MATTES is trained with an adapted back-translation method that implements a knowledge distillation procedure:
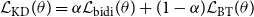 \begin{equation} \begin{split} \mathcal{L}_{\text{KD}}(\theta ) = \alpha \mathcal{L}_{\text{bidi}}(\theta ) + (1-\alpha )\mathcal{L}_{\text{BT}}(\theta ) \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}_{\text{KD}}(\theta ) = \alpha \mathcal{L}_{\text{bidi}}(\theta ) + (1-\alpha )\mathcal{L}_{\text{BT}}(\theta ) \end{split} \end{equation}
where
 $\alpha$
is a hyperparameter to adjust the relative importance of the soft targets provided by the MLM and the original targets.
$\alpha$
is a hyperparameter to adjust the relative importance of the soft targets provided by the MLM and the original targets.
With the introduction of the new loss function term, the distribution is forced to become smoother during training. When the traditional one-hot representations are used as a target during training, the model is forced to generate the correct token. All other tokens do not matter to the model, treating equally tokens that would be more likely to occur and tokens with almost zero chance of occurring. In this way, by relying on a smoother distribution, the model increases its potential to generate more fluent sentences as the probability spreads over more tokens. Also, a smoother distribution avoids token generation entirely out of context and better controls the desired style.
4.4 Learning algorithm
Training the model proposed here follows the algorithm defined in Dai et al. (Reference Dai, Liang, Qiu and Huang2019). Both the discriminator and the generator networks are trained adversarially. First, we describe how to train the discriminator network and then the generator, where the masked transformer proposed in this manuscript is inserted.
4.4.1 Learning the discriminator network
The discriminator neural network is a multiclass classifier with
 $K+1$
classes.
$K+1$
classes.
 $K$
classes are associated with
$K$
classes are associated with
 $K$
different styles, and the remaining class refers to the converted sentences generated by the masked Transformer. The discriminator network is trained to distinguish the original and the reconstructed sentences from the translated sentences. It means the classifier is trained to classify a sentence
$K$
different styles, and the remaining class refers to the converted sentences generated by the masked Transformer. The discriminator network is trained to distinguish the original and the reconstructed sentences from the translated sentences. It means the classifier is trained to classify a sentence
 $X$
with style
$X$
with style
 $s$
and its reconstructed sentence
$s$
and its reconstructed sentence
 $Y$
, as belonging to the class
$Y$
, as belonging to the class
 $s$
, and the translated
$s$
, and the translated
 $\hat{Y}$
as belonging to the class of translated sentences. Accordingly, its loss function is defined as
$\hat{Y}$
as belonging to the class of translated sentences. Accordingly, its loss function is defined as
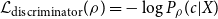 \begin{equation} \begin{split} \mathcal{L}_{\text{discriminator}}(\rho ) = -\log P_{\rho }(c|X) \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}_{\text{discriminator}}(\rho ) = -\log P_{\rho }(c|X) \end{split} \end{equation}
where
 $\rho$
are the parameters of the discriminator network,
$\rho$
are the parameters of the discriminator network,
 $c$
is the stylistic domain of the sample that can assume
$c$
is the stylistic domain of the sample that can assume
 $K+1$
categories. The parameters
$K+1$
categories. The parameters
 $\theta$
of the generator network are not updated when training the discriminator.
$\theta$
of the generator network are not updated when training the discriminator.
4.4.2 Learning the generator network
A reconstruction component, a knowledge distillation component, and an adversarial component compose the final loss function of the masked transformer, as follows.
Input sentence reconstruction component
When the model receives as input a sentence
 $X$
along with its style
$X$
along with its style
 $s$
, the model must be able to reconstruct the original sentence. The following reconstruction component is added to the loss function to make the model achieve this ability:
$s$
, the model must be able to reconstruct the original sentence. The following reconstruction component is added to the loss function to make the model achieve this ability:
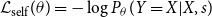 \begin{equation} \mathcal{L}_{\text{self}}(\theta ) = -\log P_{\theta }(Y=X|X,s) \end{equation}
\begin{equation} \mathcal{L}_{\text{self}}(\theta ) = -\log P_{\theta }(Y=X|X,s) \end{equation}
During training,
 $\mathcal{L}_{\text{self}}$
is optimized in the traditional way, that is, from left to right, masking the future context, according to Equation (3). Despite being possible, this component does not adopt the technique of knowledge distillation as we would like to isolate the distillation to a single component and verify its benefit.
$\mathcal{L}_{\text{self}}$
is optimized in the traditional way, that is, from left to right, masking the future context, according to Equation (3). Despite being possible, this component does not adopt the technique of knowledge distillation as we would like to isolate the distillation to a single component and verify its benefit.
Knowledge distillation component
To extract knowledge from a pretrained MLM to improve the transductive process of converting a sentence from one style to another, we introduce the following knowledge distillation component
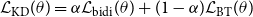 \begin{equation} \begin{split} \mathcal{L}_{\text{KD}}(\theta ) = \alpha \mathcal{L}_{\text{bidi}}(\theta ) + (1-\alpha )\mathcal{L}_{\text{BT}}(\theta ) \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}_{\text{KD}}(\theta ) = \alpha \mathcal{L}_{\text{bidi}}(\theta ) + (1-\alpha )\mathcal{L}_{\text{BT}}(\theta ) \end{split} \end{equation}
where
 $\mathcal{L}_{\text{BT}}$
is as Equation (6) and
$\mathcal{L}_{\text{BT}}$
is as Equation (6) and
 $\mathcal{L}_{\text{bidi}}$
is defined as Equation (7). With this, we expect to smooth the probability distribution of the style converter model, producing more fluent sentences resembling the target domain texts.
$\mathcal{L}_{\text{bidi}}$
is defined as Equation (7). With this, we expect to smooth the probability distribution of the style converter model, producing more fluent sentences resembling the target domain texts.
During training, to generate the knowledge distillation component (Equation 11) of our cost function, the translated sentence style
 $\hat{s}$
inserted into the generator network to obtain
$\hat{s}$
inserted into the generator network to obtain
 $\hat{Y}$
depends on whether we are training from scratch or using the generator network already pretrained on paraphrase data. In the former case, as we do not have the style
$\hat{Y}$
depends on whether we are training from scratch or using the generator network already pretrained on paraphrase data. In the former case, as we do not have the style
 $s^{\text{para}}$
, we convert it to the other existing style. On the latter,
$s^{\text{para}}$
, we convert it to the other existing style. On the latter,
 $\hat{Y}$
is created according to the paraphrase style
$\hat{Y}$
is created according to the paraphrase style
 $s^{\text{para}}$
. In both approaches,
$s^{\text{para}}$
. In both approaches,
 $\hat{Y}$
is inserted back into the network along with the original style
$\hat{Y}$
is inserted back into the network along with the original style
 $s$
to generate our final probability distribution
$s$
to generate our final probability distribution
 $P_\theta$
. This architectural modification unlocks our model to handle multiple styles at once. This way, regardless of the number of style domains, during training, we translate to
$P_\theta$
. This architectural modification unlocks our model to handle multiple styles at once. This way, regardless of the number of style domains, during training, we translate to
 $s^{\text{para}}$
and then back to
$s^{\text{para}}$
and then back to
 $s^{\text{src}}$
. In inference time, we first translate to
$s^{\text{src}}$
. In inference time, we first translate to
 $s^{\text{para}}$
and then to
$s^{\text{para}}$
and then to
 $s^{\text{tgt}}$
. Translating to the paraphrase style can be thought of as normalizing the input sentence, striping out stylistic information regarding the source style.
$s^{\text{tgt}}$
. Translating to the paraphrase style can be thought of as normalizing the input sentence, striping out stylistic information regarding the source style.
Adversarial component
When adopting the training from scratch approach, if the model is only trained with the sentence reconstruction and knowledge distillation components, it could quickly converge to learn to copy the input sentence, that is, stick to learning the identity function. Thus, to avoid this problematic and unwanted behavior, an adversarial component is added to the cost function to encourage texts converted to style
 $\hat{s}$
, different from the input sentence style
$\hat{s}$
, different from the input sentence style
 $s$
, to get closer to texts from the style
$s$
, to get closer to texts from the style
 $\hat{s}$
.
$\hat{s}$
.
In the scenario with the presence of paraphrase style, the adversarial component tries to modify the generator such that the generated paraphrase sentence
 $\hat{Y}$
is pushed to become similar to other existing styles of the training set, as long as they are different from
$\hat{Y}$
is pushed to become similar to other existing styles of the training set, as long as they are different from
 $s^{\text{src}}$
.
$s^{\text{src}}$
.
Generalizing for both approaches, the converted sentence
 $\hat{Y}$
is inserted into the discriminator neural network and, during training, the probability of the generated sentence being of the style
$\hat{Y}$
is inserted into the discriminator neural network and, during training, the probability of the generated sentence being of the style
 $s^{\text{tgt}}$
, such that
$s^{\text{tgt}}$
, such that
 $s^{\text{tgt}}$
$s^{\text{tgt}}$
 $\neq$
$\neq$
 $s^{\text{src}}$
and
$s^{\text{src}}$
and
 $s^{\text{tgt}}$
$s^{\text{tgt}}$
 $\neq$
$\neq$
 $s^{\text{para}}$
, is maximized through optimization of the loss function defined in Equation 12. The
$s^{\text{para}}$
, is maximized through optimization of the loss function defined in Equation 12. The
 $\rho$
parameters of the discriminator network are not updated when training the generator network.
$\rho$
parameters of the discriminator network are not updated when training the generator network.
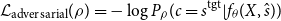 \begin{equation} \begin{split} \mathcal{L}_{\text{adversarial}}(\rho ) = -\log P_{\rho }(c=s^{\text{tgt}}|f_\theta (X,\hat{s})) \end{split} \end{equation}
\begin{equation} \begin{split} \mathcal{L}_{\text{adversarial}}(\rho ) = -\log P_{\rho }(c=s^{\text{tgt}}|f_\theta (X,\hat{s})) \end{split} \end{equation}
These three loss functions are merged, and the overall objective for the generator network becomes:
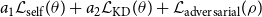 \begin{equation} \begin{split} a_1\mathcal{L}_{\text{self}}(\theta )+a_2\mathcal{L}_{\text{KD}}(\theta )+\mathcal{L}_{\text{adversarial}}(\rho ) \end{split} \end{equation}
\begin{equation} \begin{split} a_1\mathcal{L}_{\text{self}}(\theta )+a_2\mathcal{L}_{\text{KD}}(\theta )+\mathcal{L}_{\text{adversarial}}(\rho ) \end{split} \end{equation}
where
 $a_1$
and
$a_1$
and
 $a_2$
are hyperparameters to adjust each component’s importance in the loss function of the generator network.
$a_2$
are hyperparameters to adjust each component’s importance in the loss function of the generator network.
4.4.3 Adversarial training
Generative adversarial networks (GANs) (Goodfellow et al. Reference Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville and Bengio2014) are differentiable generator neural networks based on a game theory scenario where a generator network must compete against an opponent. The generator network produces samples
 $x=g(z;\theta ^{(g)})$
. The discriminator network’s adversary aims to distinguish between samples from the training set and the generator network. Thus, during training, the discriminator learns to classify samples as real or artificially generated by the generator network. Simultaneously, the generator network tries to trick the discriminator and produces samples that look like they are coming from the probability distribution of the dataset. At convergence, the generator samples will be indistinguishable from the actual training set samples, and the discriminator network can be dropped.
$x=g(z;\theta ^{(g)})$
. The discriminator network’s adversary aims to distinguish between samples from the training set and the generator network. Thus, during training, the discriminator learns to classify samples as real or artificially generated by the generator network. Simultaneously, the generator network tries to trick the discriminator and produces samples that look like they are coming from the probability distribution of the dataset. At convergence, the generator samples will be indistinguishable from the actual training set samples, and the discriminator network can be dropped.
In the context of this manuscript, the adversarial strategy can be better understood according to the approach adopted. When training from scratch, it aims at converting texts to the desired style without incurring the failure to copy the input text. When training from a pretrained paraphrase model, the adversarial technique tries to push the generated paraphrases toward different styles
 $s^{\text{tgt}}$
, such that
$s^{\text{tgt}}$
, such that
 $s^{\text{tgt}}$
$s^{\text{tgt}}$
 $\neq$
$\neq$
 $s^{\text{src}}$
and
$s^{\text{src}}$
and
 $s^{\text{tgt}}$
$s^{\text{tgt}}$
 $\neq$
$\neq$
 $s^{\text{para}}$
. The general training procedure consists of, repeatedly, performing
$s^{\text{para}}$
. The general training procedure consists of, repeatedly, performing
 $n_d$
discriminator training steps, minimizing
$n_d$
discriminator training steps, minimizing
 $\mathcal{L}_{\text{discriminator}}(\rho )$
, followed by
$\mathcal{L}_{\text{discriminator}}(\rho )$
, followed by
 $n_f$
generator network training steps, minimizing
$n_f$
generator network training steps, minimizing
 $a_1\mathcal{L}_{\text{self}}(\theta )+a_2\mathcal{L}_{\text{KD}}(\theta )+\mathcal{L}_{\text{adversarial}}(\rho )$
, until convergence. During the discriminator training steps, only the
$a_1\mathcal{L}_{\text{self}}(\theta )+a_2\mathcal{L}_{\text{KD}}(\theta )+\mathcal{L}_{\text{adversarial}}(\rho )$
, until convergence. During the discriminator training steps, only the
 $\rho$
parameters of the discriminator network are updated. Analogously, during the generator network training steps, only the parameters
$\rho$
parameters of the discriminator network are updated. Analogously, during the generator network training steps, only the parameters
 $\theta$
of the masked transformer are updated. Figure 2 illustrates the adversarial training adopted by MATTES.
$\theta$
of the masked transformer are updated. Figure 2 illustrates the adversarial training adopted by MATTES.
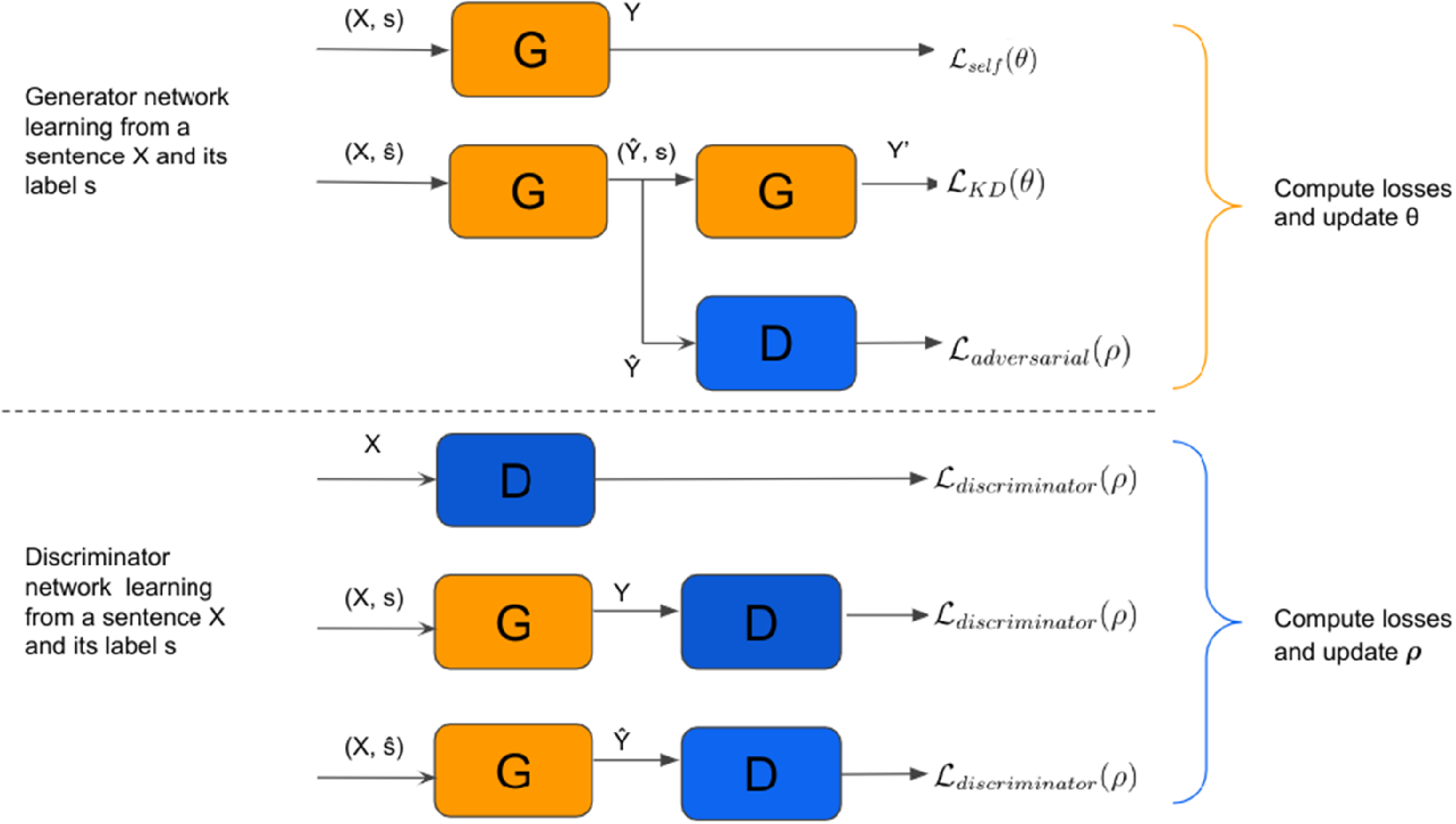
Figure 2. Adversarial training illustration.
 $G$
denotes the generator network, while
$G$
denotes the generator network, while
 $D$
denotes the discriminator network.
$D$
denotes the discriminator network.
When back-translating during training (Figure 1), MATTES do not generate the transformed sentence
 $\hat{Y}$
through sampling or greedy decoding from the transductive probability distribution provided by the generator network. This decision is because propagating the gradients backward through discrete stochastic operations is not differentiable, typically requiring techniques such as REINFORCE (Williams Reference Williams1992) or Gumbel-Softmax distribution approximation (Jang, Gu, and Poole Reference Jang, Gu and Poole2017), which suffer from high variance (He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020). To overcome this difficulty, the softmax distribution generated by the MATTES decoder is inserted again into the MATTES encoder, along with the original sentence style, as in Dai et al. (Reference Dai, Liang, Qiu and Huang2019). This configuration makes it possible to directly propagate the gradients from the discriminator and generator networks to the reverse model that generated the target style translated sentences.
$\hat{Y}$
through sampling or greedy decoding from the transductive probability distribution provided by the generator network. This decision is because propagating the gradients backward through discrete stochastic operations is not differentiable, typically requiring techniques such as REINFORCE (Williams Reference Williams1992) or Gumbel-Softmax distribution approximation (Jang, Gu, and Poole Reference Jang, Gu and Poole2017), which suffer from high variance (He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020). To overcome this difficulty, the softmax distribution generated by the MATTES decoder is inserted again into the MATTES encoder, along with the original sentence style, as in Dai et al. (Reference Dai, Liang, Qiu and Huang2019). This configuration makes it possible to directly propagate the gradients from the discriminator and generator networks to the reverse model that generated the target style translated sentences.
Overall, the MATTES architectural scheme includes a four-layer transformer architecture with four attention heads in each layer, for both the encoder and the decoder, and the discriminator network, as in Dai et al. (Reference Dai, Liang, Qiu and Huang2019). The vector representations of tokens, hidden states, and token position in the sentence have 256 dimensions. When training from scratch, we have a style embedding layer with two 256-dimensional vectors representing the stylistic domains. When starting from the pretrained Seq2seq, we have three vectors as we append the paraphrase style to the set of styles. The target style vector is inserted into the encoder along with the embeddings of each token of the sentence.
In the experiments, we do not include the start sentence token, only the end sequence token. During training, we replaced this token embedding with the style embedding as the first input embedding of the sequence. Thus, the vectors representing the styles are also trained and are part of the model.
This section described a machine learning method that addresses the unsupervised TST task using a Seq2Seq model pretrained in a large amount of paraphrase data and an MLM inserted into the training process with a knowledge distillation configuration. The Seq2Seq pretraining phase allows the model to create synthetically generated paraphrase pairs on-the-fly during training to help the transduction process. The distillation schema aims to extract knowledge from the MLM and enrich the text-generated quality. To verify if the proposed method improves the performance of TST, we conduct an experimental evaluation in the next section.
5. Experiments
We evaluated MATTES on three different style transfer tasks in the English language: author imitation, formality transfer, and polarity swap. This section presents the experimental methodology adopted to carry out the experiments, the quantitative results from five automated metrics, qualitative analyses, human evaluations, comparisons with related work, and ablation studies.
5.1 Experimental methodology
Here, we describe the datasets of the style transfer tasks, the models whose results we compare, the assessment metrics, and model training details.
5.1.1 Datasets and tasks
MATTES was evaluated in three transfer style tasks in the English language: author imitation, formality transfer, and polarity swap. The author imitation task consists of converting the style of a sentence to the style of a particular author. The aim is to generate a paraphrase of the original sentence but with a different textual style. To verify the ability of MATTES to perform this task, we rely on a set of 21,000 (twenty-one thousand) sentences from William Shakespeare’s plays, transcribed into modern English. As they are translations from English into English, this dataset is also an intra-linguistic translation. The author imitation task can be considered an adaptation, where a text is modified within the language. In this case, it is a sum of two processes: a temporal and a linguistic adaptation. This dataset was curated in Xu et al. (Reference Xu, Ritter, Dolan, Grishman and Cherry2012) and previously used in unsupervised textual style transfer jobs (He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020; Krishna et al. Reference Krishna, Wieting and Iyyer2020). The dataset is divided into training, validation, and testing sets. We adopt
 $s_1$
to denote modern English and
$s_1$
to denote modern English and
 $\mathcal{D}_1$
for the dataset referring to this style. In contrast,
$\mathcal{D}_1$
for the dataset referring to this style. In contrast,
 $s_2$
denotes Shakesperian English, and
$s_2$
denotes Shakesperian English, and
 $\mathcal{D}_2$
denotes the domain of the sentences in Shakesperian English. We evaluate MATTES both to transfer sentences from
$\mathcal{D}_2$
denotes the domain of the sentences in Shakesperian English. We evaluate MATTES both to transfer sentences from
 $s_1$
to
$s_1$
to
 $s_2$
and from
$s_2$
and from
 $s_2$
to
$s_2$
to
 $s_1$
. Although sentence pairs exist, they are not used in pairs during training but only to evaluate results.
$s_1$
. Although sentence pairs exist, they are not used in pairs during training but only to evaluate results.
In the formality transfer task, our goal is to change the formality of the sentence while preserving its meaning. For this task, we adopted the GYAFC corpus (Rao and Tetreault Reference Rao and Tetreault2018), which contains formal and informal sentences from two domains: Entertainment & Music (E&M) and Family & Relationships (F&R). For every sentence from validation and test sets, there are four human-written references. In the experiments, we use the most commonly used F&R domain. The dataset contains 51,967 training examples in each formal and informal class. The test set has 2351 examples. We denote the formal style as
 $s_1$
and its domain as
$s_1$
and its domain as
 $\mathcal{D}_1$
, while the informal style is denoted by
$\mathcal{D}_1$
, while the informal style is denoted by
 $s_2$
and its domain is
$s_2$
and its domain is
 $\mathcal{D}_2$
. MATTES is evaluated both to transfer sentences from
$\mathcal{D}_2$
. MATTES is evaluated both to transfer sentences from
 $s_1$
to
$s_1$
to
 $s_2$
and from
$s_2$
and from
 $s_2$
to
$s_2$
to
 $s_1$
.
$s_1$
.
The polarity swap task consists of converting the sentence to a different sentiment, preserving its general theme. In this task, we rely on the YELP dataset, collected in Shen et al. (Reference Shen, Lei, Barzilay and Jaakkola2017), which includes establishment evaluations performed within the YELP application. The dataset contains 250,000 negative sentences and 380,000 positive sentences. To quantitatively assess the generalization skills of the transfer models, we rely on a test set with 1000 parallel sentences annotated by humans, introduced in Li et al. (Reference Li, Jia, He and Liang2018). We denote the positive sentiment style as
 $s_1$
and its domain as
$s_1$
and its domain as
 $\mathcal{D}_1$
, while the negative sentiment style is denoted by
$\mathcal{D}_1$
, while the negative sentiment style is denoted by
 $s_2$
and its domain is
$s_2$
and its domain is
 $\mathcal{D}_2$
. Again, MATTES is evaluated both to transfer sentences from
$\mathcal{D}_2$
. Again, MATTES is evaluated both to transfer sentences from
 $s_1$
to
$s_1$
to
 $s_2$
and from
$s_2$
and from
 $s_2$
to
$s_2$
to
 $s_1$
.
$s_1$
.
Although these tasks have been handled indiscriminately as TST tasks, they have crucial differences that might indicate they should be treated differently during modeling and evaluation. More specifically, in polarity swap, the content is not strictly preserved (the message is actually the opposite). The important is to preserve the overall topic. In author imitation and formality transfer, instead, the “translation” happens more at the style level, and content must remain the same. In YELP, we can see that words related to the theme are intended to be retained, while polarity words are expected to be modified or replaced. On the contrary, in author imitation and formality transfer, the modifications happen at the stylistic level, affecting even noun phrases, but the essential message should be conserved. Since these two tasks can be seen much more as a rewriting task than the polarity swap, we expect the paraphrase pretraining strategy to benefit them more.
5.1.2 Baselines
We compare MATTES to recent models that made available the transferred test suite sentences. In the author imitation task, the results were compared with the Deep Latent Sequence (DLSM) (He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020) and STRAP (Krishna et al. Reference Krishna, Wieting and Iyyer2020) models, which showed relevant results in the metrics of content preservation. As the Style Transformer (Dai et al. Reference Dai, Liang, Qiu and Huang2019) model did not perform this task, we built an in-house implementation of this model so that its output samples could be compared with MATTES. Regarding the polarity swap task, we compare MATTES with the results of other models that obtained state-of-the-art (SOA) results for this task, including again the DLSM (He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020) and Style Transformer (Dai et al. Reference Dai, Liang, Qiu and Huang2019), in addition to the model proposed in Lai et al. (Reference Lai, Toral and Nissim2021) and also the RETRIEVEONLY, RULE-BASED, and DELETEANDRETRIVE models, which obtained the best results in the experiments published in Li et al. (Reference Li, Jia, He and Liang2018). For the formality transfer task, we also compared with the SOTA models that made their outputs available (Luo et al. Reference Luo, Li, Zhou, Yang, Chang, Sun and Sui2019; Yi et al. Reference Yi, Liu, Li and Sun2020; Lai et al. Reference Lai, Toral and Nissim2021).
5.1.3 Metrics for quantitative evaluation
Developing reliable automatic evaluation metrics for NLG tasks that reflect human judgment accordingly is still an open research field. However, automatic evaluation is cheaper and faster to run than human evaluation. Thus, first, we gather the most used automatic evaluation metrics from the literature (Yang et al. Reference Yang, Hu, Dyer, Xing and Berg-Kirkpatrick2018; Lample et al. Reference Lample, Subramanian, Smith, Denoyer, Ranzato and Boureau2019; He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020) focusing on two dimensions that effective textual transfer style systems must preserve.
Considering that content preservation is the most desired feature to style transfer, three distinct metrics were used to evaluate the models according to this dimension: BLEU (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002), BartScore (Yuan et al. Reference Yuan, Neubig and Liu2021) and semantic similarity (SIM) (Wieting et al. Reference Wieting, Berg-Kirkpatrick, Gimpel and Neubig2019). The values of the three metrics are calculated using the sentence generated by the model and a previously annotated reference sentence. For the polarity swap task, as we only have annotated sentences for the test set, during the evaluation part of the training, we use the input as the reference for calculating the metrics.
BLEU (Bilingual Evaluation Understudy Score) is a fast and inexpensive metric widely used in NLP tasks, initially proposed for machine translation. BLEU is widely used in many languages and correlates well with human judgments. Although BLEU is traditionally used for inter-linguistic translation, it was adopted in this study to evaluate the adaptations of Shakespeare’s texts, which consist of an intra-linguistic translation task. In the experiments, BLEU was calculated using the NLTK (Bird Reference Bird2006) package. BLEU is calculated as
 \begin{equation} \begin{split} p_n &= \frac{\# n\textrm{-grams in the candidate found in the reference}}{\# n\textrm{-grams in the candidate}} \\ \text{BP} &= e^{\min (0,1-\frac{r}{c})} \\ \text{BLEU} &= \text{BP} \times \prod _{i=1}^{k}p_n^{w_n} \end{split} \end{equation}
\begin{equation} \begin{split} p_n &= \frac{\# n\textrm{-grams in the candidate found in the reference}}{\# n\textrm{-grams in the candidate}} \\ \text{BP} &= e^{\min (0,1-\frac{r}{c})} \\ \text{BLEU} &= \text{BP} \times \prod _{i=1}^{k}p_n^{w_n} \end{split} \end{equation}
where
 $c$
is the length of the translated candidate sentence,
$c$
is the length of the translated candidate sentence,
 $r$
is the length of the reference sentence,
$r$
is the length of the reference sentence,
 $BP$
is a term that penalizes the difference between the length of the candidate and reference sentences,
$BP$
is a term that penalizes the difference between the length of the candidate and reference sentences,
 $k$
is the maximum n-gram one wants to evaluate, and
$k$
is the maximum n-gram one wants to evaluate, and
 $p_n$
is the precision score for the grams of length
$p_n$
is the precision score for the grams of length
 $n$
. According to the values proposed in Papineni et al. (Reference Papineni, Roukos, Ward and Zhu2002), we adopt
$n$
. According to the values proposed in Papineni et al. (Reference Papineni, Roukos, Ward and Zhu2002), we adopt
 $k=4$
and uniform weights
$k=4$
and uniform weights
 $w_n = 1/N$
.
$w_n = 1/N$
.
Wieting et al. (Reference Wieting, Berg-Kirkpatrick, Gimpel and Neubig2019) introduced a metric called SIM to measure semantic similarity between sentences. SIM aims to overcome the limitations of the BLEU metric and avoid giving partial credit and penalizing semantically correct candidates when they differ lexically from the reference sentence. For that, a coding model
 $g$
that tries to maximize the similarity of pairs of sentences present in a dataset of paraphrases (Wieting and Gimpel Reference Wieting and Gimpel2018) was trained. The
$g$
that tries to maximize the similarity of pairs of sentences present in a dataset of paraphrases (Wieting and Gimpel Reference Wieting and Gimpel2018) was trained. The
 $g$
encoder averages the vector representations of each sentence token to create a vector representation of the sentence. The similarity between a pair of sentences
$g$
encoder averages the vector representations of each sentence token to create a vector representation of the sentence. The similarity between a pair of sentences
 $ < X,\hat{X}>$
is obtained by encoding the two sentences with
$ < X,\hat{X}>$
is obtained by encoding the two sentences with
 $g$
and then calculating the cosine similarity of the two representations:
$g$
and then calculating the cosine similarity of the two representations:
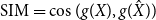 \begin{equation} \begin{split} \textrm{SIM} = \cos (g(X), g(\hat{X})) \end{split} \end{equation}
\begin{equation} \begin{split} \textrm{SIM} = \cos (g(X), g(\hat{X})) \end{split} \end{equation}
BARTScore (Yuan et al. Reference Yuan, Neubig and Liu2021) is a recently proposed metric tailored for generation tasks. It evaluates generated text from different perspectives, for example, informativeness and fluency. Although simple, BARTScore has been shown to correlate better with human judgments in different generation tasks and achieved the best performance on 16 of 22 settings against existing top-scoring metrics. Mathematically, BARTScore is the log probability of one text
 $\textbf{y}$
given another text
$\textbf{y}$
given another text
 $\textbf{x}$
.
$\textbf{x}$
.
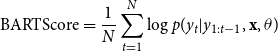 \begin{equation} \begin{split} \text{BARTScore} = \frac{1}{N} \sum _{t=1}^{N} \log p(y_t|y_{1:t-1},\textbf{x},\theta ) \end{split} \end{equation}
\begin{equation} \begin{split} \text{BARTScore} = \frac{1}{N} \sum _{t=1}^{N} \log p(y_t|y_{1:t-1},\textbf{x},\theta ) \end{split} \end{equation}
Regarding attribute control, following previous work (Shen et al. Reference Shen, Lei, Barzilay and Jaakkola2017; Yang et al. Reference Yang, Hu, Dyer, Xing and Berg-Kirkpatrick2018; Luo et al. Reference Luo, Li, Zhou, Yang, Chang, Sun and Sui2019; He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020; Lai et al. Reference Lai, Toral and Nissim2021), we train a neural convolutional classifier (Kim Reference Kim2014) to measure the extent to which the style is controlled. We train one classifier for each task to determine the stylistic domain to which a sentence belongs. The style control metric for each task is the accuracy this classifier gives to the generated sentences. The training set used to train the classifiers is the same one used during our main training. The classifiers have an accuracy of 82.7%, 85.1%, and 97.1% on the validation sets of Shakespeare, GYAFC and YELP, respectively. On the test sets, the values are 81.4%, 86.2%, and 97.0%, respectively.
Finally, as the overall score for model selection and for comparison to previous work (Luo et al. Reference Luo, Li, Zhou, Yang, Chang, Sun and Sui2019; Lai et al. Reference Lai, Toral and Nissim2021), we compute the harmonic mean (HM) of style accuracy and BLEU.
To select our best model, we settled thresholds for the style accuracy, and the model with the highest harmonic mean (HM) was selected to run on the test set. Since it is necessary to provide a greater weight to the content preservation metric, the HM suits well for our case. The threshold is necessary to avoid selecting models with a high degree of input copying, achieving a high harmonic mean even with a shallow style accuracy, and failing to control the desired style. For author imitation, we empirically established 66.6% accuracy, which is a bottom limit for style control, considering each transfer direction. For formality transfer and polarity swap, this limit was set to 70%.
5.1.4 Human evaluation
As the automatic metrics only give us shallow perceptions of the quality of the translated sentences, we compare the transfer quality across state-of-the-art models and ours by a small-scale human study. We conduct a human evaluation on the test set of both the YELP dataset and the GYAFC corpus. We left the Shapespeare domain out since it is more difficult for non-native speakers and non-experts to evaluate. For each dataset, we randomly select 48 samples for the human evaluation (24 for each style attribute). Each sample contains the transformed sentences generated by different models given the same source sentence. Annotators were asked to rate each output on three criteria on a Likert scale from 1 to 5: style control, content preservation, and an overall quality score. The annotators also rate human references for each dataset.
5.1.5 Hyperparameters and training details
During the experiments, some combinations of hyperparameters were evaluated according to the performance of MATTES in the validation set. The term
 $\alpha$
in the loss function of the knowledge distillation component (Equation 11) varied within the values
$\alpha$
in the loss function of the knowledge distillation component (Equation 11) varied within the values
 $\{0.1, 0.5, 0.65\}$
. The knowledge distillation temperature
$\{0.1, 0.5, 0.65\}$
. The knowledge distillation temperature
 $T_{\text{KD}}$
also varied by
$T_{\text{KD}}$
also varied by
 $\{1, 5, 10\}$
. Values for the number of steps of the discriminator
$\{1, 5, 10\}$
. Values for the number of steps of the discriminator
 $n_d$
and the number of steps of the generator
$n_d$
and the number of steps of the generator
 $n_f$
were also experimented. The tuple (
$n_f$
were also experimented. The tuple (
 $n_d$
,
$n_d$
,
 $n_f$
) varied with the values
$n_f$
) varied with the values
 $\{(7.5), (9.5), (10.5)\}$
. The contribution of each component to the MATTES loss function (Equations 10, 11, and 12) also varied (
$\{(7.5), (9.5), (10.5)\}$
. The contribution of each component to the MATTES loss function (Equations 10, 11, and 12) also varied (
 $a_1\mathcal{L}_{\text{self}}(\theta )+a_2\mathcal{L}_{\text{KD}}(\theta )+\mathcal{L}_{\text{adversarial}}(\rho )$
). As Dai et al. (Reference Dai, Liang, Qiu and Huang2019), it was concluded that executing random dropout on the input sentence tokens during the sentence reconstruction step positively impacts the model results. The dropout rate varied in
$a_1\mathcal{L}_{\text{self}}(\theta )+a_2\mathcal{L}_{\text{KD}}(\theta )+\mathcal{L}_{\text{adversarial}}(\rho )$
). As Dai et al. (Reference Dai, Liang, Qiu and Huang2019), it was concluded that executing random dropout on the input sentence tokens during the sentence reconstruction step positively impacts the model results. The dropout rate varied in
 $\{0.2, 0.3, 0.4\}$
.
$\{0.2, 0.3, 0.4\}$
.
We perform all the experiments using the Python programming language with the PyTorch (Paszke et al. Reference Paszke, Gross, Chintala, Chanan, Yang, DeVito, Lin, Desmaison, Antiga and Lerer2017) framework. The ALBERT implementation uses the HuggingFace transformers (Wolf et al. Reference Wolf, Debut, Sanh, Chaumond, Delangue, Moi, Cistac, Rault, Louf, Funtowicz, Davison, Shleifer, von Platen, Ma, Jernite, Plu, Xu, Scao, Gugger, Drame, Lhoest and Rush2020) framework. Before the main MATTES training, for each task performed, we selected the available model albert-large-v2, and fine-tuned two ALBERT models, one for each stylistic domain, using only the traditional MLM task. In this adaptive domain pretraining step, as in Gururangan et al. (Reference Gururangan, Marasovic, Swayamdipta, Lo, Beltagy, Downey and Smith2020), we train each ALBERT model for 100 epochs, using the AdamW with
 $\epsilon$
equal to
$\epsilon$
equal to
 $1\mathrm{e}{-6}$
, linear learning rate with a warm-up, and maximum learning rate of
$1\mathrm{e}{-6}$
, linear learning rate with a warm-up, and maximum learning rate of
 $1\mathrm{e}{-5}$
. ALBERT does not use dropout or regularization during training. Training took place on four NVIDIA P100 GPUs with a training batch of eight examples per GPU. After fine-tuning ALBERT in each stylistic domain, the logitsFootnote
b
were extracted for each token of each sentence in the training set. Following Chen et al. (Reference Chen, Gan, Cheng, Liu and Liu2020), for saving computational resources, only the top-8 logits were considered to be used as labels during the main MATTES training.
$1\mathrm{e}{-5}$
. ALBERT does not use dropout or regularization during training. Training took place on four NVIDIA P100 GPUs with a training batch of eight examples per GPU. After fine-tuning ALBERT in each stylistic domain, the logitsFootnote
b
were extracted for each token of each sentence in the training set. Following Chen et al. (Reference Chen, Gan, Cheng, Liu and Liu2020), for saving computational resources, only the top-8 logits were considered to be used as labels during the main MATTES training.
To take advantage of available generic data, we pre-trained our Seq2seq model on pairs of paraphrase (Hu et al. Reference Hu, Singh, Holzenberger, Post and Van Durme2019) and used the trained model as starting point for the main adversarial training. The training details followed Vaswani et al. (Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). We trained the model for 300,000 steps, using the Adam optimizer (Kingma and Ba Reference Kingma and Ba2015) with
 $\beta _1 = 0.9$
,
$\beta _1 = 0.9$
,
 $\beta _2 = 0.98$
and
$\beta _2 = 0.98$
and
 $\epsilon$
=
$\epsilon$
=
 $1\mathrm{e}{-9}$
. Each training step took about
$1\mathrm{e}{-9}$
. Each training step took about
 $0.12$
seconds, and the whole pre-training was about
$0.12$
seconds, and the whole pre-training was about
 $20$
hours on a single P100 GPU. We apply dropout with a rate of
$20$
hours on a single P100 GPU. We apply dropout with a rate of
 $P_{\text{dropout}}=0.1$
. As in Vaswani et al. (Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017), we varied the learning rate throughout training, increasing the learning rate linearly for the first 4000 steps and decreasing it proportionally to the inverse square root of the step number. From the complete PARABANK 2 (Hu et al. Reference Hu, Singh, Holzenberger, Post and Van Durme2019) containing 19.7M pairs of paraphrases, we filtered out pairs in which at least one of the sentences had less than six words or more than 50 words. We split the remaining pairs into training and validation sets. Our final paraphrase training set reached 11.4M pairs, and the validation set 2.8M.
$P_{\text{dropout}}=0.1$
. As in Vaswani et al. (Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017), we varied the learning rate throughout training, increasing the learning rate linearly for the first 4000 steps and decreasing it proportionally to the inverse square root of the step number. From the complete PARABANK 2 (Hu et al. Reference Hu, Singh, Holzenberger, Post and Van Durme2019) containing 19.7M pairs of paraphrases, we filtered out pairs in which at least one of the sentences had less than six words or more than 50 words. We split the remaining pairs into training and validation sets. Our final paraphrase training set reached 11.4M pairs, and the validation set 2.8M.
All primary training experiments were run on Tesla P100-SXM2 GPUs using the Ubuntu operating system on a machine with an Intel(R) Xeon(R) CPU E5-2698 v4. On average, the Yelp dataset takes 30 hours with a training batch of 192, the GYAFC corpus takes 15 hours with a training batch of 128, while the Shakespeare dataset takes 15 hours with a training batch of 64. This time drops by approximately half when starting from the pretrained Seq2Seq model.
5.2 Results
The results include the values obtained using quantitative metrics, a statistical test, a human evaluation, and ablation studies. We also perform a qualitative analysis.
5.2.1 Quantitative results
Table 2 shows the results using the automatic metrics. In the YELP dataset, the best models displayed in Li et al. (Reference Li, Jia, He and Liang2018) were compared and complemented with Yi et al. (Reference Yi, Liu, Li and Sun2020), He et al. (Reference He, Wang, Neubig and Berg-Kirkpatrick2020), Dai et al. (Reference Dai, Liang, Qiu and Huang2019), and Lai et al. (Reference Lai, Toral and Nissim2021). In the Shakespeare dataset, MATTES results were compared to the results of He et al. (Reference He, Wang, Neubig and Berg-Kirkpatrick2020) and Krishna et al. (Reference Krishna, Wieting and Iyyer2020). In addition, the results were also compared with our implementation of the style transformer (Dai et al. Reference Dai, Liang, Qiu and Huang2019) model in the author imitation task, as the original work did not include this task. This implementation is similar to MATTES but uses the traditional back-translation component in the loss function rather than the knowledge distillation component. In the GYAFC corpus, MATTES results were compared to the results of Luo et al. (Reference Luo, Li, Zhou, Yang, Chang, Sun and Sui2019), Yi et al. (Reference Yi, Liu, Li and Sun2020), and Lai et al. (Reference Lai, Toral and Nissim2021), the state-of-the-art model. We also compared it with our implementation of the style transformer (Dai et al. Reference Dai, Liang, Qiu and Huang2019) model.
Table 2. Results with automatic evaluation metrics. BScore stands for BARTScore, and HM is the harmonic mean of BLEU and accuracy. The best results are in bold.
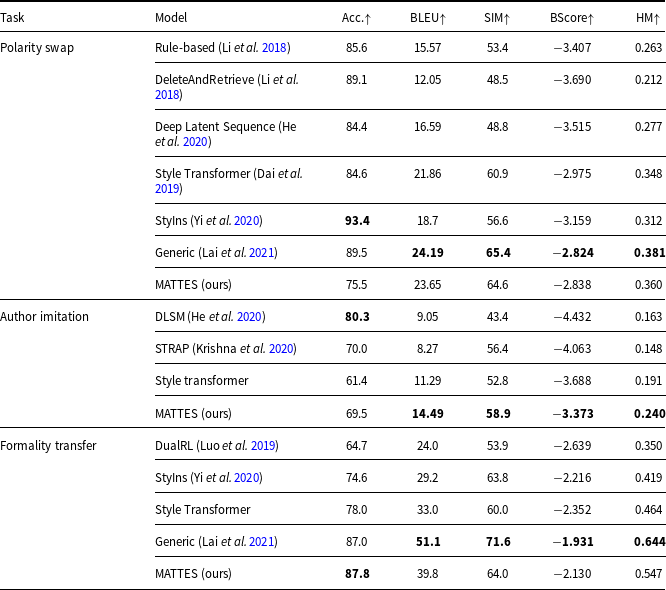
In Shakespeare’s dataset, MATTES surpassed all previous approaches regarding all content preservation metrics. It also achieved the best overall performance (HM) on this task. The Deep Latent Sequence Model (DLSM) (He et al. Reference He, Wang, Neubig and Berg-Kirkpatrick2020) has the best style control metric, however, at the expense of low values in the content preservation metrics. On the other hand, we can increase the style accuracy threshold if we desire more control over the style. In Appendix D, we show models selected using a higher threshold.
In the YELP dataset, MATTES achieved the second-highest results for all the content preservation metrics and the overall score, staying very close to the best model. Nevertheless, the style control metric was the worst among all the compared models.
In the GYAFC corpus, MATTES achieves the highest value for style control. As in YELP, it achieves the second-highest results for all the content preservation metrics and the overall score. As we can see in Section 5.2.3, the style control result is mainly due to the knowledge distillation technique.
By examining the results, we can see that our full model is quite effective in preserving the content of the input while keeping a reasonable style accuracy in all tasks. In the author imitation task and in the formality transfer task, our approach achieved new state-of-the-art results in terms of content preservation and style control, respectively. In Section 5.2.3, we evaluate the impact of our proposed training strategy; specifically, we want to quantify the impact of the Seq2Seq pretraining phase and the knowledge distillation training technique.
Statistical significance analysis
We conducted statistical tests to compare the BARTScore and SIM metrics achieved by MATTES and the other two models that obtained the best content preservation metrics. We left out BLEU since it is a more limited metric that measures lexical matching only. We denote
 $H_0$
as the null hypothesis and
$H_0$
as the null hypothesis and
 $H_1$
as the alternative hypothesis to be tested. The significance level
$H_1$
as the alternative hypothesis to be tested. The significance level
 $\alpha = 0.05$
was adopted, and we assume that the random variables
$\alpha = 0.05$
was adopted, and we assume that the random variables
 $\bar{B}$
and
$\bar{B}$
and
 $\bar{S}$
, which correspond, respectively, to the population mean of BARTScore and SIM, have a normal distribution for each model. The tests were based on the sample means of the two metrics in the test set. Under the null hypothesis, the p-value is the probability of obtaining a statistic equal to or more extreme than that observed in a sample. Thus, when a p-value smaller than the significance level is obtained, this indicates an unlikely event, indicating rejection of
$\bar{S}$
, which correspond, respectively, to the population mean of BARTScore and SIM, have a normal distribution for each model. The tests were based on the sample means of the two metrics in the test set. Under the null hypothesis, the p-value is the probability of obtaining a statistic equal to or more extreme than that observed in a sample. Thus, when a p-value smaller than the significance level is obtained, this indicates an unlikely event, indicating rejection of
 $H_0$
.
$H_0$
.
The results of the statistical tests in Table 3 reinforced the results of Table 2. In the author imitation task, MATTES outperformed the other baseline models on both metrics. In the polarity swap, MATTES outperforms the Style Transformer Model on both metrics. When comparing with the SOTA model (Lai et al. Reference Lai, Toral and Nissim2021), for a confidence interval of
 $95\%$
, it is not possible to affirm the superiority of any model regarding both metrics. In the formality transfer task, Lai et al. (Reference Lai, Toral and Nissim2021) is statistically superior in both metrics, and MATTES confirms the superiority over the style instance model only for the BARTScore metric.
$95\%$
, it is not possible to affirm the superiority of any model regarding both metrics. In the formality transfer task, Lai et al. (Reference Lai, Toral and Nissim2021) is statistically superior in both metrics, and MATTES confirms the superiority over the style instance model only for the BARTScore metric.
Table 3. T-test over the mean population for BARTSore and SIM metric on the test set
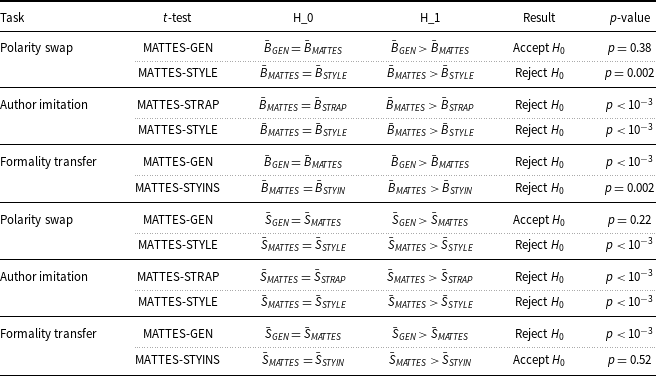
5.2.2 Human evaluation results
Due to the limitations of automatic metrics, we also conduct human evaluations on YELP and GYAFC datasets. Table 4 shows the evaluation of the style transfer accuracy, content preservation, and an overall quality score obtained by MATTES and the compared models. All three aspects are rated with a range of 1–5. The results are in line with our automatic evaluations and add confidence to the efficacy of our proposed techniques in achieving style transfer across multiple dimensions. Our scores are around the state-of-the-art values regarding both style control and content preservation in the formality transfer and polarity swap tasks, respectively. Additionally, it is worth mentioning the high scores achieved by the baseline Lai et al. (Reference Lai, Toral and Nissim2021), mainly for the content preservation metric, in some cases even surpassing the scores reached by the references which are sentences created by humans.
Table 4. Results from the human evaluation on Yelp and GYAFC datasets. The best results are in bold.
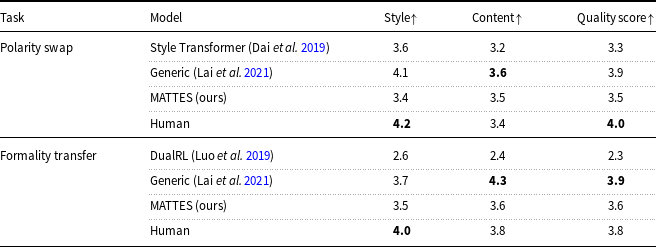
5.2.3 Ablation studies
In this section, we measure the individual impact of the pretraining phase and the model training components. We also show how the content preservation metrics correlate between them.
Paraphrase pre-training and model components
To confirm that TST models can benefit from our proposals, we conducted an ablation study on all datasets by eliminating or modifying a certain component (e.g., objective functions or pre-training phase). We tested the following variations: (1) FULL MODEL: our proposed model with all the components described in Section 4; (2) NO KD: the model without the knowledge distillation component (
 $\alpha =0$
); (3) NO PARA: the model trained from scratch, without pre-training the Seq2Seq model on paraphrase data; (4) NO PARA KD: the model trained from scratch and without knowledge distillation; (5) NO ADV: the model trained without the adversarial loss component; and (6) NO ADV KD: the model trained without the adversarial loss component and without the knowledge distillation (
$\alpha =0$
); (3) NO PARA: the model trained from scratch, without pre-training the Seq2Seq model on paraphrase data; (4) NO PARA KD: the model trained from scratch and without knowledge distillation; (5) NO ADV: the model trained without the adversarial loss component; and (6) NO ADV KD: the model trained without the adversarial loss component and without the knowledge distillation (
 $\alpha =0$
). Table 5 exhibits the results.
$\alpha =0$
). Table 5 exhibits the results.
Table 5. Evaluation results for the ablation study. Acc. stands for accuracy, BScore for BARTScore, and HM for the harmonic mean between BLEU and accuracy
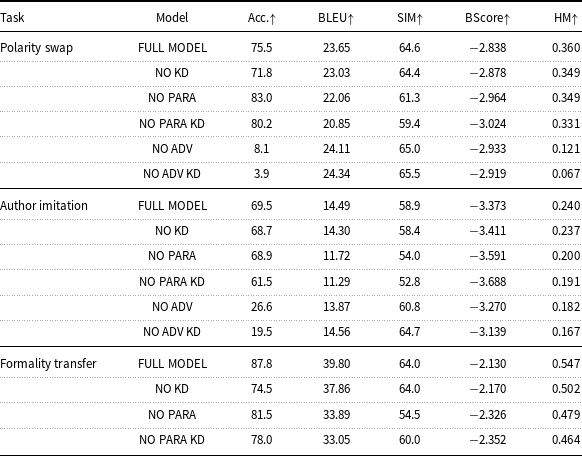
The results indicate that the pretraining strategy significantly impacts content preservation. On all tasks, pretraining considerably increased the content preservation metric. In the Shakespeare dataset and in the GYAFC corpus, the style accuracy also improved with pre-training, which makes sense since the diversity of the paraphrase model should lead to a lower degree of input copying. On the other hand, in the YELP dataset, the pretraining approach harmed the model style control. This also makes sense since the polarity swap task is not a rewriting task, so having a paraphrase of a sentence does not help. For that, something that changes the meaning is necessary. This observation indicates that these tasks should not be indiscriminately tackled as TST tasks since there is a clear need to change the meaning of the polarity swap task.
Regarding the isolated impact of our proposed knowledge distillation technique, all the model variations from Table 5 trained with the distillation achieved higher accuracy and HM when compared with the variations trained without. Although adversarial training is the most crucial component for style control, the distillation also positively affects style accuracy. Comparing the two model variations without adversarial training (NO˙ADV and NO˙ADV˙KD), we realize distillation increases the accuracy, yet not so impressively as the adversarial component.
Since we decided to use the harmonic mean (HM) of the BLUE with the style accuracy for model selection, to interpret the impact of the pre-training phase better, in Figure 3 located in Appendix C, we plot these three metrics achieved by our FULL MODEL and its variation NO PARA along the training process on the Yelp validation set. From the graphics, we can realize that the training dynamics are different. When training the model from scratch, the content preservation metric starts almost from zero until reaching its limit. In contrast, the pretrained model starts at its maximum but with low accuracy. Once its highest value is reached, the HM tends downward after many training steps. At last, we notice the FULL MODEL reaches its highest HM faster than the model trained from scratch, showing another benefit from pretraining.
The hyperparameters of the models in Table 5 are listed in Appendix A.
Metric analysis
Since evaluating generated texts is an open field and a challenging task, we adopted three metrics for content preservation. To glean further insights about these choices, we calculate the Pearson Correlation between evaluation metrics for content preservation over N systems (Table 6).
Table 6. Pearson correlation between content preservation metrics over N systems
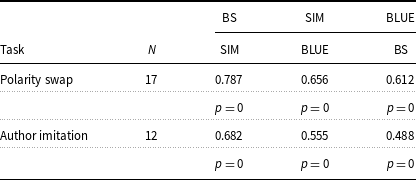
The results show that while SIM and BARTScore highly correlated with each other, BLEU does so to a lesser extent, suggesting this might be a less robust measure to assess the goodness of TST tasks. Since transfer style often involves lexical changes, n-gram-based matching metrics such as BLEU usually fail to recognize information beyond the lexical level. This result strengthens the necessity for adopting metrics concerned with capturing the overall semantics of a sentence, like SIM and BARTScore.
5.2.4 Qualitative analyses
At last, we carry out some qualitative analyses: (1) compare samples generated by MATTES and DLSM and (2) compare our model and training approach with the state-of-art method in the Yelp dataset (Lai et al. Reference Lai, Toral and Nissim2021).
MATTES versus deep latent sequence model
We examine the output from our model and the Deep Latent Sequence model for the author imitation task. We picked this task because the reference outputs for the test set are provided. From the qualitative analysis, we observed that both models can generate good translations, but MATTES tends to preserve the content better. On the other hand, Deep Latent Sequence tends to create too short sentences when the input sentence is long, losing content. This observation concurs with the fact that MATTES’s content preservation metric is the highest. The attention mechanisms might have helped in handling long sentences. Besides, the sentences generated by the Deep Latent Sequence model have lower perplexity than the test set, indicating short or trivial sentences. Table 7 exhibits examples of the generated sentences for long inputs.
Table 7. Transferred sentences for the author imitation task

Appendix B shows other examples of transferred sentences by MATTES, DLSM, and Style Transformer in the sentiment transfer task.
MATTES versus generic resources model
The state-of-the-art (SOTA) model in the polarity swap (Lai et al. Reference Lai, Toral and Nissim2021), which also leverages generic resources for pretraining, adopts the same Transformer architecture as MATTES. The primary difference lies in MATTES additional style embedding layer and the depth of both networks. While MATTES has 23 M parameters, the SOTA model starts its training from an already pretrained BART model (Lewis et al. Reference Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov and Zettlemoyer2020) with 139 M parameters. Its impressive results were thanks to further pretraining using synthetic pairs of sentences with opposite polarities.
Analyzing MATTES metrics achieved in the YELP dataset and comparing them with Lai et al. (Reference Lai, Toral and Nissim2021), we realize that adopting a pretraining phase using generic paraphrase data made all the content preservation metrics of both models very similar. Nevertheless, in the case of MATTES, this benefit came at the expense of style accuracy reduction, damage that did not occur in the author imitation task. These facts strengthen pretraining as a great skill to increase content preservation and that both tasks should not be treated and approached equally as style transfer tasks. As polarity swap is not a rewriting task, the pretrained paraphrase system gets in the way of the style control, putting all the effort to change the style into the adversarial mechanisms.
5.3 Limitations and final remarks
Although theoretically attractive, adopting the proposed components and the training schema has some drawbacks. Adversarial training is challenging due to its instability and likely divergence after some epochs. The knowledge distillation strategy requires using a pretrained MLM to generate the soft targets and adds two more parameters for tuning during training. Also, although beneficial, pretraining the Seq2seq model increases the overall running time. At last, when adopting the pretrained model strategy, during inference, the model first converts the input to the paraphrase style and then to the target style, finishing the translation process. The models trained from scratch, as they do not consider the paraphrase style, convert directly to the target style.
To answer the research questions enunciated in Section 1, in this section, we presented an experimental evaluation of the proposed model and compared it to other state-of-the-art models. We also conducted an ablation study with two main contributions, namely, the pretrained Seq2Seq and the knowledge distillation component, to observe their individual impact on the results. Following the experimental results, this section showed qualitative analyses and MATTES’s comparisons with other works related to the unsupervised TST task.
6. Conclusions
This manuscript proposed a new method based on machine learning to perform the unsupervised textual style transfer task, where only the sentence and its respective textual style are available for training. Interpreting a text and converting it to the desired style is a fundamental skill for communication between people. Equipping machines with these skills is necessary to make them part of the communication process.
Given how difficult it is to manually create annotated TST datasets with parallel texts transformed from one style to another, we adopted an unsupervised approach in this manuscript. The proposed method, MATTES, as far as we know, is the first to use the bidirectional representations produced by a MLM as labels to support the training of a generator neural network in the TST task.
The overall architecture of MATTES was inspired by a previous method, the Style Transformer but significantly changing the training procedure. In addition to the pretraining phase of the Seq2Seq model, during the main training, MATTES adopts as labels the probability distribution provided by a MLM for each token of the input sentence as part of its loss function. The experimental results indicated that MATTES reaches the state of the art in the author imitation task, considering both content preservation and an overall score for style transfer. In the formality transfer task, although we do not reach the best model regarding content preservation, our proposed techniques lead to significant improvements in both content preservation and style control. In the polarity swap task, MATTES content preservation metrics were close to the SOTA model, but the style measure was not impressive. We believe the polarity swap did not benefit as much as the other tasks from the pretraining because the former is a task that needs to change the meaning to accomplish its goal and cannot be considered a rewriting task. On the other hand, the knowledge distillation technique is task agnostic and can be suitable in many situations. The less information you have to build a proper probability distribution to generate texts, the more helpful the distillation might be.
Future work includes adopting MATTES in the challenging task of text simplification Al-Thanyyan and Azmi (Reference Al-Thanyyan and Azmi2021). In addition, we intend to add knowledge distillation to other existing models where the distillation may fit to provide more evidence that it improves text generation in the unsupervised textual style transfer. Knowledge distillation can also be added to the sentence reconstruction component of the generator network. Another promising idea, inspired by machine translation, is to optimize directly a differentiable metric during training that takes into account both style control and content preservation. The adoption of a paraphrase style enables the model to handle the multiattribute transfer, which is an exciting direction to follow. Finally, we want to train MATTES in other languages, such as Brazilian Portuguese.
To sum up, we reinforce the need for a better evaluation of text generation methods in natural language. With the increasing presence of machines as parts of the communication process, it is expected that this subarea of NLP continues to gain prominence in the academic and industrial world. The advance of machine learning algorithms that work or are compatible with the TST task enables the creation of models capable of smoothly controlling the text attributes.
Acknowledgments
This research was partially financed by CNPq (National Council for Scientific and Technological Development) under grant 311275/2020-6 and FAPERJ—FundaÇão Carlos Chagas Filho de Amparo à Pesquisa do Estado do Rio de Janeiro, process SEI-260003/000614/2023 and E-26/202.914/2019.
Competing interests
The authors declare that they have no competing or conflict of interest.
Appendix A. Best performance models
Table 8. Hyperparameters used in training. For sentiment transfer
 $0$
means negative and
$0$
means negative and
 $1$
positive. For author imitation
$1$
positive. For author imitation
 $0$
means shakespearean and
$0$
means shakespearean and
 $1$
modern English
$1$
modern English
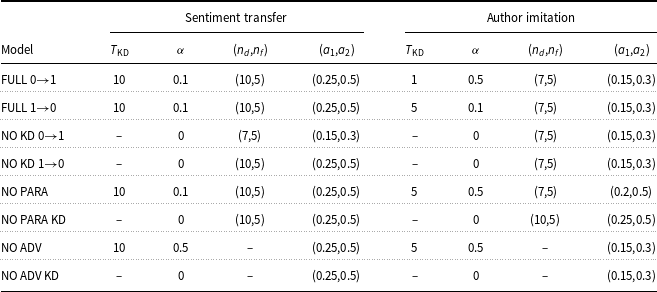
In order to make the experiments conducted in this manuscript reproducible, in the Tables 8 and 9, we list the hyperparameters used in the training of the models of Table 5. The learning rate, the maximum sentence size, and the word dropout were kept untouched throughout the experiments. For the sentiment transfer task, these values are
 $0.0001$
,
$0.0001$
,
 $32$
, and
$32$
, and
 $0.2$
, respectively. For the author imitation task, the values are
$0.2$
, respectively. For the author imitation task, the values are
 $0.0001$
,
$0.0001$
,
 $64$
, and
$64$
, and
 $0.25$
, respectively. And for the formality transfer task, the values are
$0.25$
, respectively. And for the formality transfer task, the values are
 $0.0001$
,
$0.0001$
,
 $32$
, and
$32$
, and
 $0.25$
, respectively.
$0.25$
, respectively.
Table 9. Hyperparameters for training. For formality transfer
 $0$
means informal and
$0$
means informal and
 $1$
formal
$1$
formal
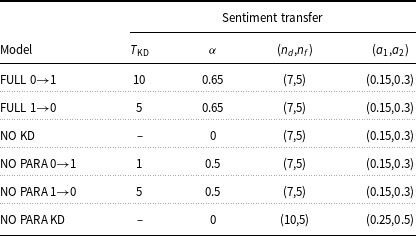
Appendix B. Examples of sentences collected from the experimens conducted on the sentiment transfer task
Table 10 brings some transferred sentences collected from MATTES (FULL MODEL), DLSM, and Style Transformer.
Table 10. Examples of transferred sentences in the sentiment transfer task
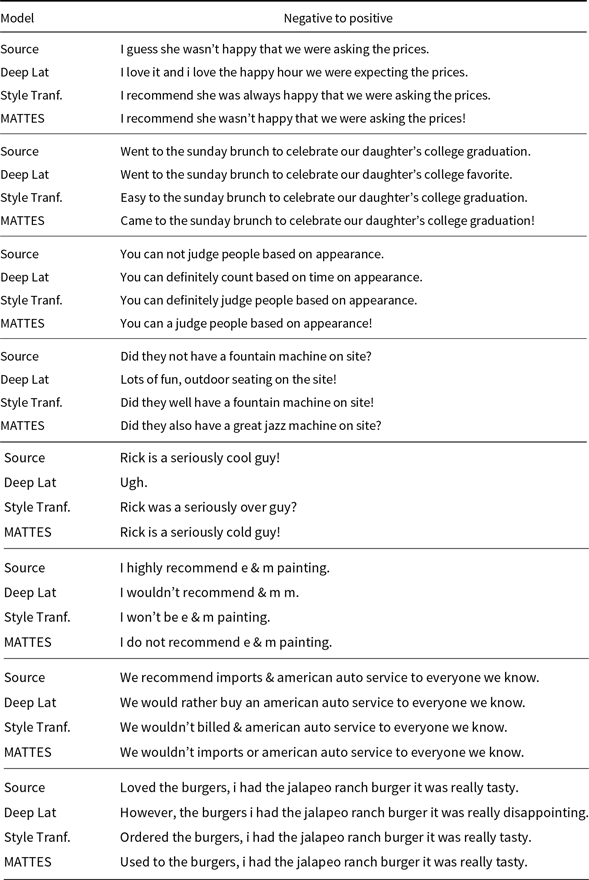
Appendix C. Evolution of metrics
Figure 3 shows the style accuracy, self-bleu and harmonic mean (HM) achieved throughout training by our FULL MODEL and its variation without the pre-training strategy (NO PARA), on the Yelp validation set.
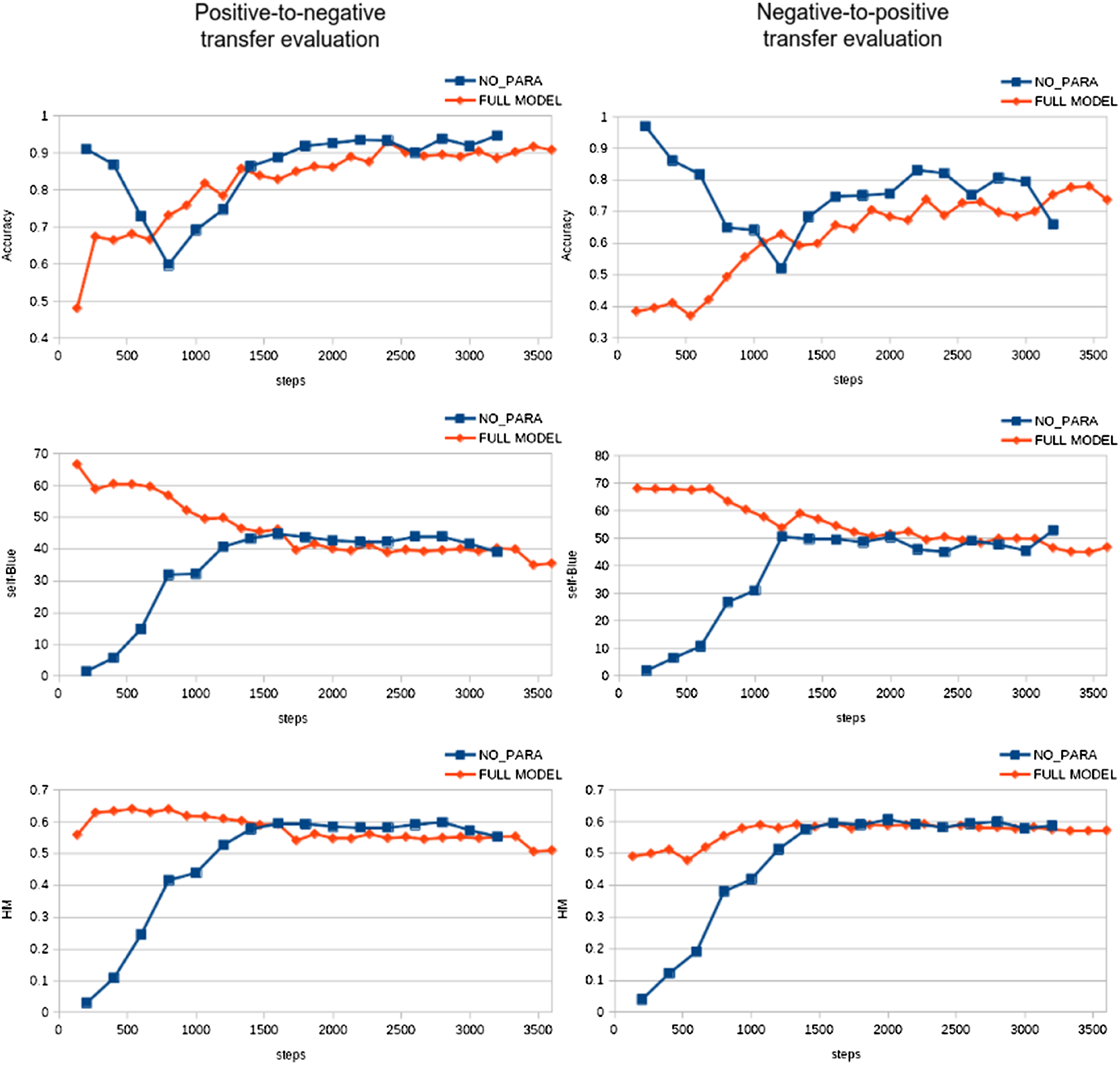
Figure 3. Evaluation metrics, for both transfer directions, during training for our FULL MODEL and its variation NO PARA on the Yelp dataset
Appendix D. Trade-off: Bleu versus Accuracy
Table 11 shows models selected using a higher threshold for the style accuracy. As shown, the improvement comes at the expense of reducing the content preservation.
Table 11. Metrics form model variations trained from scratch. The best results are in bold.
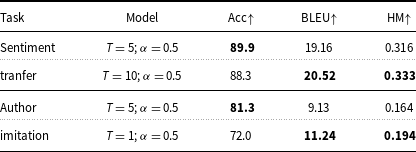


























 Open access
Open access