Refine listing
Actions for selected content:
Contents
Research Article
A Generalisation of Entity and Referential Integrityin Relational Databases
-
- Published online by Cambridge University Press:
- 15 April 2002, pp. 113-127
-
- Article
- Export citation
-
Entity and referential integrity are the most fundamental constraintsthat any relational database should satisfy.We re-examine these fundamental constraints in thecontext of incomplete relations, which may have null values of the types"value exists but is unknown" and "value does not exist" .We argue that in practice the restrictions that these constraints impose on the occurrences of null values in relations are too strict.We justify a generalisation of the said constraints wherein we use key families,which are collections of attribute sets of a relation schema, rather than keys,and foreign key families which are collections of pairs of attribute setsof two relation schemas, rather than foreign keys.Intuitively, a key family is satisfied in an incomplete relation if each one of its tuples is uniquely identifiableon the union of the attribute sets of the key family,in all possible worlds of the incomplete relation,and, in addition, is distinguishable from all the other tuples in the incomplete relation by its nonnull values on some element in the key family. Our proposal can be viewed as an extension of Thalheim's key set,which only deals with null values of type "value exists but is unknown" . The intuition behind the satisfaction of a foreign key family in an incomplete database is that each pair $(F_i, K_i)$
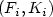 of attribute sets in the foreign key family takes the foreign key attribute values over F i of a tuplein one incomplete relation referencing the key attribute values over K i of a tuple in another incomplete relation.Such referencing is defined only in the case when the foreign key attribute values do not have any null values of the type "value does not exist" ;we insist that the referencing be defined for at least one such pair.We also investigate some combinatorial properties of key families, and show that they are comparable to the standard combinatorial properties of keys.
of attribute sets in the foreign key family takes the foreign key attribute values over F i of a tuplein one incomplete relation referencing the key attribute values over K i of a tuple in another incomplete relation.Such referencing is defined only in the case when the foreign key attribute values do not have any null values of the type "value does not exist" ;we insist that the referencing be defined for at least one such pair.We also investigate some combinatorial properties of key families, and show that they are comparable to the standard combinatorial properties of keys.
PAC Learning under Helpful Distributions
-
- Published online by Cambridge University Press:
- 15 April 2002, pp. 129-148
-
- Article
- Export citation
Restricted Nondeterministic Read-Once Branching Programs and an Exponential Lower Bound for Integer Multiplication
-
- Published online by Cambridge University Press:
- 15 April 2002, pp. 149-162
-
- Article
- Export citation
On the Stack-Size of General Tries
-
- Published online by Cambridge University Press:
- 15 April 2002, pp. 163-185
-
- Article
- Export citation
On the number of iterations required by Von Neumann addition
-
- Published online by Cambridge University Press:
- 15 April 2002, pp. 187-206
-
- Article
- Export citation