



1. Introduction
A well-studied class of random trees is random recursive trees, whereby a sequence of trees
 $T_0, T_1, T_2, \ldots$
is grown by attaching a new child to a vertex chosen uniformly at random to construct the successor. In this work, we generalize the model by constructing a sequence
$T_0, T_1, T_2, \ldots$
is grown by attaching a new child to a vertex chosen uniformly at random to construct the successor. In this work, we generalize the model by constructing a sequence
 $\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
of metric spaces at random. At each step n in the growth process, a point called a latch is chosen at random according to a probability measure on the space
$\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
of metric spaces at random. At each step n in the growth process, a point called a latch is chosen at random according to a probability measure on the space
 $\boldsymbol{G}_{n-1}$
. A new randomly chosen metric space
$\boldsymbol{G}_{n-1}$
. A new randomly chosen metric space
 $\boldsymbol{B}_n$
called a block, equipped with a probability measure, is attached to the latch via a labelled point in
$\boldsymbol{B}_n$
called a block, equipped with a probability measure, is attached to the latch via a labelled point in
 $\boldsymbol{B}_n$
, thereby creating a new metric space
$\boldsymbol{B}_n$
, thereby creating a new metric space
 $\boldsymbol{G}_n$
with a new probability measure defined as a weighted sum of the probability measures on
$\boldsymbol{G}_n$
with a new probability measure defined as a weighted sum of the probability measures on
 $\boldsymbol{G}_{n-1}$
and
$\boldsymbol{G}_{n-1}$
and
 $\boldsymbol{B}_n$
. Since the growth process generalizes the growth process of random recursive trees, we call
$\boldsymbol{B}_n$
. Since the growth process generalizes the growth process of random recursive trees, we call
 $\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
a sequence of random recursive metric spaces. These random recursive metric spaces, defined more precisely below, resemble models of random metric spaces introduced in [Reference Sénizergues24], though in contrast to the present work, the blocks in [Reference Sénizergues24] are renormalized by a constant that vanishes with n. If each block consists of two vertices joined by an edge, and the attachment of the block is done by fusing one of the vertices of the block with the latch, and the probability measure on the space is uniform on all vertices, then we construct random recursive trees as discussed above.
$\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
a sequence of random recursive metric spaces. These random recursive metric spaces, defined more precisely below, resemble models of random metric spaces introduced in [Reference Sénizergues24], though in contrast to the present work, the blocks in [Reference Sénizergues24] are renormalized by a constant that vanishes with n. If each block consists of two vertices joined by an edge, and the attachment of the block is done by fusing one of the vertices of the block with the latch, and the probability measure on the space is uniform on all vertices, then we construct random recursive trees as discussed above.
Several previously studied generalizations of random recursive trees are encompassed in our model as well. These include, for example, preferential attachment trees. Similar to random recursive trees, the growth process is described by attaching an edge at each step by fusing one vertex of the edge to a vertex v chosen at random, but in this case the choice of v is made proportional to the outdegree of v. Another generalization of random recursive trees is the weighted random recursive tree. In this context, every time a new vertex appears in the tree it is assigned a random weight, and the choice of the new parent at each step is made proportional to the weight of the vertex. If, instead of attaching a single edge at each step, an entire new graph is attached, the resulting model is a hooking network. In all of these examples, the insertion depth, that is, the distance to the root from the vertex chosen at random in each step in the growth process, has been shown to follow a normal limit law once scaled by
 $\sqrt{\ln n}$
(see, for example, [Reference Desmarais and Mahmoud7, Reference Devroye8, Reference Eslava11, Reference Lodewijks16, Reference Mahmoud19, Reference Mahmoud20, Reference Mailler and Bravo22, Reference Sénizergues25], and many more). The main result of this work is Theorem 1, where we prove a law of large numbers and a central limit theorem for the insertion depth in random recursive metric spaces.
$\sqrt{\ln n}$
(see, for example, [Reference Desmarais and Mahmoud7, Reference Devroye8, Reference Eslava11, Reference Lodewijks16, Reference Mahmoud19, Reference Mahmoud20, Reference Mailler and Bravo22, Reference Sénizergues25], and many more). The main result of this work is Theorem 1, where we prove a law of large numbers and a central limit theorem for the insertion depth in random recursive metric spaces.
In Sections 1.1 and 1.2, the description of the model introduced above is made more precise. The main result of this work (Theorem 1) is stated in Section 1.3 along with a brief outline of the proof method. Examples of our model, including random recursive trees, preferential attachment trees, weighted random recursive trees, hooking networks, and constructions from line segments, and how Theorem 1 applies, are included in Section 2. The proof of Theorem 1 is contained in Section 3.
1.1. Weighted hooked metric probability spaces
We define a weighted hooked (complete separable) metric probability space to be a five-tuple (b, d, h, p, w) in the following way: (b,d) is a complete and separable metric space and h is a point identified in b called a hook, p is a Borel probability measure on b, and w is a real number called a weight. We wish to define a probability space of weighted hooked metric probability spaces. We start with the space
 $\mathcal{X}$
of equivalence classes under isomorphism (bijective isometry) of (complete separable) metric measure spaces with full support (the support of the measure is the whole space). Gromov proved [Reference Gromov12] that
$\mathcal{X}$
of equivalence classes under isomorphism (bijective isometry) of (complete separable) metric measure spaces with full support (the support of the measure is the whole space). Gromov proved [Reference Gromov12] that
 $\mathcal{X}$
along with the Gromov–Prohorov metric
$\mathcal{X}$
along with the Gromov–Prohorov metric
 $d_\mathrm{GP}$
is a complete separable metric space. We extend the Gromov–Prohorov metric by first defining the hooked (or rooted) Gromov (pseudo)distance
$d_\mathrm{GP}$
is a complete separable metric space. We extend the Gromov–Prohorov metric by first defining the hooked (or rooted) Gromov (pseudo)distance
 $d_\mathrm{GP}^\bullet$
on the space of hooked metric measure spaces by
$d_\mathrm{GP}^\bullet$
on the space of hooked metric measure spaces by
 \begin{multline*} d_\mathrm{GP}^\bullet((b_1, h_1, d_1, p_1), (b_2, h_2, d_2, p_2)) \\ \,:\!=\, \inf_{E,\phi_1,\phi_2}\max((d_{P}(\phi_{1,\#}(p_1),\phi_{2,\#}(p_2)), d_E(\phi_1(h_1),\phi_2(h_2))),\end{multline*}
\begin{multline*} d_\mathrm{GP}^\bullet((b_1, h_1, d_1, p_1), (b_2, h_2, d_2, p_2)) \\ \,:\!=\, \inf_{E,\phi_1,\phi_2}\max((d_{P}(\phi_{1,\#}(p_1),\phi_{2,\#}(p_2)), d_E(\phi_1(h_1),\phi_2(h_2))),\end{multline*}
where the infimum is taken over all complete separable metric spaces
 $(E, d_E)$
such that there exist isometric embeddings
$(E, d_E)$
such that there exist isometric embeddings
 $\phi_1\colon b_1 \rightarrow E$
and
$\phi_1\colon b_1 \rightarrow E$
and
 $\phi_2 \colon b_2 \rightarrow E$
from the complete separable metric spaces
$\phi_2 \colon b_2 \rightarrow E$
from the complete separable metric spaces
 $(b_1, d_1)$
and
$(b_1, d_1)$
and
 $(b_2, d_2)$
to
$(b_2, d_2)$
to
 $(E, d_E)$
. The points
$(E, d_E)$
. The points
 $h_1$
and
$h_1$
and
 $h_2$
are labelled points (hooks) in
$h_2$
are labelled points (hooks) in
 $b_1$
and
$b_1$
and
 $b_2$
respectively. The measures
$b_2$
respectively. The measures
 $\phi_{1,\#}(p_1)$
and
$\phi_{1,\#}(p_1)$
and
 $\phi_{2,\#}(p_2)$
on E are the push-forward measures of
$\phi_{2,\#}(p_2)$
on E are the push-forward measures of
 $p_1$
and
$p_1$
and
 $p_2$
respectively, while
$p_2$
respectively, while
 $d_P$
is the Prohorov metric on the measures on E. Let
$d_P$
is the Prohorov metric on the measures on E. Let
 $\mathcal{X}^\bullet$
be the space of equivalence classes under hook-preserving isomorphisms of hooked metric measure spaces with full support, that is,
$\mathcal{X}^\bullet$
be the space of equivalence classes under hook-preserving isomorphisms of hooked metric measure spaces with full support, that is,
 $(b_1, d_1, h_1, p_1)$
and
$(b_1, d_1, h_1, p_1)$
and
 $(b_2, d_2, h_2, p_2)$
belong to the same equivalence class if there exists a bijective isometry
$(b_2, d_2, h_2, p_2)$
belong to the same equivalence class if there exists a bijective isometry
 $\phi\colon b_1 \rightarrow b_2$
such that
$\phi\colon b_1 \rightarrow b_2$
such that
 $\phi(h_1) = h_2$
. By using similar arguments as for the Gromov–Hausdorff–Prohorov metric for rooted compact metric measure spaces in [Reference Abraham, Delmas and Hoscheit1], we can show that
$\phi(h_1) = h_2$
. By using similar arguments as for the Gromov–Hausdorff–Prohorov metric for rooted compact metric measure spaces in [Reference Abraham, Delmas and Hoscheit1], we can show that
 $(\mathcal{X}^\bullet, d_\mathrm{GP}^\bullet)$
is a complete and separable metric space (the only difference in the argument is that we can omit the ‘Hausdorff’ part). We use the word ‘hook’ in this work, but it serves the same purpose as the ‘root’ in [Reference Abraham, Delmas and Hoscheit1]. Finally, since
$(\mathcal{X}^\bullet, d_\mathrm{GP}^\bullet)$
is a complete and separable metric space (the only difference in the argument is that we can omit the ‘Hausdorff’ part). We use the word ‘hook’ in this work, but it serves the same purpose as the ‘root’ in [Reference Abraham, Delmas and Hoscheit1]. Finally, since
 $\mathcal{X}^\bullet$
and
$\mathcal{X}^\bullet$
and
 $\mathbb{R}$
are Polish spaces, so is
$\mathbb{R}$
are Polish spaces, so is
 $\mathcal{X}^\bullet \times \mathbb{R}$
, and so we can define a Borel probability measure on this space. We may now define a random block
$\mathcal{X}^\bullet \times \mathbb{R}$
, and so we can define a Borel probability measure on this space. We may now define a random block
 $\boldsymbol{B} = (B, D^{\prime}, H^{\prime}, P^{\prime}, W)$
as a random element of
$\boldsymbol{B} = (B, D^{\prime}, H^{\prime}, P^{\prime}, W)$
as a random element of
 $\mathcal{X}^\bullet \times \mathbb{R}$
(according to some Borel probability measure).
$\mathcal{X}^\bullet \times \mathbb{R}$
(according to some Borel probability measure).
1.2. Definition of random recursive metric spaces
Let
 $\boldsymbol{B}$
be a random block as defined in the previous section such that
$\boldsymbol{B}$
be a random block as defined in the previous section such that
 $W \geq 0$
and
$W \geq 0$
and
 $\mathbb{P}(W=0) < 1$
. For
$\mathbb{P}(W=0) < 1$
. For
 $n \geq 1$
, let
$n \geq 1$
, let
 $\boldsymbol{B}_n = (B_n, D^{\prime}_n, H^{\prime}_n, P^{\prime}_n, W_n)$
be independent and identically distributed copies of
$\boldsymbol{B}_n = (B_n, D^{\prime}_n, H^{\prime}_n, P^{\prime}_n, W_n)$
be independent and identically distributed copies of
 $\boldsymbol{B}$
, and let
$\boldsymbol{B}$
, and let
 $\boldsymbol{B}_0 = (B_0, D^{\prime}_0, H, P^{\prime}_0, W_0)$
be a random block which may or may not have the same distribution as
$\boldsymbol{B}_0 = (B_0, D^{\prime}_0, H, P^{\prime}_0, W_0)$
be a random block which may or may not have the same distribution as
 $\boldsymbol{B}$
. We add the condition that
$\boldsymbol{B}$
. We add the condition that
 $W_0 > 0$
; notice that
$W_0 > 0$
; notice that
 $W_0$
might not have the same distribution as W.
$W_0$
might not have the same distribution as W.
Formally, random recursive metric spaces
 $\boldsymbol{G}_n = (G_n, D_n, H, P_n, S_n)$
are random elements from
$\boldsymbol{G}_n = (G_n, D_n, H, P_n, S_n)$
are random elements from
 $\mathcal{X}^\bullet \times \mathbb{R}$
constructed recursively from the blocks
$\mathcal{X}^\bullet \times \mathbb{R}$
constructed recursively from the blocks
 $\boldsymbol{B}_n$
. We start by setting
$\boldsymbol{B}_n$
. We start by setting
 $\boldsymbol{G}_0 = (G_0, D_0, H, P_0, S_0) = \boldsymbol{B}_0$
. The identified point H serves as the master hook of all following random recursive metric spaces. At each step
$\boldsymbol{G}_0 = (G_0, D_0, H, P_0, S_0) = \boldsymbol{B}_0$
. The identified point H serves as the master hook of all following random recursive metric spaces. At each step
 $n \geq 0$
, we grow
$n \geq 0$
, we grow
 $\boldsymbol{G}_{n+1}$
from
$\boldsymbol{G}_{n+1}$
from
 $\boldsymbol{G}_n$
by randomly choosing a point
$\boldsymbol{G}_n$
by randomly choosing a point
 $v_{n+1} \in G_n$
called a latch according to the probability
$v_{n+1} \in G_n$
called a latch according to the probability
 $P_n$
. Next, we identify together the latch
$P_n$
. Next, we identify together the latch
 $v_{n+1}$
with the hook
$v_{n+1}$
with the hook
 $H^{\prime}_{n+1}$
to form
$H^{\prime}_{n+1}$
to form
 $G_{n+1}$
. We let
$G_{n+1}$
. We let
 $D_{n+1}$
be the concatenation of the metrics
$D_{n+1}$
be the concatenation of the metrics
 $D_n$
and
$D_n$
and
 $D^{\prime}_{n+1}$
in the canonical way and set
$D^{\prime}_{n+1}$
in the canonical way and set
 $S_{n+1} = S_n + W_{n+1}$
. Define
$S_{n+1} = S_n + W_{n+1}$
. Define
 $P_{n+1}$
to be the weighted sum of the probabilities
$P_{n+1}$
to be the weighted sum of the probabilities
 $P_n$
and
$P_n$
and
 $P^{\prime}_{n+1}$
; more precisely, extend the probability measures to all of
$P^{\prime}_{n+1}$
; more precisely, extend the probability measures to all of
 $G_{n+1}$
such that, for any event
$G_{n+1}$
such that, for any event
 $A \subseteq G_{n+1}$
, the extensions
$A \subseteq G_{n+1}$
, the extensions
 $\widehat{P_n}$
and
$\widehat{P_n}$
and
 $\widehat{P^{\prime}_{n+1}}$
satisfy
$\widehat{P^{\prime}_{n+1}}$
satisfy
 $\widehat{P_n}(A) = P_n(A\cap G_{n})$
and
$\widehat{P_n}(A) = P_n(A\cap G_{n})$
and
 $\widehat{P^{\prime}_{n+1}}(A) = P^{\prime}_{n+1}(A\cap B_{n+1})$
, and define
$\widehat{P^{\prime}_{n+1}}(A) = P^{\prime}_{n+1}(A\cap B_{n+1})$
, and define
 \begin{equation} P_{n+1} = \frac{S_n}{S_{n+1}}\widehat{P_n} + \frac{W_{n+1}}{S_{n+1}}\widehat{P^{\prime}_{n+1}}.\end{equation}
\begin{equation} P_{n+1} = \frac{S_n}{S_{n+1}}\widehat{P_n} + \frac{W_{n+1}}{S_{n+1}}\widehat{P^{\prime}_{n+1}}.\end{equation}
Set
 $\boldsymbol{G}_{n+1} = (G_{n+1}, D_{n+1}, H, P_{n+1}, S_{n+1})$
.
$\boldsymbol{G}_{n+1} = (G_{n+1}, D_{n+1}, H, P_{n+1}, S_{n+1})$
.
By the recursive nature of (1), the probability measure
 $P_n$
is a weighted sum of extensions of the probability measures
$P_n$
is a weighted sum of extensions of the probability measures
 $P^{\prime}_k$
of the constituent blocks
$P^{\prime}_k$
of the constituent blocks
 $\boldsymbol{B}_k$
that make up
$\boldsymbol{B}_k$
that make up
 $\boldsymbol{G}_n$
. In a slight abuse of notation, we will write
$\boldsymbol{G}_n$
. In a slight abuse of notation, we will write
 \begin{equation*} P_n = \sum_{k=0}^n \frac{W_k}{S_n} P^{\prime}_k.\end{equation*}
\begin{equation*} P_n = \sum_{k=0}^n \frac{W_k}{S_n} P^{\prime}_k.\end{equation*}
Models with constructions similar to random recursive metric spaces have been studied. These include models where the blocks consist of finite line segments [Reference Amini, Devroye, Griffiths and Olver2, Reference Borovkov and Vatutin3, Reference Curien and Haas5, Reference Haas13], and constructions of iterative gluing of metric spaces introduced by Sénizergues [Reference Sénizergues24, Reference Sénizergues26]. In fact, the notation for random recursive metric spaces presented in this paper is heavily inspired by the notation introduced in [Reference Sénizergues24]. In most of these models, the blocks are compact and scaled by a factor of roughly
 $n^{-\alpha}$
for some
$n^{-\alpha}$
for some
 $\alpha >0$
as they are attached. Under certain assumptions, it is shown that the probability measures
$\alpha >0$
as they are attached. Under certain assumptions, it is shown that the probability measures
 $P_n$
converge weakly to some limiting measure, and that the limiting metric space is compact. Since our blocks are identically distributed, the growth of the random recursive metric space is unbounded (and so do not have a compact limit).
$P_n$
converge weakly to some limiting measure, and that the limiting metric space is compact. Since our blocks are identically distributed, the growth of the random recursive metric space is unbounded (and so do not have a compact limit).
1.3. Main result
We start by defining the insertion depth of a block in a random recursive metric space, and the random depth within a block.
Definition 1. For a sequence of random recursive metric spaces
 $\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
, define the (random) insertion depth
$\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
, define the (random) insertion depth
 $\Delta_n$
of the block
$\Delta_n$
of the block
 $\boldsymbol{B}_n$
as the distance from the master hook to the nth latch
$\boldsymbol{B}_n$
as the distance from the master hook to the nth latch
 $v_n$
. That is,
$v_n$
. That is,
 $\Delta_n = D_n(H,v_n)$
.
$\Delta_n = D_n(H,v_n)$
.
Definition 2 Given the block
 $\boldsymbol{B}_n$
, define the random depth
$\boldsymbol{B}_n$
, define the random depth
 $\Delta^{\prime}_n$
within
$\Delta^{\prime}_n$
within
 $\boldsymbol{B}_n$
to be the distance
$\boldsymbol{B}_n$
to be the distance
 $D^{\prime}_n(H^{\prime}_n, U)$
from the hook
$D^{\prime}_n(H^{\prime}_n, U)$
from the hook
 $H^{\prime}_n$
to a point
$H^{\prime}_n$
to a point
 $U \in B_n$
chosen at random according to
$U \in B_n$
chosen at random according to
 $P^{\prime}_n$
.
$P^{\prime}_n$
.
Note that, for
 $n \geq 1$
, all
$n \geq 1$
, all
 $\Delta^{\prime}_n$
are identically and independently distributed to a random variable
$\Delta^{\prime}_n$
are identically and independently distributed to a random variable
 $\Delta^{\prime}$
. The distance functions
$\Delta^{\prime}$
. The distance functions
 $D_n(H,x)$
and
$D_n(H,x)$
and
 $D^{\prime}_n(H_n, x)$
are continuous functions on their respective metric spaces, and so
$D^{\prime}_n(H_n, x)$
are continuous functions on their respective metric spaces, and so
 $\Delta_n$
and
$\Delta_n$
and
 $\Delta^{\prime}_n$
are measurable random variables. We are now ready to state the main result of this work.
$\Delta^{\prime}_n$
are measurable random variables. We are now ready to state the main result of this work.
Theorem 1. Suppose that
 $\mathbb{E}[W^2]$
,
$\mathbb{E}[W^2]$
,
 $\mathbb{E}[(W\Delta^{\prime})^2]$
, and
$\mathbb{E}[(W\Delta^{\prime})^2]$
, and
 $\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
are all finite. Then
$\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
are all finite. Then
 \begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}\left[W\Delta^{\prime}\right]}{\mathbb{E}[W]}, \qquad \frac{\Delta_n - \mathbb{E}[W]^{-1}\mathbb{E}\left[W\Delta^{\prime}\right]\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}\bigg). \end{equation*}
\begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}\left[W\Delta^{\prime}\right]}{\mathbb{E}[W]}, \qquad \frac{\Delta_n - \mathbb{E}[W]^{-1}\mathbb{E}\left[W\Delta^{\prime}\right]\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}\bigg). \end{equation*}
Remark 1. Note that we make no assumptions on
 $\mathbb{E}[(\Delta^{\prime})^2]$
or
$\mathbb{E}[(\Delta^{\prime})^2]$
or
 $\mathbb{E}[\Delta^{\prime}]$
for Theorem 1. Of course, if W and
$\mathbb{E}[\Delta^{\prime}]$
for Theorem 1. Of course, if W and
 $\Delta^{\prime}$
are independent, then moment conditions on
$\Delta^{\prime}$
are independent, then moment conditions on
 $\Delta^{\prime}$
are required.
$\Delta^{\prime}$
are required.
Remark 2. It may be tempting to hope for almost sure (a.s.) convergence instead of convergence in probability in Theorem 1. But almost sure convergence doesn’t hold in even the simplest case, random recursive trees. Devroye proved that for the insertion depth
 $\Delta_n$
in random recursive trees,
$\Delta_n$
in random recursive trees,
 $\Delta_n/\ln n \xrightarrow{\mathrm{p}} 1$
[Reference Devroye8]. But it is well known that the degree of the root in random recursive trees is unbounded, so
$\Delta_n/\ln n \xrightarrow{\mathrm{p}} 1$
[Reference Devroye8]. But it is well known that the degree of the root in random recursive trees is unbounded, so
 $\Delta_n = 0$
occurs infinitely often. Even more, we know that
$\Delta_n = 0$
occurs infinitely often. Even more, we know that
 $H_n = \max\{\Delta_0, \Delta_1, \ldots, \Delta_n\}$
satisfies
$H_n = \max\{\Delta_0, \Delta_1, \ldots, \Delta_n\}$
satisfies
 $H_n/\ln n \xrightarrow{\mathrm{a.s.}} {\mathrm{e}}$
[Reference Pittel23], and so almost sure convergence of the insertion depth cannot hold.
$H_n/\ln n \xrightarrow{\mathrm{a.s.}} {\mathrm{e}}$
[Reference Pittel23], and so almost sure convergence of the insertion depth cannot hold.
To prove Theorem 1, we make use of an observation present in many works on insertion depths in random recursive trees and their generalizations. For each n, define independent Bernoulli random variables
 $Y_{n,0}, Y_{n,1}, Y_{n,2}, \ldots, Y_{n, n-1}$
such that
$Y_{n,0}, Y_{n,1}, Y_{n,2}, \ldots, Y_{n, n-1}$
such that
 \begin{equation*} Y_{n,k} \sim \text{Be}\bigg(\frac{1}{k+1}\bigg).\end{equation*}
\begin{equation*} Y_{n,k} \sim \text{Be}\bigg(\frac{1}{k+1}\bigg).\end{equation*}
It was shown in [Reference Devroye8] that the insertion depth
 $\Delta_n$
of the nth vertex in a random recursive tree is distributed as the number of records in a uniform random permutation, and so has distribution
$\Delta_n$
of the nth vertex in a random recursive tree is distributed as the number of records in a uniform random permutation, and so has distribution
 $\Delta_n \sim \sum_{k=0}^{n-1} Y_{n,k}$
. An application of Lindeberg’s condition on the sum of the independent random variables
$\Delta_n \sim \sum_{k=0}^{n-1} Y_{n,k}$
. An application of Lindeberg’s condition on the sum of the independent random variables
 $Y_{n,k}$
yields a normal limit law for
$Y_{n,k}$
yields a normal limit law for
 $\Delta_n$
. The observation that the insertion depth can be written as a sum of Bernoulli random variables appears in several works; see, for example, [Reference Curien and Haas5, Reference Dobrow9–Reference Eslava11, Reference Haas13, Reference Kuba and Wagner15, Reference Lodewijks16, Reference Mailler and Bravo22, Reference Sénizergues24, Reference Sénizergues25]. In this work, we show that the insertion depth for random recursive metric spaces is a sum of a product of
$\Delta_n$
. The observation that the insertion depth can be written as a sum of Bernoulli random variables appears in several works; see, for example, [Reference Curien and Haas5, Reference Dobrow9–Reference Eslava11, Reference Haas13, Reference Kuba and Wagner15, Reference Lodewijks16, Reference Mailler and Bravo22, Reference Sénizergues24, Reference Sénizergues25]. In this work, we show that the insertion depth for random recursive metric spaces is a sum of a product of
 $\Delta^{\prime}_{n,k} \sim \Delta^{\prime}_k$
and Bernoulli random variables
$\Delta^{\prime}_{n,k} \sim \Delta^{\prime}_k$
and Bernoulli random variables
 $J_{n,k}$
, this time with success probability
$J_{n,k}$
, this time with success probability
 $W_k/S_k$
(see Lemma 1). We then approximate these sums of random variables with martingales that satisfy the conditions necessary to apply a martingale central limit theorem, specifically [Reference Hall and Heyde14, Corollary 3.1].
$W_k/S_k$
(see Lemma 1). We then approximate these sums of random variables with martingales that satisfy the conditions necessary to apply a martingale central limit theorem, specifically [Reference Hall and Heyde14, Corollary 3.1].
2. Applications of Theorem 1
In this section we outline how random recursive metric spaces generalize models of preferential attachment trees, hooking networks, and constructions of iterative gluing of line segments. We recover previous results on the insertion depths, and further generalize these models in natural ways to prove new results. The applications listed here are by no means exhaustive, but are meant to be illustrative of the generality of random recursive metric spaces and of Theorem 1.
2.1. Models of random trees
Consider the following generalization of random recursive trees. Set
 $\alpha \geq 0$
, let
$\alpha \geq 0$
, let
 $A, A_1, A_2, A_3, \ldots$
be independent and identically distributed (i.i.d.) nonnegative random real numbers such that
$A, A_1, A_2, A_3, \ldots$
be independent and identically distributed (i.i.d.) nonnegative random real numbers such that
 $\mathbb{P}(A= 0) < 1$
, and let
$\mathbb{P}(A= 0) < 1$
, and let
 $A_0$
be a strictly positive random real number. A sequence of trees
$A_0$
be a strictly positive random real number. A sequence of trees
 $T_0, T_1, T_2, \ldots$
is constructed with an initial tree
$T_0, T_1, T_2, \ldots$
is constructed with an initial tree
 $T_0$
consisting of a single vertex
$T_0$
consisting of a single vertex
 $v_0$
acting as the root of all trees that follow. At each step
$v_0$
acting as the root of all trees that follow. At each step
 $n \geq 0$
in the growth process, given
$n \geq 0$
in the growth process, given
 $A_0, A_1, \ldots, A_n$
and
$A_0, A_1, \ldots, A_n$
and
 $T_n$
, a vertex
$T_n$
, a vertex
 $v_k$
is chosen at random from
$v_k$
is chosen at random from
 $T_{n}$
with probability
$T_{n}$
with probability
 \begin{equation} \frac{\alpha\deg^+(v_k) + A_k}{\sum_{i=0}^{n}( \alpha\deg^+(v_i) + A_i)},\end{equation}
\begin{equation} \frac{\alpha\deg^+(v_k) + A_k}{\sum_{i=0}^{n}( \alpha\deg^+(v_i) + A_i)},\end{equation}
where
 $\deg^+(v_i)$
is the number of children of
$\deg^+(v_i)$
is the number of children of
 $v_i$
, and an edge is drawn from
$v_i$
, and an edge is drawn from
 $v_k$
to a new child vertex
$v_k$
to a new child vertex
 $v_{n+1}$
to form
$v_{n+1}$
to form
 $T_{n+1}$
. Since
$T_{n+1}$
. Since
 $T_{n}$
has
$T_{n}$
has
 $n+1$
vertices and n edges, the denominator of (2) simplifies to
$n+1$
vertices and n edges, the denominator of (2) simplifies to
 $\alpha n + \sum_{i=0}^{n}A_i$
.
$\alpha n + \sum_{i=0}^{n}A_i$
.
If
 $A_n=1$
for all n, then
$A_n=1$
for all n, then
 $T_0, T_1, T_2, \ldots$
is a sequence of linear preferential attachment trees; this class of random tree models includes random recursive trees (
$T_0, T_1, T_2, \ldots$
is a sequence of linear preferential attachment trees; this class of random tree models includes random recursive trees (
 $\alpha = 0$
) and random plane-oriented recursive trees (
$\alpha = 0$
) and random plane-oriented recursive trees (
 $\alpha =1$
) [Reference Mahmoud20, Reference Szymański27]. If the
$\alpha =1$
) [Reference Mahmoud20, Reference Szymański27]. If the
 $A_i$
are random and
$A_i$
are random and
 $\alpha =0$
, then a sequence of random weighted recursive trees is constructed as in [Reference Lodewijks and Ortgiese18, Reference Mailler and Bravo22, Reference Sénizergues25]. Allowing
$\alpha =0$
, then a sequence of random weighted recursive trees is constructed as in [Reference Lodewijks and Ortgiese18, Reference Mailler and Bravo22, Reference Sénizergues25]. Allowing
 $\alpha > 0$
results in a sequence of preferential attachment trees with additive i.i.d. random fitness (this model appears, for example, in [Reference Lodewijks and Ortgiese17]).
$\alpha > 0$
results in a sequence of preferential attachment trees with additive i.i.d. random fitness (this model appears, for example, in [Reference Lodewijks and Ortgiese17]).
We can further generalize these models of random trees by giving random lengths to the edges, similar to models from [Reference Borovkov and Vatutin3, Reference Broutin and Devroye4]. For a random variable
 $L\geq 0$
such that
$L\geq 0$
such that
 $\mathbb{P}(L=0) < 1$
, when attaching the vertex
$\mathbb{P}(L=0) < 1$
, when attaching the vertex
 $v_n$
to the tree, we can give a ‘length’
$v_n$
to the tree, we can give a ‘length’
 $L_n \sim L$
to the edge joining
$L_n \sim L$
to the edge joining
 $v_n$
to its parent. The insertion depth
$v_n$
to its parent. The insertion depth
 $\Delta_n$
is then the sum of the lengths
$\Delta_n$
is then the sum of the lengths
 $L_k$
along the path from the root to
$L_k$
along the path from the root to
 $v_n$
. The random variable
$v_n$
. The random variable
 $L_n$
can be independent of
$L_n$
can be independent of
 $A_n$
, or we may have a joint distribution on
$A_n$
, or we may have a joint distribution on
 $(A_n, L_n)$
. The tree models described above correspond to the case
$(A_n, L_n)$
. The tree models described above correspond to the case
 $L=1$
.
$L=1$
.
We may construct these trees as random recursive metric spaces. For
 $n \geq 1$
, consider blocks
$n \geq 1$
, consider blocks
 $\boldsymbol{B}_n$
where
$\boldsymbol{B}_n$
where
 $B_n$
is the graph
$B_n$
is the graph
 $K_2$
consisting of two vertices joined by an edge. One of the vertices is labelled
$K_2$
consisting of two vertices joined by an edge. One of the vertices is labelled
 $H^{\prime}_n$
and we will call the other vertex
$H^{\prime}_n$
and we will call the other vertex
 $v_n$
. The metric
$v_n$
. The metric
 $D^{\prime}_n$
on the vertices of
$D^{\prime}_n$
on the vertices of
 $B_n$
is defined so that
$B_n$
is defined so that
 $D^{\prime}_n(H^{\prime}_n, v_n) = L_n$
. The probability measure
$D^{\prime}_n(H^{\prime}_n, v_n) = L_n$
. The probability measure
 $P^{\prime}_n$
is defined such that
$P^{\prime}_n$
is defined such that
 $P^{\prime}_n(H^{\prime}_n) = \alpha/(\alpha + A_n)$
and
$P^{\prime}_n(H^{\prime}_n) = \alpha/(\alpha + A_n)$
and
 $P^{\prime}_n(v_n) = A_n/(\alpha + A_n)$
. The weight of the block
$P^{\prime}_n(v_n) = A_n/(\alpha + A_n)$
. The weight of the block
 $\boldsymbol{B}_n$
is
$\boldsymbol{B}_n$
is
 $W_n = \alpha + A_n$
. Define
$W_n = \alpha + A_n$
. Define
 $\boldsymbol{B}_0$
with
$\boldsymbol{B}_0$
with
 $B_0$
consisting of a single vertex
$B_0$
consisting of a single vertex
 $v_0$
with probability measure
$v_0$
with probability measure
 $P^{\prime}_0(v_0) =1$
. Set the weight of
$P^{\prime}_0(v_0) =1$
. Set the weight of
 $\boldsymbol{B}_0$
to be
$\boldsymbol{B}_0$
to be
 $W_0 = A_0$
. This construction allows us to prove the following theorem.
$W_0 = A_0$
. This construction allows us to prove the following theorem.
Theorem 2. For
 $\alpha \geq 0$
, let
$\alpha \geq 0$
, let
 $T_0, T_1, T_2, \ldots$
be preferential attachment trees with fitness distribution A and random edge lengths with distribution L as described above, and let
$T_0, T_1, T_2, \ldots$
be preferential attachment trees with fitness distribution A and random edge lengths with distribution L as described above, and let
 $\Delta_n$
be the insertion depth of the vertex
$\Delta_n$
be the insertion depth of the vertex
 $v_n$
. If
$v_n$
. If
 $\mathbb{E}[A^2]$
,
$\mathbb{E}[A^2]$
,
 $\mathbb{E}[A^2L^2]$
, and
$\mathbb{E}[A^2L^2]$
, and
 $\mathbb{E}[AL^2]$
are all finite, then
$\mathbb{E}[AL^2]$
are all finite, then
 \begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}[AL]}{\alpha + \mathbb{E}[A]}, \qquad \frac{\Delta_n - (\alpha + \mathbb{E}[A])^{-1}\mathbb{E}[AL]\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}[AL^2]}{\alpha + \mathbb{E}[A]}\bigg). \end{equation*}
\begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}[AL]}{\alpha + \mathbb{E}[A]}, \qquad \frac{\Delta_n - (\alpha + \mathbb{E}[A])^{-1}\mathbb{E}[AL]\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}[AL^2]}{\alpha + \mathbb{E}[A]}\bigg). \end{equation*}
Proof. We start by showing that the random recursive metric spaces
 $\boldsymbol{G}_0,\boldsymbol{G}_1,\boldsymbol{G}_2,\ldots$
constructed from the blocks
$\boldsymbol{G}_0,\boldsymbol{G}_1,\boldsymbol{G}_2,\ldots$
constructed from the blocks
 $\boldsymbol{B}_n$
above are distributed as the trees
$\boldsymbol{B}_n$
above are distributed as the trees
 $T_0,T_1,T_2,\ldots$
. First, we note that
$T_0,T_1,T_2,\ldots$
. First, we note that
 $G_n$
is a tree; every time a latch is attached with a hook, these two vertices are joined together, leaving a new child adjacent to the latch. To see that the trees constructed coincide with the random tree models described above, look at the vertex
$G_n$
is a tree; every time a latch is attached with a hook, these two vertices are joined together, leaving a new child adjacent to the latch. To see that the trees constructed coincide with the random tree models described above, look at the vertex
 $v_k$
(belonging to the block
$v_k$
(belonging to the block
 $\boldsymbol{B}_k$
), and suppose
$\boldsymbol{B}_k$
), and suppose
 $I_{n,k} \subseteq \{k+1, \ldots, n\}$
is the set of indices of blocks
$I_{n,k} \subseteq \{k+1, \ldots, n\}$
is the set of indices of blocks
 $\boldsymbol{B}_i$
whose hook
$\boldsymbol{B}_i$
whose hook
 $H^{\prime}_i$
is joined with
$H^{\prime}_i$
is joined with
 $v_k$
. Then the probability that
$v_k$
. Then the probability that
 $v_k$
is chosen as the latch to construct
$v_k$
is chosen as the latch to construct
 $\boldsymbol{G}_{n+1}$
, by the definition of
$\boldsymbol{G}_{n+1}$
, by the definition of
 $P_n$
as the weighted sum of the probability measures
$P_n$
as the weighted sum of the probability measures
 $P^{\prime}_0, P^{\prime}_1, P^{\prime}_2, \ldots$
, is given by
$P^{\prime}_0, P^{\prime}_1, P^{\prime}_2, \ldots$
, is given by
 \begin{align*} P_n(v_k) = \frac{W_k}{S_n}P^{\prime}_k(v_k) + \sum_{i\in I_{n,k}}\frac{W_i}{S_n}P^{\prime}_i\big(H^{\prime}_i\big) & = \frac{1}{S_n}\Bigg((\alpha + A_k)\frac{A_k}{\alpha + A_k} + \sum_{i\in I_{n,k}}(\alpha + A_i)\frac{\alpha}{\alpha + A_i}\Bigg) \\ & = \frac{\alpha|I_{n,k}| + A_k}{S_n}. \end{align*}
\begin{align*} P_n(v_k) = \frac{W_k}{S_n}P^{\prime}_k(v_k) + \sum_{i\in I_{n,k}}\frac{W_i}{S_n}P^{\prime}_i\big(H^{\prime}_i\big) & = \frac{1}{S_n}\Bigg((\alpha + A_k)\frac{A_k}{\alpha + A_k} + \sum_{i\in I_{n,k}}(\alpha + A_i)\frac{\alpha}{\alpha + A_i}\Bigg) \\ & = \frac{\alpha|I_{n,k}| + A_k}{S_n}. \end{align*}
Since
 $|I_{n,k}| = \deg^+(v_k)$
and
$|I_{n,k}| = \deg^+(v_k)$
and
 $S_n = A_0 + \sum_{k=1}^{n}(\alpha + A_k) = \alpha n + \sum_{k=0}^n A_k$
, we see that
$S_n = A_0 + \sum_{k=1}^{n}(\alpha + A_k) = \alpha n + \sum_{k=0}^n A_k$
, we see that
 $P_{n}(v_k)$
is the same as in (2), and so the two models are equal in distribution.
$P_{n}(v_k)$
is the same as in (2), and so the two models are equal in distribution.
Next, we evaluate W and
 $\Delta^{\prime}$
. We see that
$\Delta^{\prime}$
. We see that
 $\mathbb{E}[W] = \alpha + \mathbb{E}[A]$
and
$\mathbb{E}[W] = \alpha + \mathbb{E}[A]$
and
 $\mathbb{E}[W^2] = \alpha^2 + 2\alpha\mathbb{E}[A] + \mathbb{E}[A^2]$
. Conditioned on
$\mathbb{E}[W^2] = \alpha^2 + 2\alpha\mathbb{E}[A] + \mathbb{E}[A^2]$
. Conditioned on
 $(A_n, L_n)$
, the random variable
$(A_n, L_n)$
, the random variable
 $\Delta^{\prime}_n$
has distribution
$\Delta^{\prime}_n$
has distribution
 \begin{equation*} \Delta^{\prime}_n = \begin{cases} 0 & \text{with probability } \dfrac{\alpha}{\alpha + A_n}, \\[10pt]L_n & \text{with probability } \dfrac{A_n}{\alpha + A_n}, \end{cases} \end{equation*}
\begin{equation*} \Delta^{\prime}_n = \begin{cases} 0 & \text{with probability } \dfrac{\alpha}{\alpha + A_n}, \\[10pt]L_n & \text{with probability } \dfrac{A_n}{\alpha + A_n}, \end{cases} \end{equation*}
and
 $\Delta^{\prime}_0 = 0$
. Quick calculations yield
$\Delta^{\prime}_0 = 0$
. Quick calculations yield
 $\mathbb{E}[W\Delta^{\prime}] = \mathbb{E}[AL]$
and
$\mathbb{E}[W\Delta^{\prime}] = \mathbb{E}[AL]$
and
 $\mathbb{E}\big[W(\Delta^{\prime})^2\big] = \mathbb{E}[AL^2]$
, as well as
$\mathbb{E}\big[W(\Delta^{\prime})^2\big] = \mathbb{E}[AL^2]$
, as well as
 $\mathbb{E}[(W\Delta^{\prime})^2] = \alpha\mathbb{E}[AL^2] + \alpha\mathbb{E}[A^2L^2]$
. The moment conditions to apply Theorem 1 are satisfied if
$\mathbb{E}[(W\Delta^{\prime})^2] = \alpha\mathbb{E}[AL^2] + \alpha\mathbb{E}[A^2L^2]$
. The moment conditions to apply Theorem 1 are satisfied if
 $\mathbb{E}[A^2]$
,
$\mathbb{E}[A^2]$
,
 $\mathbb{E}[A^2L^2]$
, and
$\mathbb{E}[A^2L^2]$
, and
 $\mathbb{E}[AL^2]$
are all finite, proving the theorem.
$\mathbb{E}[AL^2]$
are all finite, proving the theorem.
When
 $L=1$
these results coincide with central limit theorems proved for random recursive trees when
$L=1$
these results coincide with central limit theorems proved for random recursive trees when
 $\alpha = 0$
[Reference Devroye8, Reference Mahmoud19], for random plane-oriented recursive trees when
$\alpha = 0$
[Reference Devroye8, Reference Mahmoud19], for random plane-oriented recursive trees when
 $\alpha = 1$
[Reference Mahmoud20], and for random weighted recursive trees (where stronger results on the profile of vertices were proved in [Reference Mailler and Bravo22, Reference Sénizergues25]). A weak law of large numbers was proved for specific cases of random recursive trees with random edge lengths [Reference Borovkov and Vatutin3, Reference Haas13], but the general result of Theorem 2 is new.
$\alpha = 1$
[Reference Mahmoud20], and for random weighted recursive trees (where stronger results on the profile of vertices were proved in [Reference Mailler and Bravo22, Reference Sénizergues25]). A weak law of large numbers was proved for specific cases of random recursive trees with random edge lengths [Reference Borovkov and Vatutin3, Reference Haas13], but the general result of Theorem 2 is new.
2.2. Hooking networks
For a graph G, let E(G) and V(G) be the edge set and vertex set of G respectively, and let
 $\deg(v)$
be the degree of a vertex in G. Let
$\deg(v)$
be the degree of a vertex in G. Let
 $\mathcal{C} = \{G_1, G_2, G_3, \ldots\}$
be a collection of finite connected graphs (self-loops and multi-edges are allowed) called blocks, each with an identified vertex
$\mathcal{C} = \{G_1, G_2, G_3, \ldots\}$
be a collection of finite connected graphs (self-loops and multi-edges are allowed) called blocks, each with an identified vertex
 $h_i$
called a hook, and each associated with a positive probability
$h_i$
called a hook, and each associated with a positive probability
 $p_i$
such that
$p_i$
such that
 $\sum p_i = 1$
. Let
$\sum p_i = 1$
. Let
 $\chi \geq 0$
and
$\chi \geq 0$
and
 $\rho \in \mathbb{R}$
be two parameters with the condition that
$\rho \in \mathbb{R}$
be two parameters with the condition that
 $\chi+ \rho > 0$
. The hooking networks
$\chi+ \rho > 0$
. The hooking networks
 $\mathcal{H}_0, \mathcal{H}_1, \mathcal{H}_2, \ldots$
are constructed by first setting
$\mathcal{H}_0, \mathcal{H}_1, \mathcal{H}_2, \ldots$
are constructed by first setting
 $\mathcal{H}_0$
as an isomorphic copy of a graph selected from
$\mathcal{H}_0$
as an isomorphic copy of a graph selected from
 $\mathcal{C}$
(at random or not). For
$\mathcal{C}$
(at random or not). For
 $n\geq 0$
,
$n\geq 0$
,
 $\mathcal{H}_{n+1}$
is constructed from
$\mathcal{H}_{n+1}$
is constructed from
 $\mathcal{H}_{n}$
by first selecting a vertex v called a latch from
$\mathcal{H}_{n}$
by first selecting a vertex v called a latch from
 $\mathcal{H}_{n}$
with probability
$\mathcal{H}_{n}$
with probability
 \begin{equation} \frac{\chi\deg(v) + \rho}{\sum_{u \in V(\mathcal{H}_{n})}(\chi\deg(u) + \rho)}.\end{equation}
\begin{equation} \frac{\chi\deg(v) + \rho}{\sum_{u \in V(\mathcal{H}_{n})}(\chi\deg(u) + \rho)}.\end{equation}
Once a latch is selected, a graph
 $G_i$
is selected from
$G_i$
is selected from
 $\mathcal{C}$
with probability
$\mathcal{C}$
with probability
 $p_i$
, and an isomorphic copy of
$p_i$
, and an isomorphic copy of
 $G_i$
is attached by fusing the hook
$G_i$
is attached by fusing the hook
 $h_i$
with the latch v. The selection probability in (3) is very similar to the selection probability (2) for trees. The difference arises from the fact that (3) is a function of the vertex degree instead of the number of children, and the condition
$h_i$
with the latch v. The selection probability in (3) is very similar to the selection probability (2) for trees. The difference arises from the fact that (3) is a function of the vertex degree instead of the number of children, and the condition
 $\chi + \rho > 0$
guarantees that this probability is positive and well defined. Hooking networks were introduced in [Reference Mahmoud21], where the set of blocks consisted of a single graph. The model was generalized in [Reference Desmarais and Holmgren6] to allow for finitely many blocks in
$\chi + \rho > 0$
guarantees that this probability is positive and well defined. Hooking networks were introduced in [Reference Mahmoud21], where the set of blocks consisted of a single graph. The model was generalized in [Reference Desmarais and Holmgren6] to allow for finitely many blocks in
 $\mathcal{C}$
.
$\mathcal{C}$
.
We may generalize hooking networks further by replacing
 $\rho$
with random fitnesses; whenever a graph
$\rho$
with random fitnesses; whenever a graph
 $G_i$
is attached to the hooking network, every vertex
$G_i$
is attached to the hooking network, every vertex
 $v \neq h_i$
from
$v \neq h_i$
from
 $G_i$
is assigned a random fitness
$G_i$
is assigned a random fitness
 $\rho_v$
, such that
$\rho_v$
, such that
 $\chi\deg(v) + \rho_v \geq 0$
and
$\chi\deg(v) + \rho_v \geq 0$
and
 $\mathbb{P}(\chi\deg(v) + \rho_v = 0) < 1$
, independently of the construction of the hooking networks so far (though not necessarily independently of the other vertices within
$\mathbb{P}(\chi\deg(v) + \rho_v = 0) < 1$
, independently of the construction of the hooking networks so far (though not necessarily independently of the other vertices within
 $G_i$
). Then, for future hooking, the probability of selecting
$G_i$
). Then, for future hooking, the probability of selecting
 $v \in \mathcal{H}_{n}$
to be a latch is given by
$v \in \mathcal{H}_{n}$
to be a latch is given by
 \begin{equation} \frac{\chi\deg(v) + \rho_v}{\sum_{u \in V(\mathcal{H}_{n})}(\chi\deg(u) + \rho_u)}.\end{equation}
\begin{equation} \frac{\chi\deg(v) + \rho_v}{\sum_{u \in V(\mathcal{H}_{n})}(\chi\deg(u) + \rho_u)}.\end{equation}
We can construct random recursive metric spaces that are distributed as hooking networks. For
 $n\geq 0$
, we define
$n\geq 0$
, we define
 $\boldsymbol{B}_n$
so that
$\boldsymbol{B}_n$
so that
 $B_n$
is a graph
$B_n$
is a graph
 $G_i$
selected at random from
$G_i$
selected at random from
 $\mathcal{C}$
with probability
$\mathcal{C}$
with probability
 $p_i$
, with an identified hook
$p_i$
, with an identified hook
 $H^{\prime}_n = h_i$
, and
$H^{\prime}_n = h_i$
, and
 $D^{\prime}_n$
is the standard graph metric on
$D^{\prime}_n$
is the standard graph metric on
 $B_n$
. Let
$B_n$
. Let
 $\deg_{B_n}(v)$
be the degree of v within
$\deg_{B_n}(v)$
be the degree of v within
 $B_n$
. Random fitnesses
$B_n$
. Random fitnesses
 $\rho_v$
are then assigned to each vertex
$\rho_v$
are then assigned to each vertex
 $v \in B_n$
such that when v is not the hook,
$v \in B_n$
such that when v is not the hook,
 $\chi\deg_{B_n}(v) + \rho_v \geq 0$
and
$\chi\deg_{B_n}(v) + \rho_v \geq 0$
and
 $\mathbb{P}(\chi\deg_{B_n}(v) + \rho_v = 0) < 1$
, while for the hooks we have the condition
$\mathbb{P}(\chi\deg_{B_n}(v) + \rho_v = 0) < 1$
, while for the hooks we have the condition
 $\chi\deg_{B_0}(H) + \rho_{H} > 0$
when
$\chi\deg_{B_0}(H) + \rho_{H} > 0$
when
 $n=0$
and we set
$n=0$
and we set
 $\rho_{H^{\prime}_n} = 0$
when
$\rho_{H^{\prime}_n} = 0$
when
 $n\geq 1$
(since a hook will be fused with a vertex in the hooking network and only contribute
$n\geq 1$
(since a hook will be fused with a vertex in the hooking network and only contribute
 $\chi\deg_{B_n}(H^{\prime}_n)$
to future hooking). The weight of
$\chi\deg_{B_n}(H^{\prime}_n)$
to future hooking). The weight of
 $\boldsymbol{B}_n$
is given by
$\boldsymbol{B}_n$
is given by
 \begin{equation*} W_n = \sum_{v \in V(B_n)}(\chi \deg_{B_n}(v) + \rho_v) = 2\chi|E(B_n)| + \sum_{v \in V(B_n) }\rho_v,\end{equation*}
\begin{equation*} W_n = \sum_{v \in V(B_n)}(\chi \deg_{B_n}(v) + \rho_v) = 2\chi|E(B_n)| + \sum_{v \in V(B_n) }\rho_v,\end{equation*}
where the last equality follows from the handshaking lemma. The probability
 $P^{\prime}_n$
is defined such that
$P^{\prime}_n$
is defined such that
 $P^{\prime}_n(v) = (\chi \deg_{B_n}(v) + \rho_v)/W_n$
. The condition
$P^{\prime}_n(v) = (\chi \deg_{B_n}(v) + \rho_v)/W_n$
. The condition
 $\chi\deg_{B_0}(H) + \rho_{H} > 0$
for
$\chi\deg_{B_0}(H) + \rho_{H} > 0$
for
 $n=0$
guarantees that
$n=0$
guarantees that
 $W_0 > 0$
.
$W_0 > 0$
.
Given the definition of the blocks
 $\boldsymbol{B}_n$
, we can explicitly calculate the values
$\boldsymbol{B}_n$
, we can explicitly calculate the values
 $\mathbb{E}[W]$
,
$\mathbb{E}[W]$
,
 $\mathbb{E}[W\Delta^{\prime}]$
, and
$\mathbb{E}[W\Delta^{\prime}]$
, and
 $\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
. To start, we have
$\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
. To start, we have
 \begin{equation} \mathbb{E}[W] = \sum_{G_i \in \mathcal{C}} p_i \Bigg(2\chi|E(G_i)| + \sum_{v \in V(G_i)}\mathbb{E}[\rho_v]\Bigg).\end{equation}
\begin{equation} \mathbb{E}[W] = \sum_{G_i \in \mathcal{C}} p_i \Bigg(2\chi|E(G_i)| + \sum_{v \in V(G_i)}\mathbb{E}[\rho_v]\Bigg).\end{equation}
Conditioned on
 $\boldsymbol{B}_n$
, the distribution of
$\boldsymbol{B}_n$
, the distribution of
 $\Delta^{\prime}_n$
is given by
$\Delta^{\prime}_n$
is given by
 \begin{equation*} \mathbb{P}\big(\Delta^{\prime}_n = k \mid \boldsymbol{B}_n\big) = \frac{1}{W_n}\sum_{v \in V(B_n)}\big(\chi\deg_{B_n}(v) + \rho_v\big)\boldsymbol{1}_{\{D^{\prime}_n\big(H^{\prime}_n,v\big) = k\}},\end{equation*}
\begin{equation*} \mathbb{P}\big(\Delta^{\prime}_n = k \mid \boldsymbol{B}_n\big) = \frac{1}{W_n}\sum_{v \in V(B_n)}\big(\chi\deg_{B_n}(v) + \rho_v\big)\boldsymbol{1}_{\{D^{\prime}_n\big(H^{\prime}_n,v\big) = k\}},\end{equation*}
and so
 \begin{equation*} {\mathbb{E}\big[W_n\Delta^{\prime}_n \mid \boldsymbol{B}_n\big]} = W_n\sum_{k=0}^\infty k\mathbb{P}\big(\Delta^{\prime}_n = k \mid \boldsymbol{B}_n\big) = \sum_{v \in V(B_n)} D^{\prime}_n\big(H^{\prime}_n,v\big)\big(\chi\deg_{B_n}(v) + \rho_v\big).\end{equation*}
\begin{equation*} {\mathbb{E}\big[W_n\Delta^{\prime}_n \mid \boldsymbol{B}_n\big]} = W_n\sum_{k=0}^\infty k\mathbb{P}\big(\Delta^{\prime}_n = k \mid \boldsymbol{B}_n\big) = \sum_{v \in V(B_n)} D^{\prime}_n\big(H^{\prime}_n,v\big)\big(\chi\deg_{B_n}(v) + \rho_v\big).\end{equation*}
If we let
 $\delta_{G_i}(v)$
be the distance from
$\delta_{G_i}(v)$
be the distance from
 $h_i$
to v in the graph
$h_i$
to v in the graph
 $G_i$
then, by the law of total expectation,
$G_i$
then, by the law of total expectation,
 \begin{equation} \mathbb{E}[W\Delta^{\prime}] = \sum_{G_i \in \mathcal{C}} p_i \sum_{v \in V(G_i)}\delta_{G_i}(v)\big(\chi\deg_{G_i}(v) + \mathbb{E}[\rho_v]\big),\end{equation}
\begin{equation} \mathbb{E}[W\Delta^{\prime}] = \sum_{G_i \in \mathcal{C}} p_i \sum_{v \in V(G_i)}\delta_{G_i}(v)\big(\chi\deg_{G_i}(v) + \mathbb{E}[\rho_v]\big),\end{equation}
and by a similar argument
 \begin{equation} \mathbb{E}\big[W(\Delta^{\prime})^2\big] = \sum_{G_i \in \mathcal{C}} p_i \sum_{v \in V(G_i)}(\delta_{G_i}(v))^2\big(\chi\deg_{G_i}(v) + \mathbb{E}[\rho_v]\big).\end{equation}
\begin{equation} \mathbb{E}\big[W(\Delta^{\prime})^2\big] = \sum_{G_i \in \mathcal{C}} p_i \sum_{v \in V(G_i)}(\delta_{G_i}(v))^2\big(\chi\deg_{G_i}(v) + \mathbb{E}[\rho_v]\big).\end{equation}
We can also develop equations for
 $\mathbb{E}[W^2]$
and
$\mathbb{E}[W^2]$
and
 $\mathbb{E}[(W\Delta^{\prime})^2]$
, but we simply note that these expressions are only dependent on
$\mathbb{E}[(W\Delta^{\prime})^2]$
, but we simply note that these expressions are only dependent on
 $\mathcal{C}$
, the probabilities
$\mathcal{C}$
, the probabilities
 $p_1, p_2, \ldots$
, and the distributions of the
$p_1, p_2, \ldots$
, and the distributions of the
 $\rho_v$
. We know what conditions are needed to apply Theorem 1 to the random recursive metric spaces
$\rho_v$
. We know what conditions are needed to apply Theorem 1 to the random recursive metric spaces
 $\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
constructed from the blocks
$\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
constructed from the blocks
 $\boldsymbol{B}_n$
. We simply need to show that these random recursive metric spaces are distributed as hooking networks. To avoid confusion with the blocks
$\boldsymbol{B}_n$
. We simply need to show that these random recursive metric spaces are distributed as hooking networks. To avoid confusion with the blocks
 $G_i$
, we will write
$G_i$
, we will write
 $\boldsymbol{G}_n = (\mathcal{G}_n, D_n, H, P_n, S_n)$
for the random recursive metric spaces.
$\boldsymbol{G}_n = (\mathcal{G}_n, D_n, H, P_n, S_n)$
for the random recursive metric spaces.
Theorem 3. Let
 $\mathcal{C} = \{G_1, G_2, G_3, \ldots\}$
be a set of finite graphs with probabilities
$\mathcal{C} = \{G_1, G_2, G_3, \ldots\}$
be a set of finite graphs with probabilities
 $p_1, p_2, p_3, \ldots$
that sum to 1, and independently for each graph
$p_1, p_2, p_3, \ldots$
that sum to 1, and independently for each graph
 $G_i$
, let
$G_i$
, let
 $\rho_v$
be a fitness distribution for each
$\rho_v$
be a fitness distribution for each
 $v \in G_i$
satisfying the conditions above. Let
$v \in G_i$
satisfying the conditions above. Let
 $\mathcal{H}_0, \mathcal{H}_1, \mathcal{H}_2, \ldots$
be hooking networks constructed as above, and let
$\mathcal{H}_0, \mathcal{H}_1, \mathcal{H}_2, \ldots$
be hooking networks constructed as above, and let
 $\Delta_n$
be the insertion depth of the nth block. If
$\Delta_n$
be the insertion depth of the nth block. If
 $\mathbb{E}[W^2]$
,
$\mathbb{E}[W^2]$
,
 $\mathbb{E}[(W\Delta^{\prime})^2]$
, and
$\mathbb{E}[(W\Delta^{\prime})^2]$
, and
 $\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
are all finite, then
$\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
are all finite, then
 \begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}[W\Delta^{\prime}]}{\mathbb{E}[W]}, \qquad \frac{\Delta_n - \mathbb{E}[W]^{-1}\mathbb{E}[W\Delta^{\prime}]\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}\bigg), \end{equation*}
\begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}[W\Delta^{\prime}]}{\mathbb{E}[W]}, \qquad \frac{\Delta_n - \mathbb{E}[W]^{-1}\mathbb{E}[W\Delta^{\prime}]\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}\bigg), \end{equation*}
where
 $\mathbb{E}[W]$
,
$\mathbb{E}[W]$
,
 $\mathbb{E}[W\Delta^{\prime}]$
, and
$\mathbb{E}[W\Delta^{\prime}]$
, and
 $\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
are given in (5), (6), and (7) respectively.
$\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
are given in (5), (6), and (7) respectively.
Proof. Similar to the proof of Theorem 2, we only need to show that the selection of a latch
 $v_n$
in the random recursive metric space
$v_n$
in the random recursive metric space
 $\boldsymbol{G}_n$
is made with probability (4) to prove they have the same distribution. Let v be a vertex in
$\boldsymbol{G}_n$
is made with probability (4) to prove they have the same distribution. Let v be a vertex in
 $\mathcal{G}_n$
, and let k be the smallest value for which v belongs to
$\mathcal{G}_n$
, and let k be the smallest value for which v belongs to
 $B_k$
(recall that all hooks other than H are fused with some other vertex in the hooking network). Let
$B_k$
(recall that all hooks other than H are fused with some other vertex in the hooking network). Let
 $I_{n,v} \subseteq \{k+1, \ldots, n\}$
be the set of indices of blocks
$I_{n,v} \subseteq \{k+1, \ldots, n\}$
be the set of indices of blocks
 $\boldsymbol{B}_i$
whose hook
$\boldsymbol{B}_i$
whose hook
 $H^{\prime}_i$
is fused with v. Since
$H^{\prime}_i$
is fused with v. Since
 $\rho_{H^{\prime}_i} = 0$
for all
$\rho_{H^{\prime}_i} = 0$
for all
 $i \in I_{n,v}$
, the probability of selecting v as a latch to construct
$i \in I_{n,v}$
, the probability of selecting v as a latch to construct
 $\mathcal{G}_{n+1}$
is given by
$\mathcal{G}_{n+1}$
is given by
 \begin{equation*} P_n(v) = \frac{W_k}{S_n}P^{\prime}_k(v) + \sum_{i\in I_{n,v}}\frac{W_i}{S_n}P^{\prime}_i\big(H^{\prime}_i\big) = \frac{1}{S_n}\Bigg(\chi\deg_{B_k}(v) + \rho_v + \sum_{i \in I_{n,v}}\chi\deg_{B_i}\big(H^{\prime}_i\big)\Bigg). \end{equation*}
\begin{equation*} P_n(v) = \frac{W_k}{S_n}P^{\prime}_k(v) + \sum_{i\in I_{n,v}}\frac{W_i}{S_n}P^{\prime}_i\big(H^{\prime}_i\big) = \frac{1}{S_n}\Bigg(\chi\deg_{B_k}(v) + \rho_v + \sum_{i \in I_{n,v}}\chi\deg_{B_i}\big(H^{\prime}_i\big)\Bigg). \end{equation*}
Since fusing a hook
 $H^{\prime}_i$
to v increases the degree of v by
$H^{\prime}_i$
to v increases the degree of v by
 $\deg_i\big(H^{\prime}_i\big)$
in the hooking network, then
$\deg_i\big(H^{\prime}_i\big)$
in the hooking network, then
 $\chi\deg_{B_k}(v) + \rho_v + \sum_{i \in I_{n,v}} \chi\deg_{B_i}\big(H^{\prime}_i\big) = \chi\deg(v) + \rho_v$
, where
$\chi\deg_{B_k}(v) + \rho_v + \sum_{i \in I_{n,v}} \chi\deg_{B_i}\big(H^{\prime}_i\big) = \chi\deg(v) + \rho_v$
, where
 $\deg(v)$
is the degree of v in
$\deg(v)$
is the degree of v in
 $\mathcal{G}_n$
, which is the numerator in (4). Every time a block
$\mathcal{G}_n$
, which is the numerator in (4). Every time a block
 $\boldsymbol{B}_k$
is attached to the hooking network,
$\boldsymbol{B}_k$
is attached to the hooking network,
 $|E(B_k)|$
new edges are added, and using again that
$|E(B_k)|$
new edges are added, and using again that
 $\rho_{H^{\prime}_n} = 0$
for all
$\rho_{H^{\prime}_n} = 0$
for all
 $n \geq 1$
,
$n \geq 1$
,
 \begin{equation*} S_n = \sum_{k=0}^n W_k = \sum_{k=0}^n\Bigg(2\chi|E(B_n)| + \sum_{v \in V(B_k)}\rho_v\Bigg) = 2\chi|E(\mathcal{G}_n)| + \sum_{v \in V(\mathcal{G}_n)}\rho_v. \end{equation*}
\begin{equation*} S_n = \sum_{k=0}^n W_k = \sum_{k=0}^n\Bigg(2\chi|E(B_n)| + \sum_{v \in V(B_k)}\rho_v\Bigg) = 2\chi|E(\mathcal{G}_n)| + \sum_{v \in V(\mathcal{G}_n)}\rho_v. \end{equation*}
By applying the handshaking lemma,
 $S_n$
is the denominator in (4). Thus, the probability of choosing any vertex
$S_n$
is the denominator in (4). Thus, the probability of choosing any vertex
 $v \in V(\mathcal{G}_n)$
to be a latch is equal to (4), and the random recursive metric spaces are distributed as hooking networks. Applying Theorem 1 completes the proof.
$v \in V(\mathcal{G}_n)$
to be a latch is equal to (4), and the random recursive metric spaces are distributed as hooking networks. Applying Theorem 1 completes the proof.
The classic hooking networks are recovered if the
 $\rho_v$
are all equal to a deterministic
$\rho_v$
are all equal to a deterministic
 $\rho$
for all vertices v other than
$\rho$
for all vertices v other than
 $H^{\prime}_n$
for
$H^{\prime}_n$
for
 $n \geq 1$
(and
$n \geq 1$
(and
 $\rho_{H^{\prime}_n} =0$
). If
$\rho_{H^{\prime}_n} =0$
). If
 $\mathcal{C}$
is also a finite collection of finite graphs, then it is evident that the moment conditions of Theorem 3 are satisfied. When the weights
$\mathcal{C}$
is also a finite collection of finite graphs, then it is evident that the moment conditions of Theorem 3 are satisfied. When the weights
 $W_n$
are deterministic, which holds, for example, when
$W_n$
are deterministic, which holds, for example, when
 $\chi =0$
and all blocks have the same number of vertices, or when
$\chi =0$
and all blocks have the same number of vertices, or when
 $\rho =0$
for all vertices and all blocks have the same number of edges, a normal limit law for the insertion depth was proved in [Reference Desmarais and Mahmoud7] (where the term affinity is used for the weight of the blocks). Theorem 3 generalizes this result in the classic case by allowing for blocks that produce random weights
$\rho =0$
for all vertices and all blocks have the same number of edges, a normal limit law for the insertion depth was proved in [Reference Desmarais and Mahmoud7] (where the term affinity is used for the weight of the blocks). Theorem 3 generalizes this result in the classic case by allowing for blocks that produce random weights
 $W_n$
. When
$W_n$
. When
 $\rho_v$
are random, the moment conditions for Theorem 3 are also met if
$\rho_v$
are random, the moment conditions for Theorem 3 are also met if
 $\mathcal{C}$
is finite and if
$\mathcal{C}$
is finite and if
 $\mathbb{E}[\rho^2_v] < \infty$
and
$\mathbb{E}[\rho^2_v] < \infty$
and
 $\mathbb{E}[\rho_v\rho_u] < \infty$
for all u,v in a graph
$\mathbb{E}[\rho_v\rho_u] < \infty$
for all u,v in a graph
 $G_i$
.
$G_i$
.
The set of blocks
 $\mathcal{C}$
can also be infinite. We present an example where the blocks are paths of geometric lengths. Fix
$\mathcal{C}$
can also be infinite. We present an example where the blocks are paths of geometric lengths. Fix
 $p \in (0,1)$
and let
$p \in (0,1)$
and let
 $\chi =0$
and
$\chi =0$
and
 $\rho =1$
(so latches are chosen uniformly at random among all the vertices when growing the hooking network). Let
$\rho =1$
(so latches are chosen uniformly at random among all the vertices when growing the hooking network). Let
 $W_n \sim \mathrm{Ge}(p)$
, and let
$W_n \sim \mathrm{Ge}(p)$
, and let
 $B_n$
be a path of length
$B_n$
be a path of length
 $W_n$
(with
$W_n$
(with
 $W_n+1$
vertices). Then the weight of this block is
$W_n+1$
vertices). Then the weight of this block is
 $W_n$
and
$W_n$
and
 $P^{\prime}_n(v) = 1/W_n$
for
$P^{\prime}_n(v) = 1/W_n$
for
 $v \neq H^{\prime}_n$
(and
$v \neq H^{\prime}_n$
(and
 $P^{\prime}_n(H^{\prime}_n) = 0$
). Given
$P^{\prime}_n(H^{\prime}_n) = 0$
). Given
 $W_n$
, the random variable
$W_n$
, the random variable
 $\Delta^{\prime}_n$
is distributed as
$\Delta^{\prime}_n$
is distributed as
 $\mathbb{P}(\Delta^{\prime}_n = j) = 1/W_n$
for
$\mathbb{P}(\Delta^{\prime}_n = j) = 1/W_n$
for
 $j=1, 2, \ldots, n$
. Quick calculations reveal that
$j=1, 2, \ldots, n$
. Quick calculations reveal that
 $\mathbb{E}[W] = 1/p$
,
$\mathbb{E}[W] = 1/p$
,
 $\mathbb{E}[W\Delta^{\prime}] = 1/p^2$
, and
$\mathbb{E}[W\Delta^{\prime}] = 1/p^2$
, and
 $\mathbb{E}\big[W(\Delta^{\prime})^2\big] = (2-p)/p^3$
. Applying Theorem 3 gives
$\mathbb{E}\big[W(\Delta^{\prime})^2\big] = (2-p)/p^3$
. Applying Theorem 3 gives
 \begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{1}{p}, \qquad \frac{\Delta_n - ({1}/{p})\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{2-p}{p^2}\bigg).\end{equation*}
\begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{1}{p}, \qquad \frac{\Delta_n - ({1}/{p})\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{2-p}{p^2}\bigg).\end{equation*}
We note that we may apply Theorem 1 to further generalizations of hooking networks; for example, we may also assign random lengths to the edges (similar to the random lengths added to edges of trees in Section 2.1), though we note that the shortest path from one vertex to another may change depending on the edge lengths.
2.3. Constructions from line segments
In the applications we have seen so far, the blocks have been discrete metric spaces. But we can certainly take continuous spaces as well. As a simple example, we present random trees constructed from line segments similar to those in [Reference Amini, Devroye, Griffiths and Olver2, Reference Curien and Haas5, Reference Haas13].
Let
 $W, W_1, W_2, \ldots$
be i.i.d. nonnegative random variables with
$W, W_1, W_2, \ldots$
be i.i.d. nonnegative random variables with
 $\mathbb{P}[W = 0] < 1$
, and let
$\mathbb{P}[W = 0] < 1$
, and let
 $B_n$
be a line segment of length
$B_n$
be a line segment of length
 $W_n$
. We recursively construct the spaces
$W_n$
. We recursively construct the spaces
 $\mathcal{T}_0, \mathcal{T}_1, \mathcal{T}_2, \ldots$
in the following way:
$\mathcal{T}_0, \mathcal{T}_1, \mathcal{T}_2, \ldots$
in the following way:
 $\mathcal{T}_0$
is the line segment
$\mathcal{T}_0$
is the line segment
 $B_0$
with one endpoint called a root, and for
$B_0$
with one endpoint called a root, and for
 $n\geq 0$
, sample a point v uniformly at random from
$n\geq 0$
, sample a point v uniformly at random from
 $\mathcal{T}_{n}$
and glue the segment
$\mathcal{T}_{n}$
and glue the segment
 $B_n$
to v. A law of large numbers for the insertion depth was proved for the case
$B_n$
to v. A law of large numbers for the insertion depth was proved for the case
 $W=1$
in [Reference Haas13]. We apply Theorem 1 to the more general spaces
$W=1$
in [Reference Haas13]. We apply Theorem 1 to the more general spaces
 $\mathcal{T}_n$
.
$\mathcal{T}_n$
.
In the notation of random recursive metric spaces, define the blocks
 $\boldsymbol{B}_n$
in the following way. Let
$\boldsymbol{B}_n$
in the following way. Let
 $B_n$
be a copy of the line segment
$B_n$
be a copy of the line segment
 $[0,W_n]$
with Euclidean metric
$[0,W_n]$
with Euclidean metric
 $D^{\prime}_n$
, and let the point 0 be the hook
$D^{\prime}_n$
, and let the point 0 be the hook
 $H^{\prime}_n$
. Let
$H^{\prime}_n$
. Let
 $P^{\prime}_n$
be uniform on
$P^{\prime}_n$
be uniform on
 $B_n$
(so
$B_n$
(so
 $P^{\prime}_n$
has the same distribution as the uniform distribution
$P^{\prime}_n$
has the same distribution as the uniform distribution
 $U[0,W_n]$
). Set the weight of
$U[0,W_n]$
). Set the weight of
 $\boldsymbol{B}_n$
as
$\boldsymbol{B}_n$
as
 $W_n$
. We can show that the random recursive metric spaces are distributed as
$W_n$
. We can show that the random recursive metric spaces are distributed as
 $\mathcal{T}_n$
, and so we just need to find the moment conditions on W needed to apply Theorem 1.
$\mathcal{T}_n$
, and so we just need to find the moment conditions on W needed to apply Theorem 1.
Theorem 4. Let
 $\mathcal{T}_0, \mathcal{T}_1, \mathcal{T}_2, \ldots$
be the random spaces defined above, and let
$\mathcal{T}_0, \mathcal{T}_1, \mathcal{T}_2, \ldots$
be the random spaces defined above, and let
 $\Delta_n$
be the distance from the root to where the nth segment is glued. If
$\Delta_n$
be the distance from the root to where the nth segment is glued. If
 $\mathbb{E}[W^4] < \infty$
, then
$\mathbb{E}[W^4] < \infty$
, then
 \begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}[W^2]}{2\mathbb{E}[W]}, \qquad \frac{\Delta_n - \frac{1}{2}(\mathbb{E}[W])^{-1}\mathbb{E}[W^2]\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}[W^3]}{3\mathbb{E}[W]}\bigg). \end{equation*}
\begin{equation*} \frac{\Delta_n}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}[W^2]}{2\mathbb{E}[W]}, \qquad \frac{\Delta_n - \frac{1}{2}(\mathbb{E}[W])^{-1}\mathbb{E}[W^2]\ln n}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}[W^3]}{3\mathbb{E}[W]}\bigg). \end{equation*}
Proof. It is evident that the random recursive metric spaces constructed from
 $\boldsymbol{B}_n$
are distributed as
$\boldsymbol{B}_n$
are distributed as
 $\mathcal{T}_0, \mathcal{T}_1, \mathcal{T}_2, \ldots$
; at each step
$\mathcal{T}_0, \mathcal{T}_1, \mathcal{T}_2, \ldots$
; at each step
 $n \geq 0$
we can sample v from
$n \geq 0$
we can sample v from
 $\mathcal{T}_{n}$
by first sampling the segment
$\mathcal{T}_{n}$
by first sampling the segment
 $B_k$
with probability
$B_k$
with probability
 $W_k/S_{n}$
and sampling a point uniformly in
$W_k/S_{n}$
and sampling a point uniformly in
 $B_k$
. From the first two moments of the uniform distribution we get that
$B_k$
. From the first two moments of the uniform distribution we get that
 \begin{equation*} {\mathbb{E}[W_n\Delta^{\prime}_n \mid W_n]} = \frac{W_n^2}{2}, \qquad {\mathbb{E}[W_n(\Delta^{\prime}_n)^2 \mid W_n]} = \frac{W_n^3}{3}, \qquad {\mathbb{E}[(W_n\Delta^{\prime}_n)^2 \mid W_n]} = \frac{W_n^4}{3}, \end{equation*}
\begin{equation*} {\mathbb{E}[W_n\Delta^{\prime}_n \mid W_n]} = \frac{W_n^2}{2}, \qquad {\mathbb{E}[W_n(\Delta^{\prime}_n)^2 \mid W_n]} = \frac{W_n^3}{3}, \qquad {\mathbb{E}[(W_n\Delta^{\prime}_n)^2 \mid W_n]} = \frac{W_n^4}{3}, \end{equation*}
and so, from the law of total expectation,
 \begin{equation*} \mathbb{E}[W\Delta^{\prime}] = \frac{\mathbb{E}[W^2]}{2}, \qquad \mathbb{E}\big[W(\Delta^{\prime})^2\big] = \frac{\mathbb{E}[W^3]}{3}, \qquad \mathbb{E}[(W\Delta^{\prime})^2] = \frac{\mathbb{E}[W^4]}{3}. \end{equation*}
\begin{equation*} \mathbb{E}[W\Delta^{\prime}] = \frac{\mathbb{E}[W^2]}{2}, \qquad \mathbb{E}\big[W(\Delta^{\prime})^2\big] = \frac{\mathbb{E}[W^3]}{3}, \qquad \mathbb{E}[(W\Delta^{\prime})^2] = \frac{\mathbb{E}[W^4]}{3}. \end{equation*}
Thus, we apply Theorem 1 if
 $\mathbb{E}[W^4] < \infty$
, proving the theorem.
$\mathbb{E}[W^4] < \infty$
, proving the theorem.
3. Proof of Theorem 1
Given the blocks
 $\boldsymbol{B}_0, \boldsymbol{B}_1, \boldsymbol{B}_2, \ldots$
, for every n define for
$\boldsymbol{B}_0, \boldsymbol{B}_1, \boldsymbol{B}_2, \ldots$
, for every n define for
 $k=0, 1, \ldots, n-1$
the sequence of independent (conditioned on the blocks) random variables
$k=0, 1, \ldots, n-1$
the sequence of independent (conditioned on the blocks) random variables
 $Y_{n,k} = J_{n,k}\Delta^{\prime}_{n,k}$
, where
$Y_{n,k} = J_{n,k}\Delta^{\prime}_{n,k}$
, where
 \begin{equation*}J_{n,k} \sim \text{Be}\bigg(\frac{W_k}{S_k}\bigg),\end{equation*}
\begin{equation*}J_{n,k} \sim \text{Be}\bigg(\frac{W_k}{S_k}\bigg),\end{equation*}
 $\Delta^{\prime}_{n,k} \sim \Delta^{\prime}_k$
for
$\Delta^{\prime}_{n,k} \sim \Delta^{\prime}_k$
for
 $k\geq 1$
, and
$k\geq 1$
, and
 $\Delta^{\prime}_{n,0} \sim \Delta^{\prime}_0$
. Notice that
$\Delta^{\prime}_{n,0} \sim \Delta^{\prime}_0$
. Notice that
 $J_{n,0} = 1$
. Conditioned on
$J_{n,0} = 1$
. Conditioned on
 $\boldsymbol{B}_0, \boldsymbol{B}_1, \boldsymbol{B}_2, \ldots$
, the random variables
$\boldsymbol{B}_0, \boldsymbol{B}_1, \boldsymbol{B}_2, \ldots$
, the random variables
 $J_{n,k}$
and
$J_{n,k}$
and
 $\Delta^{\prime}_{n,k}$
are taken to be independent (though of course
$\Delta^{\prime}_{n,k}$
are taken to be independent (though of course
 $W_k$
and
$W_k$
and
 $\Delta^{\prime}_{n,k} \sim \Delta^{\prime}_k$
are dependent on the block
$\Delta^{\prime}_{n,k} \sim \Delta^{\prime}_k$
are dependent on the block
 $\boldsymbol{B}_k$
).
$\boldsymbol{B}_k$
).
As mentioned in the introduction, several previous works have described the insertion depth in related models as sums of Bernoulli random variables. Here, we provide a similar observation for random recursive metric spaces, in this case describing the insertion depth as the sum of
 $Y_{n,k}$
. Let
$Y_{n,k}$
. Let
 $\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
be random recursive metric spaces constructed from the blocks
$\boldsymbol{G}_0, \boldsymbol{G}_1, \boldsymbol{G}_2, \ldots$
be random recursive metric spaces constructed from the blocks
 $\boldsymbol{B}_n$
. By the definition of the probability measure
$\boldsymbol{B}_n$
. By the definition of the probability measure
 $P_n$
, we can choose the latch
$P_n$
, we can choose the latch
 $v_{n+1}$
by first choosing a block
$v_{n+1}$
by first choosing a block
 $\boldsymbol{B}_k$
already attached to
$\boldsymbol{B}_k$
already attached to
 $G_n$
with probability
$G_n$
with probability
 $W_k/S_n$
, and then choosing the latch
$W_k/S_n$
, and then choosing the latch
 $v_{n+1}$
within
$v_{n+1}$
within
 $B_k$
according to
$B_k$
according to
 $P^{\prime}_k$
. Once the new block
$P^{\prime}_k$
. Once the new block
 $\boldsymbol{B}_{n+1}$
is attached to
$\boldsymbol{B}_{n+1}$
is attached to
 $v_{n+1}$
, we will say that the block
$v_{n+1}$
, we will say that the block
 $\boldsymbol{B}_{n+1}$
is a child of the block
$\boldsymbol{B}_{n+1}$
is a child of the block
 $\boldsymbol{B}_k$
. Similarly define the notion of blocks as parents, descendants, and ancestors. For a fixed n, let
$\boldsymbol{B}_k$
. Similarly define the notion of blocks as parents, descendants, and ancestors. For a fixed n, let
 $0 = k_0< k_1 < \cdots < k_t$
be all the values
$0 = k_0< k_1 < \cdots < k_t$
be all the values
 $k_i$
for which
$k_i$
for which
 $J_{n,k_i} = 1$
, and let
$J_{n,k_i} = 1$
, and let
 $k_{t+1} = n$
. We will develop a coupling between the collection of random variables
$k_{t+1} = n$
. We will develop a coupling between the collection of random variables
 $Y_{n,k}, J_{n,k},\Delta^{\prime}_{n,k}$
and random recursive metric spaces, whereby
$Y_{n,k}, J_{n,k},\Delta^{\prime}_{n,k}$
and random recursive metric spaces, whereby
 $J_{n,k} = 1$
if and only if
$J_{n,k} = 1$
if and only if
 $\boldsymbol{B}_k$
is an ancestor of
$\boldsymbol{B}_k$
is an ancestor of
 $\boldsymbol{B}_n$
in the random recursive metric space and
$\boldsymbol{B}_n$
in the random recursive metric space and
 $D_n(v_{k_i}, v_{k_{i+1}})$
is distributed as
$D_n(v_{k_i}, v_{k_{i+1}})$
is distributed as
 $\Delta_{n,k^{\prime}_{i}}$
for all
$\Delta_{n,k^{\prime}_{i}}$
for all
 $i=0,\ldots, t$
. If this holds, then
$i=0,\ldots, t$
. If this holds, then
 \begin{equation*} \Delta_n = \sum_{i=0}^{t} D_n(v_{k_i}, v_{k_{i+1}}) \sim \sum_{k=0}^{n-1} J_{n,k}\Delta^{\prime}_{n,k} =\sum_{k=0}^{n-1} Y_{n,k}.\end{equation*}
\begin{equation*} \Delta_n = \sum_{i=0}^{t} D_n(v_{k_i}, v_{k_{i+1}}) \sim \sum_{k=0}^{n-1} J_{n,k}\Delta^{\prime}_{n,k} =\sum_{k=0}^{n-1} Y_{n,k}.\end{equation*}
The following lemma is contained in the proof of [Reference Sénizergues24, Lemma 3], but we provide a proof for the sake of completeness.
Lemma 1. With
 $Y_{n,k}$
defined above, the insertion depth
$Y_{n,k}$
defined above, the insertion depth
 $\Delta_n$
of the nth block added to a random recursive metric space
$\Delta_n$
of the nth block added to a random recursive metric space
 $\boldsymbol{G}_n$
is distributed as
$\boldsymbol{G}_n$
is distributed as
 $\Delta_n \sim \sum_{k=0}^{n-1}Y_{n,k}$
.
$\Delta_n \sim \sum_{k=0}^{n-1}Y_{n,k}$
.
Proof. Fix the step n throughout this proof. For a sequence of blocks
 $\boldsymbol{B}_0, \boldsymbol{B}_1, \ldots, \boldsymbol{B}_n$
, sample the random variables
$\boldsymbol{B}_0, \boldsymbol{B}_1, \ldots, \boldsymbol{B}_n$
, sample the random variables
 $J_{n,k}$
,
$J_{n,k}$
,
 $\Delta^{\prime}_{n,k}$
, and
$\Delta^{\prime}_{n,k}$
, and
 $Y_{n,k}$
as described above. We construct a sequence of random recursive metric spaces
$Y_{n,k}$
as described above. We construct a sequence of random recursive metric spaces
 $\boldsymbol{G}_{0}, \boldsymbol{G}_{1}, \ldots, \boldsymbol{G}_{n}$
. Set
$\boldsymbol{G}_{0}, \boldsymbol{G}_{1}, \ldots, \boldsymbol{G}_{n}$
. Set
 $\boldsymbol{G}_{0} = \boldsymbol{B}_0$
. For
$\boldsymbol{G}_{0} = \boldsymbol{B}_0$
. For
 $k=1,2,\ldots,n$
, choose the latch
$k=1,2,\ldots,n$
, choose the latch
 $v_{k}$
by first choosing a block
$v_{k}$
by first choosing a block
 $\boldsymbol{B}_{\ell_k}$
in the following way:
$\boldsymbol{B}_{\ell_k}$
in the following way:
-
If
 $k=n$
or
$J_{n,k} =1$
, then
$\ell_k = \max_{0 \leq k^{\prime} < k}\{J_{n,k^{\prime}} = 1\}$
. This is always defined since
$J_{n,0} = 1$
. Next, choose the latch
$v_k$
within
$B_{\ell_k}$
according to
$P^{\prime}_{\ell_k}$
conditioned on
$D^{\prime}_{\ell_k}(H^{\prime}_{\ell_k}, v_k) = \Delta^{\prime}_{n,\ell_k}$
(this is well defined by the Radon–Nikodym theorem since
$\{x \in B_{\ell_k} \colon D^{\prime}_{\ell_k}(H_{\ell_k}, x) = \Delta^{\prime}_{n,\ell_k}\}$
is a closed set in
$B_{\ell_k}$
, and so belongs to the sigma algebra for which
$P^{\prime}_{\ell_k}$
is defined).
$k=n$
or
$J_{n,k} =1$
, then
$\ell_k = \max_{0 \leq k^{\prime} < k}\{J_{n,k^{\prime}} = 1\}$
. This is always defined since
$J_{n,0} = 1$
. Next, choose the latch
$v_k$
within
$B_{\ell_k}$
according to
$P^{\prime}_{\ell_k}$
conditioned on
$D^{\prime}_{\ell_k}(H^{\prime}_{\ell_k}, v_k) = \Delta^{\prime}_{n,\ell_k}$
(this is well defined by the Radon–Nikodym theorem since
$\{x \in B_{\ell_k} \colon D^{\prime}_{\ell_k}(H_{\ell_k}, x) = \Delta^{\prime}_{n,\ell_k}\}$
is a closed set in
$B_{\ell_k}$
, and so belongs to the sigma algebra for which
$P^{\prime}_{\ell_k}$
is defined). -
If
$k \neq n$
and
$J_{n,k} = 0$
, then
$\ell_k$
is chosen at random among
$0,1,2,\ldots,k-1$
with probability
$W_{\ell_k}/S_{k-1}$
, and
$v_k$
is chosen in
$B_{\ell_k}$
according to
$P^{\prime}_{\ell_k}$
.



















If
 $0 = k_0< k_1 < \cdots < k_t$
are all the values
$0 = k_0< k_1 < \cdots < k_t$
are all the values
 $k_i$
for which
$k_i$
for which
 $J_{n,k_i} = 1$
, notice that the parent of
$J_{n,k_i} = 1$
, notice that the parent of
 $\boldsymbol{B}_n$
is
$\boldsymbol{B}_n$
is
 $\boldsymbol{B}_{k_t}$
, the parent of
$\boldsymbol{B}_{k_t}$
, the parent of
 $\boldsymbol{B}_{k_t}$
is
$\boldsymbol{B}_{k_t}$
is
 $\boldsymbol{B}_{k_{t-1}}$
, and so on until
$\boldsymbol{B}_{k_{t-1}}$
, and so on until
 $\boldsymbol{B}_0$
. Conversely, if
$\boldsymbol{B}_0$
. Conversely, if
 $J_{n,k} = 0$
, then
$J_{n,k} = 0$
, then
 $\boldsymbol{B}_k$
cannot be the parent of any of
$\boldsymbol{B}_k$
cannot be the parent of any of
 $\boldsymbol{B}_{k_1}, \boldsymbol{B}_{k_2}, \ldots, \boldsymbol{B}_{k_t}, \boldsymbol{B}_n$
. Therefore, the block
$\boldsymbol{B}_{k_1}, \boldsymbol{B}_{k_2}, \ldots, \boldsymbol{B}_{k_t}, \boldsymbol{B}_n$
. Therefore, the block
 $\boldsymbol{B}_k$
is an ancestor of
$\boldsymbol{B}_k$
is an ancestor of
 $\boldsymbol{B}_n$
if and only if
$\boldsymbol{B}_n$
if and only if
 $J_{n,k} = 1$
.
$J_{n,k} = 1$
.
To prove that
 $\boldsymbol{G}_{0}, \boldsymbol{G}_{n}, \ldots, \boldsymbol{G}_{n}$
is distributed as random recursive metric spaces, we need only show that the choice of
$\boldsymbol{G}_{0}, \boldsymbol{G}_{n}, \ldots, \boldsymbol{G}_{n}$
is distributed as random recursive metric spaces, we need only show that the choice of
 $\ell_k$
is made with probability
$\ell_k$
is made with probability
 $W_{\ell_k}/S_{k-1}$
. Indeed, we see that, conditioned on the blocks
$W_{\ell_k}/S_{k-1}$
. Indeed, we see that, conditioned on the blocks
 $\boldsymbol{B}_0, \boldsymbol{B}_1, \ldots, \boldsymbol{B}_n$
, for
$\boldsymbol{B}_0, \boldsymbol{B}_1, \ldots, \boldsymbol{B}_n$
, for
 $k < n$
,
$k < n$
,
 $\ell_k$
is chosen with probability
$\ell_k$
is chosen with probability
 \begin{equation} \mathbb{P}(J_{n,k}=1, J_{n,\ell_k}=1, J_{n,\ell_k+1}=\cdots=J_{n,k-1}=0) + \mathbb{P}(J_{n,k}=0)\frac{W_{\ell_k}}{S_{k-1}}, \end{equation}
\begin{equation} \mathbb{P}(J_{n,k}=1, J_{n,\ell_k}=1, J_{n,\ell_k+1}=\cdots=J_{n,k-1}=0) + \mathbb{P}(J_{n,k}=0)\frac{W_{\ell_k}}{S_{k-1}}, \end{equation}
and when
 $k=n$
,
$k=n$
,
 $\ell_k < n-1$
is chosen with probability
$\ell_k < n-1$
is chosen with probability
 \begin{equation} \mathbb{P}(J_{n,\ell_k} = 1, J_{n,\ell_k+1}=\cdots=J_{n,k-1} =0), \end{equation}
\begin{equation} \mathbb{P}(J_{n,\ell_k} = 1, J_{n,\ell_k+1}=\cdots=J_{n,k-1} =0), \end{equation}
and
 $\ell_k = n-1$
is chosen with probability
$\ell_k = n-1$
is chosen with probability
 $\mathbb{P}(J_{n,n-1} = 1) = W_{n-1}/S_{n-1} = W_{\ell_k}/S_{k-1}$
. Since, conditioned on the blocks
$\mathbb{P}(J_{n,n-1} = 1) = W_{n-1}/S_{n-1} = W_{\ell_k}/S_{k-1}$
. Since, conditioned on the blocks
 $\boldsymbol{B}_0, \boldsymbol{B}_1, \ldots, \boldsymbol{B}_n$
, we have
$\boldsymbol{B}_0, \boldsymbol{B}_1, \ldots, \boldsymbol{B}_n$
, we have
 \begin{align*} \mathbb{P}(J_{n,\ell_k}=1, J_{n,\ell_k+1}=\cdots=J_{n,k-1}=0) & = \frac{W_{\ell_k}}{S_{\ell_k}}\prod_{k^{\prime}=\ell_k+1}^{k-1}\bigg(1 - \frac{W_{k^{\prime}}}{S_{k^{\prime}}}\bigg) \\ & = \frac{W_{\ell_k}}{S_\ell}\prod_{k^{\prime}={\ell_k}+1}^{k-1}\frac{S_{k^{\prime}-1}}{S_{k^{\prime}}} = \frac{W_{\ell_k}}{S_{k-1}}, \end{align*}
\begin{align*} \mathbb{P}(J_{n,\ell_k}=1, J_{n,\ell_k+1}=\cdots=J_{n,k-1}=0) & = \frac{W_{\ell_k}}{S_{\ell_k}}\prod_{k^{\prime}=\ell_k+1}^{k-1}\bigg(1 - \frac{W_{k^{\prime}}}{S_{k^{\prime}}}\bigg) \\ & = \frac{W_{\ell_k}}{S_\ell}\prod_{k^{\prime}={\ell_k}+1}^{k-1}\frac{S_{k^{\prime}-1}}{S_{k^{\prime}}} = \frac{W_{\ell_k}}{S_{k-1}}, \end{align*}
both (8) and (9) simplify to
 $W_{\ell_k}/S_{k-1}$
. Therefore, we have indeed constructed a sequence of random recursive metric spaces and, from the construction described, we see that
$W_{\ell_k}/S_{k-1}$
. Therefore, we have indeed constructed a sequence of random recursive metric spaces and, from the construction described, we see that
 $\Delta_n = D_n(H, v_n) \sim \sum_{k=0}^{n-1}Y_{n,k}$
.
$\Delta_n = D_n(H, v_n) \sim \sum_{k=0}^{n-1}Y_{n,k}$
.
We now introduce the martingales we will use to prove Theorem 1. For every
 $n\geq 1$
and
$n\geq 1$
and
 $k=0, \ldots, n-1$
, let
$k=0, \ldots, n-1$
, let
 $\mathcal{F}_{n,k}$
be the
$\mathcal{F}_{n,k}$
be the
 $\sigma$
-algebra generated by
$\sigma$
-algebra generated by
 $W_1, \ldots, W_k$
and all
$W_1, \ldots, W_k$
and all
 $Y_{m,\ell}$
defined for
$Y_{m,\ell}$
defined for
 $m \leq n$
,
$m \leq n$
,
 $\ell \leq k$
. Note that the filtrations
$\ell \leq k$
. Note that the filtrations
 $(\mathcal{F}_{n,k})_{k=0}^{n-1}$
are nested (that is,
$(\mathcal{F}_{n,k})_{k=0}^{n-1}$
are nested (that is,
 $\mathcal{F}_{n,k} \subseteq \mathcal{F}_{n+1, k}$
). Define
$\mathcal{F}_{n,k} \subseteq \mathcal{F}_{n+1, k}$
). Define
 \begin{equation*} M_{n,k} = \sum_{\ell=1}^k(Y_{n,\ell} - \mathbb{E}[Y_{n,\ell} \mid \mathcal{F}_{n,\ell-1}]), \qquad L_{n,k} = \sum_{\ell=1}^k{\mathbb{E}[Y_{n,\ell} \mid \mathcal{F}_{n,\ell-1}]},\end{equation*}
\begin{equation*} M_{n,k} = \sum_{\ell=1}^k(Y_{n,\ell} - \mathbb{E}[Y_{n,\ell} \mid \mathcal{F}_{n,\ell-1}]), \qquad L_{n,k} = \sum_{\ell=1}^k{\mathbb{E}[Y_{n,\ell} \mid \mathcal{F}_{n,\ell-1}]},\end{equation*}
so that
 $\sum_{\ell=0}^k Y_{n,\ell} = Y_{n,0} + M_{n,k} + L_{n,k}$
. Then, by Lemma 1,
$\sum_{\ell=0}^k Y_{n,\ell} = Y_{n,0} + M_{n,k} + L_{n,k}$
. Then, by Lemma 1,
 $\Delta_n \sim Y_{n,0} + M_{n,n-1} + L_{n,n-1}$
. We will apply a martingale central limit theorem, namely [Reference Hall and Heyde14, Corollary 3.1], to
$\Delta_n \sim Y_{n,0} + M_{n,n-1} + L_{n,n-1}$
. We will apply a martingale central limit theorem, namely [Reference Hall and Heyde14, Corollary 3.1], to
 $\{M_{n,k}, 1 \leq k < n, n \geq 2\}$
scaled by
$\{M_{n,k}, 1 \leq k < n, n \geq 2\}$
scaled by
 $\sqrt{\ln n}$
to prove Theorem 1. We begin with some useful calculations.
$\sqrt{\ln n}$
to prove Theorem 1. We begin with some useful calculations.
Lemma 2. Suppose that
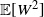 $\mathbb{E}[W^2]$
,
$\mathbb{E}[W^2]$
,
 $\mathbb{E}[(W\Delta^{\prime})^2]$
, and
$\mathbb{E}[(W\Delta^{\prime})^2]$
, and
 $\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
are all finite. Then, for almost every sequence
$\mathbb{E}\big[W(\Delta^{\prime})^2\big]$
are all finite. Then, for almost every sequence
 $\boldsymbol{B}_0, \boldsymbol{B}_1, \boldsymbol{B}_2, \ldots$
of blocks, the following hold:
$\boldsymbol{B}_0, \boldsymbol{B}_1, \boldsymbol{B}_2, \ldots$
of blocks, the following hold:
 \begin{align} {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]} & = \frac{\mathbb{E}[W\Delta^{\prime}]}{k\mathbb{E}[W]} + O(k^{-2}), \end{align}
\begin{align} {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]} & = \frac{\mathbb{E}[W\Delta^{\prime}]}{k\mathbb{E}[W]} + O(k^{-2}), \end{align}
 \begin{align} \mathbb{E}[(Y_{n,k} - \mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}])^2 \mid \mathcal{F}_{n,k-1}] & = \frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{k\mathbb{E}[W]} + O(k^{-2}), \end{align}
\begin{align} \mathbb{E}[(Y_{n,k} - \mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}])^2 \mid \mathcal{F}_{n,k-1}] & = \frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{k\mathbb{E}[W]} + O(k^{-2}), \end{align}
 \begin{align} \mathbb{E}[Y_{n,k}^2\boldsymbol{1}_{\{Y_{n,k} > c\}} \mid \mathcal{F}_{n,k-1}] & = \frac{\mathbb{E}[W(\Delta^{\prime})^2\boldsymbol{1}_{\{\Delta^{\prime} > c\}}]}{k\mathbb{E}[W]} + O(k^{-2}), \quad c > 0. \end{align}
\begin{align} \mathbb{E}[Y_{n,k}^2\boldsymbol{1}_{\{Y_{n,k} > c\}} \mid \mathcal{F}_{n,k-1}] & = \frac{\mathbb{E}[W(\Delta^{\prime})^2\boldsymbol{1}_{\{\Delta^{\prime} > c\}}]}{k\mathbb{E}[W]} + O(k^{-2}), \quad c > 0. \end{align}
Proof. Throughout this argument we use that for almost every sequence
 $W_1, W_2, \ldots$
of weights,
$W_1, W_2, \ldots$
of weights,
 $S_k = k\mathbb{E}[W] + o(k^{3/4})$
. This is guaranteed, for example, by the law of the iterated logarithm, since the
$S_k = k\mathbb{E}[W] + o(k^{3/4})$
. This is guaranteed, for example, by the law of the iterated logarithm, since the
 $W_i$
are i.i.d. and have finite variances. Also note that given our conditions
$W_i$
are i.i.d. and have finite variances. Also note that given our conditions
 $\mathbb{E}[W^2] < \infty$
and
$\mathbb{E}[W^2] < \infty$
and
 $\mathbb{E}[(W\Delta^{\prime})^2] < \infty$
, since W and
$\mathbb{E}[(W\Delta^{\prime})^2] < \infty$
, since W and
 $\Delta^{\prime}$
are nonnegative, we also have
$\Delta^{\prime}$
are nonnegative, we also have
 \begin{equation*} \mathbb{E}[W^2\Delta^{\prime}] = \mathbb{E}[W^2\Delta^{\prime}\boldsymbol{1}_{\{\Delta^{\prime} \leq 1\}}] + \mathbb{E}[W^2\Delta^{\prime}\boldsymbol{1}_{\{\Delta^{\prime} > 1\}}] \leq \mathbb{E}[W^2] + \mathbb{E}[(W\Delta^{\prime})^2] < \infty. \end{equation*}
\begin{equation*} \mathbb{E}[W^2\Delta^{\prime}] = \mathbb{E}[W^2\Delta^{\prime}\boldsymbol{1}_{\{\Delta^{\prime} \leq 1\}}] + \mathbb{E}[W^2\Delta^{\prime}\boldsymbol{1}_{\{\Delta^{\prime} > 1\}}] \leq \mathbb{E}[W^2] + \mathbb{E}[(W\Delta^{\prime})^2] < \infty. \end{equation*}
Define
 $\mathcal{F}_{n,k-1}^\ast = \sigma\big(\mathcal{F}_{n,k-1} \cup \sigma\big(W_k, \Delta^{\prime}_{n,k}\big)\big)$
. Then
$\mathcal{F}_{n,k-1}^\ast = \sigma\big(\mathcal{F}_{n,k-1} \cup \sigma\big(W_k, \Delta^{\prime}_{n,k}\big)\big)$
. Then
 \begin{equation*} {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}^\ast]} = \frac{W_k}{S_{k-1} + W_k}\Delta^{\prime}_{n,k} = \Delta^{\prime}_{n,k} \bigg(\frac{W_k}{S_{k-1}} - \frac{W_k^2}{S_{k-1}^2 + S_{k-1}W_k}\bigg). \end{equation*}
\begin{equation*} {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}^\ast]} = \frac{W_k}{S_{k-1} + W_k}\Delta^{\prime}_{n,k} = \Delta^{\prime}_{n,k} \bigg(\frac{W_k}{S_{k-1}} - \frac{W_k^2}{S_{k-1}^2 + S_{k-1}W_k}\bigg). \end{equation*}
Since
 $S_{k-1}$
and
$S_{k-1}$
and
 $W_k$
are nonnegative, the second term in the parentheses above is bounded by
$W_k$
are nonnegative, the second term in the parentheses above is bounded by
 $W_k^2S_{k-1}^{-2}$
. From our approximation for
$W_k^2S_{k-1}^{-2}$
. From our approximation for
 $S_k$
and since
$S_k$
and since
 $\mathbb{E}[W^2\Delta^{\prime}]< \infty$
, applying the tower rule yields that, almost surely,
$\mathbb{E}[W^2\Delta^{\prime}]< \infty$
, applying the tower rule yields that, almost surely,
 \begin{equation*} {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]} = {\mathbb{E}[{\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}^\ast]} \mid \mathcal{F}_{n,{k-1}}]} = \frac{\mathbb{E}[W\Delta^{\prime}]}{k\mathbb{E}[W]} + O(k^{-2}), \end{equation*}
\begin{equation*} {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]} = {\mathbb{E}[{\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}^\ast]} \mid \mathcal{F}_{n,{k-1}}]} = \frac{\mathbb{E}[W\Delta^{\prime}]}{k\mathbb{E}[W]} + O(k^{-2}), \end{equation*}
which is (10). Similarly, we have the conditional expectation
 \begin{equation*} {\mathbb{E}[Y_{n,k}^2 \mid \mathcal{F}_{n,k-1}^\ast]} = \frac{W_k}{S_{k-1} + W_k}\big(\Delta^{\prime}_{n,k}\big)^2, \end{equation*}
\begin{equation*} {\mathbb{E}[Y_{n,k}^2 \mid \mathcal{F}_{n,k-1}^\ast]} = \frac{W_k}{S_{k-1} + W_k}\big(\Delta^{\prime}_{n,k}\big)^2, \end{equation*}
and from our approximation for
 $S_k$
and the assumption
$S_k$
and the assumption
 $\mathbb{E}[(W\Delta^{\prime})^2] < \infty$
, applying the tower rule yields that, almost surely,
$\mathbb{E}[(W\Delta^{\prime})^2] < \infty$
, applying the tower rule yields that, almost surely,
 \begin{equation*} {\mathbb{E}[Y_{n,k}^2 \mid \mathcal{F}_{n,{k-1}}]} = \frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{k\mathbb{E}[W]} + O(k^{-2}). \end{equation*}
\begin{equation*} {\mathbb{E}[Y_{n,k}^2 \mid \mathcal{F}_{n,{k-1}}]} = \frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{k\mathbb{E}[W]} + O(k^{-2}). \end{equation*}
Subtracting
 $({\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,{k-1}}]})^2 = O(k^{-2})$
from the equation above yields (11). Finally, note that
$({\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,{k-1}}]})^2 = O(k^{-2})$
from the equation above yields (11). Finally, note that
 $Y_{n,k} > c$
if and only if
$Y_{n,k} > c$
if and only if
 $J_{n,k} = 1$
and
$J_{n,k} = 1$
and
 $\Delta^{\prime}_{n,k} > c$
. Thus,
$\Delta^{\prime}_{n,k} > c$
. Thus,
 \begin{equation*} {\mathbb{E}\big[Y_{n,k}^2\boldsymbol{1}_{\{Y_{n,k} > c\}} \mid \mathcal{F}^\ast_{n,k-1}\big]} = \frac{W_k}{S_{k-1} + W_k}\big(\Delta^{\prime}_{n,k}\big)^2\boldsymbol{1}_{\big\{\Delta^{\prime}_{n,k} > c\big\}}. \end{equation*}
\begin{equation*} {\mathbb{E}\big[Y_{n,k}^2\boldsymbol{1}_{\{Y_{n,k} > c\}} \mid \mathcal{F}^\ast_{n,k-1}\big]} = \frac{W_k}{S_{k-1} + W_k}\big(\Delta^{\prime}_{n,k}\big)^2\boldsymbol{1}_{\big\{\Delta^{\prime}_{n,k} > c\big\}}. \end{equation*}
Using the tower rule once more provides that (12) holds almost surely.
We are now ready to prove the main theorem of this work.
Proof of Theorem 1. We start by proving that
 $\{(\ln n)^{-1/2}M_{n,k}, 1 \leq k < n, n \geq 2\}$
satisfies the conditions necessary to apply [Reference Hall and Heyde14, Corollary 3.1]. Note that
$\{(\ln n)^{-1/2}M_{n,k}, 1 \leq k < n, n \geq 2\}$
satisfies the conditions necessary to apply [Reference Hall and Heyde14, Corollary 3.1]. Note that
 \begin{equation} M_{n,k} - M_{n,k-1} = Y_{n,k} - {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]}. \end{equation}
\begin{equation} M_{n,k} - M_{n,k-1} = Y_{n,k} - {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]}. \end{equation}
We see immediately that
 $\mathbb{E}[M_{n,k}] = 0$
, and from (13) we have
$\mathbb{E}[M_{n,k}] = 0$
, and from (13) we have
 \begin{equation*}{\mathbb{E}[M_{n,k} - M_{n,k-1} \mid \mathcal{F}_{n,k-1}]} = 0.\end{equation*}
\begin{equation*}{\mathbb{E}[M_{n,k} - M_{n,k-1} \mid \mathcal{F}_{n,k-1}]} = 0.\end{equation*}
From the moment conditions stated in Theorem 1, we also have
 $\mathbb{E}[M_{n,k}^2] < \infty$
for all n and k. Thus,
$\mathbb{E}[M_{n,k}^2] < \infty$
for all n and k. Thus,
 $\{(\ln n)^{-1/2}M_{n,k}, 1 \leq k < n, n \geq 2\}$
is a zero-mean square-integrable martingale array.
$\{(\ln n)^{-1/2}M_{n,k}, 1 \leq k < n, n \geq 2\}$
is a zero-mean square-integrable martingale array.
For the conditional variance, we conclude from (11) and (13) that, almost surely,
 \begin{align*} \sum_{k=2}^{n-1}{\mathbb{E}[(M_{n,k} - M_{n,k-1})^2 \mid \mathcal{F}_{n,k-1}]} & = \sum_{k=2}^{n-1}{\mathbb{E}[(Y_{n,k} - {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]})^2 \mid \mathcal{F}_{n,k-1}]} \\ & = \frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]} \ln n + O(1). \end{align*}
\begin{align*} \sum_{k=2}^{n-1}{\mathbb{E}[(M_{n,k} - M_{n,k-1})^2 \mid \mathcal{F}_{n,k-1}]} & = \sum_{k=2}^{n-1}{\mathbb{E}[(Y_{n,k} - {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]})^2 \mid \mathcal{F}_{n,k-1}]} \\ & = \frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]} \ln n + O(1). \end{align*}
Therefore,
 \begin{equation*} \sum_{k=2}^{n-1}{\mathbb{E}\bigg[\bigg(\frac{M_{n,k} - M_{n,k-1}}{\sqrt{\ln n}}\bigg)^2 \mid \mathcal{F}_{n,k-1}\bigg]} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}. \end{equation*}
\begin{equation*} \sum_{k=2}^{n-1}{\mathbb{E}\bigg[\bigg(\frac{M_{n,k} - M_{n,k-1}}{\sqrt{\ln n}}\bigg)^2 \mid \mathcal{F}_{n,k-1}\bigg]} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}. \end{equation*}
As for the conditional Lindeberg condition, we start by noting that, for any
 $c>0$
, (10) guarantees that, almost surely, for large enough k we have
$c>0$
, (10) guarantees that, almost surely, for large enough k we have
 ${\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]} < c$
. Thus, almost surely, for large enough k,
${\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]} < c$
. Thus, almost surely, for large enough k,
 $\lvert Y_{n,k} - {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]}\rvert > c$
implies that
$\lvert Y_{n,k} - {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]}\rvert > c$
implies that
 $Y_{n,k} > c $
and that
$Y_{n,k} > c $
and that
 $(Y_{n,k} - {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]})^2 < Y_{n,k}^2$
. Thus, from (12) and (13), almost surely,
$(Y_{n,k} - {\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]})^2 < Y_{n,k}^2$
. Thus, from (12) and (13), almost surely,
 \begin{align*} \sum_{k=2}^{n-1}{\mathbb{E}[(M_{n,k} - M_{n,k-1})^2\boldsymbol{1}_{\{|M_{n,k} - M_{n,k-1}| > c\}} \mid \mathcal{F}_{n,k-1}]} & < \sum_{k=2}^{n-1}{\mathbb{E}[Y_{n,k}^2\boldsymbol{1}_{\{Y_{n,k} > c\}} \mid \mathcal{F}_{n,k-1}]} \\ & = \frac{\mathbb{E}[W(\Delta^{\prime})^2\boldsymbol{1}_{\{\Delta^{\prime} > c\}}]}{\mathbb{E}[W]}\ln n + O(1). \end{align*}
\begin{align*} \sum_{k=2}^{n-1}{\mathbb{E}[(M_{n,k} - M_{n,k-1})^2\boldsymbol{1}_{\{|M_{n,k} - M_{n,k-1}| > c\}} \mid \mathcal{F}_{n,k-1}]} & < \sum_{k=2}^{n-1}{\mathbb{E}[Y_{n,k}^2\boldsymbol{1}_{\{Y_{n,k} > c\}} \mid \mathcal{F}_{n,k-1}]} \\ & = \frac{\mathbb{E}[W(\Delta^{\prime})^2\boldsymbol{1}_{\{\Delta^{\prime} > c\}}]}{\mathbb{E}[W]}\ln n + O(1). \end{align*}
For any
 $\varepsilon > 0$
, since
$\varepsilon > 0$
, since
 $\mathbb{E}\big[W(\Delta^{\prime})^2\big] < \infty$
, we have
$\mathbb{E}\big[W(\Delta^{\prime})^2\big] < \infty$
, we have
 $\mathbb{E}[W(\Delta^{\prime})^2\boldsymbol{1}_{\{\Delta^{\prime} > \varepsilon \sqrt{\ln n}\}}] \to 0$
. Thus,
$\mathbb{E}[W(\Delta^{\prime})^2\boldsymbol{1}_{\{\Delta^{\prime} > \varepsilon \sqrt{\ln n}\}}] \to 0$
. Thus,
 \begin{equation*} \sum_{k=2}^{n-1}{\mathbb{E}\bigg[\bigg(\frac{M_{n,k} - M_{n,k-1}}{\sqrt{\ln n}}\bigg)^2 \boldsymbol{1}_{\{|M_{n,k} - M_{n,k-1}| > \varepsilon \sqrt{\ln n}\}} \mid \mathcal{F}_{n,k-1}\bigg]} \xrightarrow{\mathrm{p}} 0. \end{equation*}
\begin{equation*} \sum_{k=2}^{n-1}{\mathbb{E}\bigg[\bigg(\frac{M_{n,k} - M_{n,k-1}}{\sqrt{\ln n}}\bigg)^2 \boldsymbol{1}_{\{|M_{n,k} - M_{n,k-1}| > \varepsilon \sqrt{\ln n}\}} \mid \mathcal{F}_{n,k-1}\bigg]} \xrightarrow{\mathrm{p}} 0. \end{equation*}
All the conditions of [Reference Hall and Heyde14, Corollary 3.1] are satisfied, and so
 \begin{equation} \frac{M_{n,n-1}}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}\bigg). \end{equation}
\begin{equation} \frac{M_{n,n-1}}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}\bigg). \end{equation}
By applying (10), we have, almost surely,
 \begin{equation} L_{n,n-1} = \sum_{k=1}^{n-1}{\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]} = \frac{\mathbb{E}[W\Delta^{\prime}]}{\mathbb{E}[W]}\ln n + O(1). \end{equation}
\begin{equation} L_{n,n-1} = \sum_{k=1}^{n-1}{\mathbb{E}[Y_{n,k} \mid \mathcal{F}_{n,k-1}]} = \frac{\mathbb{E}[W\Delta^{\prime}]}{\mathbb{E}[W]}\ln n + O(1). \end{equation}
Since
 $\Delta_n \sim Y_{n,0} + M_{n,n-1} + L_{n,n-1}$
, we can conclude from (14) and (15) the central limit theorem
$\Delta_n \sim Y_{n,0} + M_{n,n-1} + L_{n,n-1}$
, we can conclude from (14) and (15) the central limit theorem
 \begin{equation*} \frac{\Delta_n - \mathbb{E}[W]^{-1}\mathbb{E}[W\Delta^{\prime}]}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}\bigg). \end{equation*}
\begin{equation*} \frac{\Delta_n - \mathbb{E}[W]^{-1}\mathbb{E}[W\Delta^{\prime}]}{\sqrt{\ln n}} \xrightarrow{\mathrm{d}} \mathcal{N}\bigg(0,\frac{\mathbb{E}\big[W(\Delta^{\prime})^2\big]}{\mathbb{E}[W]}\bigg). \end{equation*}
As for the weak law of large numbers, we have
 $M_{n,n-1}/\ln n \xrightarrow{\mathrm{d}} 0$
from (14) and Slutsky’s theorem. Since we have convergence in distribution to a constant, the convergence holds in probability as well. From (15), we can conclude that
$M_{n,n-1}/\ln n \xrightarrow{\mathrm{d}} 0$
from (14) and Slutsky’s theorem. Since we have convergence in distribution to a constant, the convergence holds in probability as well. From (15), we can conclude that
 $L_{n,n-1}/\ln n \xrightarrow{\mathrm{p}} \mathbb{E}[W]^{-1}\mathbb{E}[W\Delta^{\prime}]$
, and so
$L_{n,n-1}/\ln n \xrightarrow{\mathrm{p}} \mathbb{E}[W]^{-1}\mathbb{E}[W\Delta^{\prime}]$
, and so
 \begin{equation*} \frac{\Delta_n}{\ln n} = \frac{Y_{n,0} + M_{n,n-1} + L_{n,n-1}}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}[W\Delta^{\prime}]}{\mathbb{E}[W]}. \end{equation*}
\begin{equation*} \frac{\Delta_n}{\ln n} = \frac{Y_{n,0} + M_{n,n-1} + L_{n,n-1}}{\ln n} \xrightarrow{\mathrm{p}} \frac{\mathbb{E}[W\Delta^{\prime}]}{\mathbb{E}[W]}. \end{equation*}
Acknowledgements
The author would like to thank the referees for their comments in improving the presentation of this work, and in particular, an anonymous referee for suggesting the martingale approach for the proof of Theorem 1. The author would also like to thank Svante Janson for valuable and helpful discussions in the preparation of this work. This work was partially completed while the author was a PhD student at Uppsala University.
Funding information
There are no funding bodies to thank relating to the creation of this article.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.

 Open access
Open access