


INTRODUCTION
Different languages dispose of various cues that contribute to the determination of word-class information. While in highly inflected languages like Czech or Russian specific word-class endings can differentiate, for example, between a noun (barv-a – “color”) and a verb (barv-í – “he/she/it colors”), in languages with limited inflection like English it is primarily the syntactic context that has this function (I like the color vs. we will color it later). German disposes of more inflection than English, but it still comprises more grammatically ambiguous forms than the highly inflected Czech. The word form MIETEN can, for instance, be a verbal form in infinitive or in first- or third-person plural (“we/they rent”), or it can be a nominal form that means either “renting” (a noun derived from a verb using a process called conversion) or “rents” (a countable noun in plural). In spoken German, there is no way to determine whether a verbal or a nominal meaning is intended if the word is presented in isolation. However, in the written mode, German uses capitalization of the first letter as a cue for nouns, that is, das Mieten (“the renting”) and die Mieten (“the rents”). Such orthographic word-class marking does not exist in Czech.
Capitalization of the initial letter of nouns is a unique property of the German writing system. It is assumed to help the reader to syntactically analyze a sentence by visually highlighting the argument(s) as opposed to the predicate of the proposition (Sahel et al., Reference Sahel, Weingarten, Gutbrod and Cummins2003). Previous research has shown that reading of German texts with capitalized nouns is easier than reading texts with deviations from standard German orthography. Empirical evidence in L1 German is provided by several studies by Bock and colleagues (Reference Bock, August, Wagner and August1985, Reference Bock and August1986, Reference Bock1989), in which they varied orthography in several ways. In their 1985 experiments, they manipulated the orthography of short texts by omitting the capitalization of nouns, capitalizing initial letters of all words, randomly capitalizing initial letters of various words or inverting the existing capitalization rules so that the initial letters of all nonnouns were capitalized. The results revealed that infringements of the capitalization rules slowed the reading rate by 4.5%, 11.23%, 12.2%, and 19.08%, respectively. In their follow-up experiments, the authors also manipulated capitalization in languages that normally do not use it as a cue for word-class information (Bock, Reference Bock1989). The aim was to rule out the hypothesis that the slower reading rates of texts violating the German capitalization rules are solely due to recognition difficulties when identifying unaccustomed word shapes.
For the present study that addresses the role of orthographic cues (capitalization) in L1 and L2 lexical access, the study of Bock (Reference Bock1989) is particularly relevant because it was the first to include the role of capitalization in German as an L2. German participants were asked to read German and English texts, and Dutch participants were asked to read Dutch and German texts. The texts were again presented in standard German spelling and in the four manipulated versions described in the preceding text. Significantly, capitalizing English nouns according to German capitalization rules did not lead to slower reading rates compared to reading rates of standard English spelling. This means that German readers were able to transfer German capitalization rules to the English texts, so that the unaccustomed word shapes of the capitalized English nouns did not delay the reading rate. Even more interestingly, Dutch participants were able to transfer the German capitalization rules from their L2 German to their L1 Dutch and read the Dutch texts written according to German spelling rules (i.e., with capitalized nouns) even faster than texts written according to standard Dutch spelling rules (i.e., without capitalization of nouns). These results demonstrate that the capitalization rules have a function of their own that is independent of stored written word shapes.
THE PRESENT STUDY
In the current study, we explore how the processing of grammatically ambiguous forms in sentential context is affected by noun capitalization in L1 and L2 German. Compared to previous studies, we are not concerned with the general role of noun capitalization on reading speed, but specifically with its function in potentially facilitating access to the intended (in terms of word class) target representation. This question gains additional importance when exploring processing of German as an L2 of learners whose L1 (Czech) does not use capitalization to mark word classes, as it can shed new light on the question to which degree L2 learners are able to make use of linguistic cues that do not exist in their L1. For these purposes, we compare the results of a previous study (Bordag & Opitz, Reference Bordag and Opitz2021) also with L1 and L2 German, in which capitalization cues were avoided by presenting all critical stimuli in capital letters (e.g., MIETEN), with the present study, in which all items were presented according to standard spelling, that is, with capitalized nouns.
It is important to note that native German speakers are confronted with both types of input, that is, with present or absent capitalization cues in natural contexts. When they read standard German texts, all nouns are capitalized; when they hear spoken language, orthographic word class cues are indeed absent. Similarly, they regularly encounter texts that are entirely or partially capitalized, such as headlines or advertisements. Moreover, when young children learn to read and write, they typically use only capital letters at first, and some children’s books contain text written only in capital letters. Although such word forms may seem less common to adult speakers, they do exist in everyday text.
Our study focuses on the processing of five homonymous word forms in German that were investigated in a previous study (Bordag & Opitz, Reference Bordag and Opitz2021). These forms are based on the same roots that are combined with formally the same ending (-en) which carries different morphological functions. Depending on the syntactic context, one word form (e.g., MIETEN) subsumes different grammatical functions: It can be the infinitive of the verb, for example, “to rent” (MIETEN/mieten), a verb form inflected for first-person plural or third-person plural (MIETEN/mieten “we/they rent”), a verbal noun derived from the verb (MIETEN/Mieten “the renting”), or dative plural of a semantically related countable noun (MIETEN/Mieten “[with the] rents”). All these identical forms are semantically closely related as they go back to the same root (MIET) and also contain formally the same ending (-en). It is thus typically the syntactic context that offers reliable cues for disambiguation.Footnote 1 However, capitalization adds an additional cue that can restrict the set of target representations depending on their word class.
Previous studies addressing the ambiguity of homophones/homographs (see Simpson & Burgess, Reference Simpson and Burgess1985 and Hillert, Reference Hillert and Stamenov1997 for reviews) focused on the lexical level, that is, they explored morphologically simple lexical units with more than one meaning (e.g., bank). Their results indicate that all meanings of an ambiguous word are initially retrieved, and the target meaning is selected only later based on sentential context. The present study, however, explores morphologically complex homonymous word forms. Their representation has been addressed to much lesser degree and there is no agreement how these forms are represented in the mental lexicon. In addition, our research centers around the conversion noun forms, that is, deverbal nouns that are derived from verbs in a productive and regular way in German and whose representation status remains unclear. There are several approaches that propose how conversion or zero-derivation should be modeled, ranging from the proposal that the verb and the conversion noun have separate lexical entries, each specified for one word class (Don, Reference Don2005; Plank, Reference Plank2010) up to the proposal that conversion is only a process similar to inflection that converts one word class into another (Stolterfoht et al., Reference Stolterfoht, Gese and Maienborn2010). In our previous work (Bordag & Opitz, Reference Bordag and Opitz2021; Opitz & Bordag, Reference Opitz and Bordag2020), we delivered evidence against these two antipodal approaches and explored in particular the hypotheses assuming that parts of the representations are shared (e.g., Bauer & Valera, Reference Bauer, Valera, Bauer and Valera2005), which are best compatible with our results both in L1 and L2 German. Our previous research further indicated that conversion nouns and infinitives may fall into the same category of nonfinites (Haspelmath, Reference Haspelmath, Booij and van Marle1996) because they manifested the same pattern of results that was different from both inflected verbal forms and countable nouns (see more in the following text). One purpose of the present study is to investigate whether the involvement of the capitalization reveals additional information about the representation of conversion in L1 German and whether the representation is the same n the L2 German of advanced learners in whose L1 neither conversion nor such orthographic cues exist.
In parallel to the previous study, we employ a visual priming paradigm to explore lexical access to these grammatically ambiguous forms in German as a native language and in German as a second language of Czech native speakers. Crucially, the former study avoided all orthographic cues by representing the critical forms in capital letters (MIETEN), whereas the representation of the critical forms in the current study conforms to standard German spelling and thus provides an additional word-class clue (Mieten(N) vs. mieten(V)).
In the next paragraphs, we briefly summarize the design and results of the previous study and then focus on the differences between the previous and the two new experiments that involve capitalization.
The six original priming conditions in Bordag and Opitz (Reference Bordag and Opitz2021) and the spelling modifications applied in the present study are summarized in Table 1.
TABLE 1. Experimental conditions and examples of prime and target phrases in Bordag and Opitz (Reference Bordag and Opitz2021) (abbreviated as B&O [2021] and in the present study (highlighted in boldface)
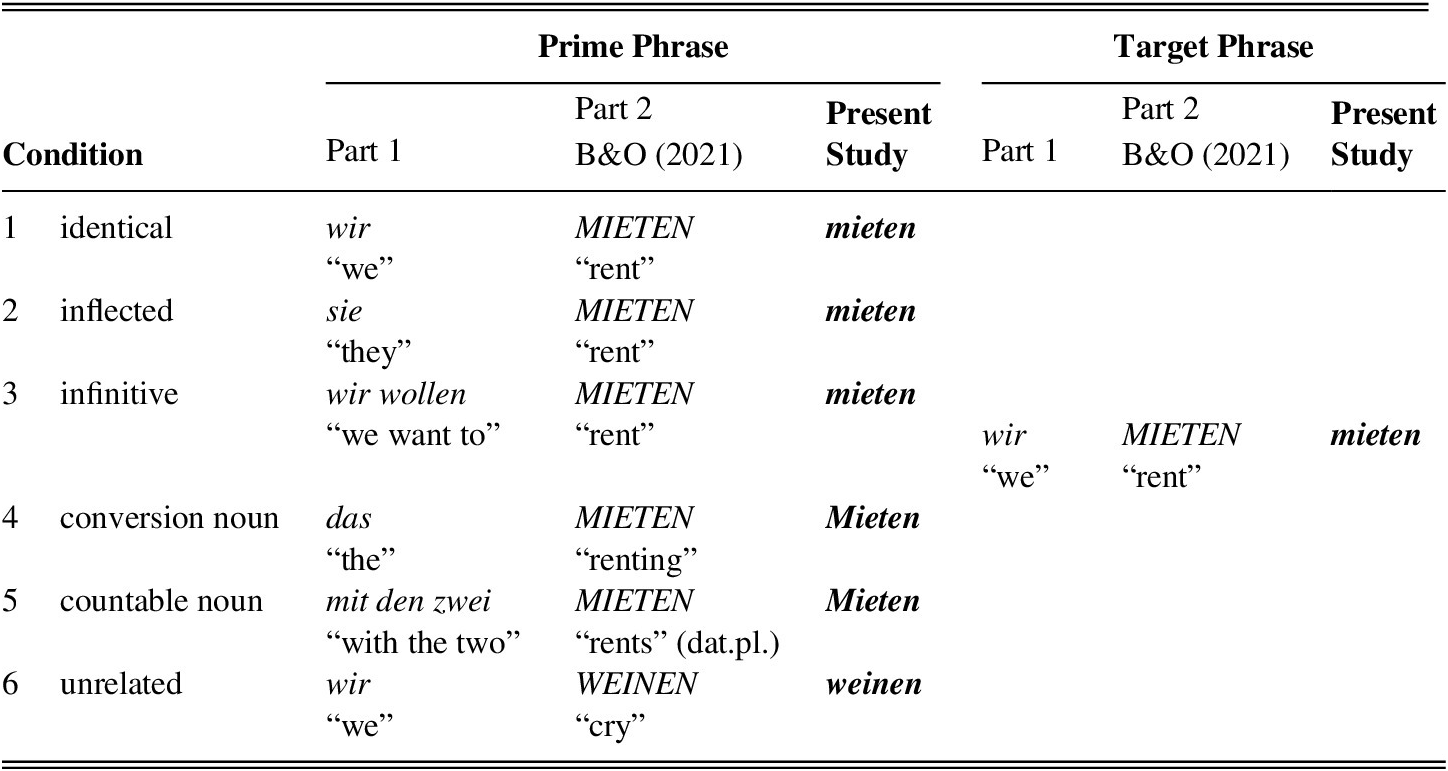
In all six conditions, the target always is the first-person-plural form of a given verb (e.g., wir MIETEN “we rent”). The six conditions differ from each other in that in the first three conditions (1–3), the prime is a verb form too, namely first-person plural, third-person plural, and an infinitive form, respectively. In conditions 4 and 5, primes are nouns. In the conversion condition, it is a noun converted from the corresponding verb; in the countable-noun condition it is a related noun in dative plural with the same root as the target verb. The functions of the individual, formally identical forms are determined by the preceding syntactic context (Part 1 in Table 1). In the unrelated condition, the prime is an unrelated verb in first-person plural.
The results of Bordag and Opitz (Reference Bordag and Opitz2021) revealed no evidence of fundamental differences between L1 and L2 participants with respect to processing and representation of the five forms. In particular, the pattern of the priming effects was the same in both populations: Full priming was observed in the identical (1) and inflected conditions (2), partial priming (of equal size) in the infinitive (3) and conversion condition (4), and no priming in the countable-noun condition (5).
The full priming in the identical and inflected condition is explained through access to the same subentries using a basic entry. The partial priming in the infinitive and conversion condition complies with typological approaches that recognise a special class of nonfinites (comprising infinitives, deverbal nouns, participles, and converbs) characterized by displaying both verbal and nominal properties (see Ylikoski, Reference Ylikoski2003, for an overview). The results indicate that conversion nouns and infinitives have their own subentries within the basic lexical entry, so that there is no complete overlap between the representation accessed at the prime (conversion or infinitive) and at the target (finite verb) presentation, which results in only partial priming. Observing no priming in the countable-noun condition agrees with previous studies focusing on the differences between inflection and derivation that revealed no or only partial priming for derived forms both in L1 and L2 (e.g., Feldman, Reference Feldman1994; Julínková & Bordag, Reference Julínková and Bordag2015; Laudanna et al., Reference Laudanna, Badecker and Caramazza1992; Schriefers et al., Reference Schriefers, Friederici and Graetz1992).
In the current study, the design of the experiments was identical, but all words were spelled according to standard German spelling rules, that is, with lowercase first letter in the verbal prime conditions and as targets, for example, mieten and with uppercase letter in the noun prime conditions, for example, Mieten. We expected that while L1 speakers might use the orthographic cue for word-class disambiguation and thus accessing the word-class-specific subnode of conversion nouns, the advanced Czech learners of German might have restricted abilities to do so because no such cues exist in their native language.
METHODS
The design completely paralleled the experiments reported in Bordag and Opitz (Reference Bordag and Opitz2021). Procedures and materials were identical (except for orthographic cues). To also match participants’ characteristics as closely as possible, they were recruited from the same populations, but they were not identical in the two studies.
Participants
Experiment 1
A total of 72 participants were tested. All were German native speakers, aged 18 to 46 years (25.1 years on average). Sixteen were male, 56 female, and most were students at Leipzig University.
Experiment 2
Seventy-two native Czech speakers participated, with their ages ranging between 18 and 45 years (25.5 years on average). Thirteen of them were male, 59 were female. They were all students at Charles University in Prague.
To assess language proficiency of the nonnative participants, they were tested prior to the experimental session and three different measures were obtained: a shortened version of the Goethe Test, an online version of DiaLang,Footnote 2 and a self-evaluation of each participant (language-skill questionnaire). Nonnative participants were excluded from the experiment if they did not reach levels B2 and C1 according to the Common European Framework of Reference for Languages (CEFR) in at least two of the three assessments.
Materials
The same 24 German verbs as in the previous study were selected that have homophone noun counterparts referring to countable objects, for example, mieten “to rent” (verb), Mieten “rents” (noun, pl.). Both the verbs and their countable-noun counterparts were carefully selected. They had average or high frequency (frequency class 7-17 according to Leipzig Wortschatz ProjektFootnote 3 ) and were well known to L2 learners at B2 level (assessed in a pretest). Because the number of such verbs in German is rather limited, it was not possible to control exactly the relative frequencies of the verbal and the corresponding nominal forms. Nevertheless, for roughly half the items the nominal forms were more frequent and for the other half the verbal counterparts were more frequent. (For more details on material selection, see Bordag and Opitz [2021].)
All target phrases had an identical structure. Each contained a verb that was embedded in a short phrase and thereby unambiguously marked for its grammatical function: the pronoun wir (“we”) and the corresponding verb form inflected for first-person plural, for example, mieten. Contrary to the experiments reported in the previous study, target verb forms were presented in lower case according to standard German spelling.
All prime phrases also consisted of two parts. The second part of the primes was always a form that was homophone to the verb form of the target phrase. In contrast to the former study, all prime forms were written according to standard German spelling, that is, either in lowercase (verbs), or with initial capital letter (nouns) (cf. Table 1).Footnote 4
Randomization and distribution of items over six experimental lists was parallel to those in the previous study such that all six conditions were represented equally often and counterbalanced across the lists. All critical items consisted of pairs (prime and target) of grammatically correct phrases.
In addition, a large number of fillers was included in each list to balance the number and distributional probabilities of nouns and verbs, grammatical/ungrammatical forms, and the use of pronouns.
The filler items comprised 160 pairs of prime-target phrases (i.e., 2*160 phrases) that paralleled in their structure the critical items but that were systematically varied regarding the grammaticality of the prime and/or target (by means of number, gender, and/or case mismatches for ungrammatical fillers, e.g., sie FEHLEN – wir müssen FEHLST “they are absent – we have to be *absent”), as well as whether they included a verb or noun as their second part. Further 240 single, nonpaired filler phrases (e.g., *das große KATZE- “theneuter big catfeminine”) were included (134 verbs, 106 nouns) so that factors grammaticality, words class, and number were completely cross-balanced for each participant.
In sum, each of the six experimental lists comprised 608 single judgment tasks: 48 of them belonging to critical trials (24 prime + 24 target phrases), 560 to fillers (160 × 2 paired filler phrases, 240 single filler phrases).
Procedure
Participants received a small monetary reward for their participation. After they gave their informed consent, they were tested individually. They were instructed to perform the grammaticality judgment task as fast and as accurately as possible. All stimuli were presented visually, using the E-Prime 2.0 software (Psychology Software Tools, Pittsburgh, PA).
A fixation sign (*) presented at the center of the screen for 500 m started each trial before a phrase was displayed in two stages. In the first stage, the first part of the phrase, that is, all material preceding the verb or noun, was presented centered on the screen (e.g., wir wollen “we want to”). After 750 ms, these words disappeared and the second part of the phrase (e.g., mieten “rent”) was presented. Participants performed their judgment by pressing one of two corresponding buttons as soon as they saw the second part of the phrase. When response was registered or after a maximum duration of 2,000 ms, the word disappeared from the screen. A 600 ms ISI (blank screen) intervened between trials. Three breaks interspersed the experiment in equidistant intervals. Prior to the testing phase, a short training block of eight trials was administered to familiarize participants with the task. An average experimental session lasted about 35 (L1) and 45 (L2) minutes.
For each participant, the order of items was pseudorandomized with the following restrictions: a maximum of five successive trials with the same grammaticality (grammatical/ungrammatical) or the same word class of the second part of the phrase (noun/verb) were allowed. Furthermore, at least eight filler trials intervened between critical trials, and the first three trials after each of the breaks were filler trials.
RESULTS
Data preparation
For maximum comparability, all statistical procedures (including types of analyses, applied methods, definition of outliers, etc.) were identical to those reported for the experiments in Bordag and Opitz (Reference Bordag and Opitz2021). Thus, data of the L1 and L2 participants were pooled, and all statistical analyses comprise a factor Language referring to the two groups of participants (L1 or L2).Footnote 5
The focus of the analyses was on the reaction times for the target verb forms, which were always presented in the same syntactic context (wir “we”) and were therefore equally easy to process in all conditions. The rationale was that any observed differences for RTs at the targets can be clearly ascribed to the influence of the preceding prime. Both targets with incorrect responses and targets to whose corresponding primes participants responded incorrectly were excluded from analyses of reaction times, leading to the exclusion of 7.84% of the data (271 out of 3456 total trials).
Analyses
The software R (R Core Team, 2021) was employed for all statistical analyses. Inferential tests were performed using linear mixed-effect models with package lme4 (Bates et al., Reference Bates, Maechler, Bolker and Walker2015) and emmeans (Lenth, Reference Lenth2020). Prime Condition and Language were set as fixed effects. To compensate for the lack of a normal distribution, raw data were log-transformed prior to analyses. Data were additionally winsorized with a 98% criterionFootnote 6 for each participant to reduce the impact of outliers. Fixed effects were tested for significance by model comparisons employing package lmerTest (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). Denominator degrees of freedom for F-tests were computed according to Satterthwaite and Kenward–Roger methods. All models included random intercepts for participants and items. Because no models that also included random slopes converged, a model with only random intercepts was considered as the maximal random effect structure justified by the sample (final model: log.RT ~ Condition * Language + (1| ParticipantID) + (1|ItemID)).
The accuracy rates for the target phrases were approaching 100% (98.7% in L1, 98.9% in L2), and were thus at the ceiling, so that no statistical differences could be observed. Table 2 summarises mean latencies of the judgment task (see also Figure 1).
TABLE 2. Mean reaction times to target phrases in ms, standard deviations (in brackets)
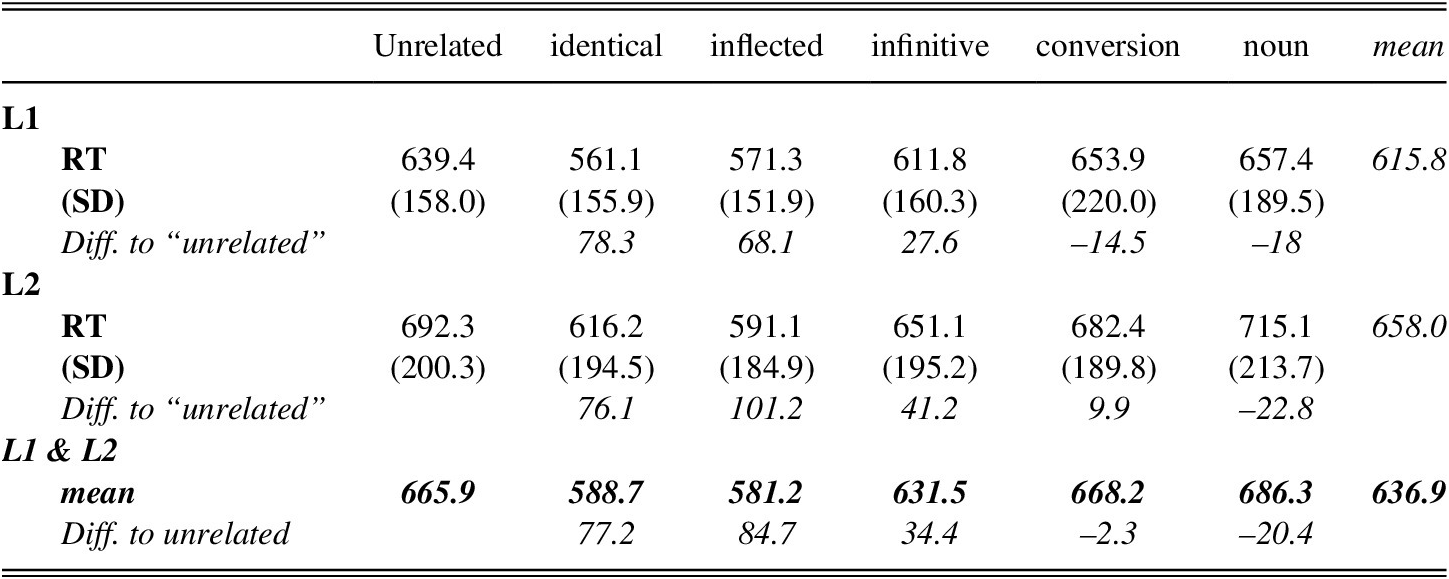

FIGURE 1. Mean reaction times to target phrases, comparing the results of Bordag and Opitz (Reference Bordag and Opitz2021) and the present study.
Analyses of the reaction times revealed main effects for Prime condition (F(5, 3011.5) = 54.77, p < .0001) and for Language (F(1,142.2) = 4.70, p = .032), but no significant interaction between the two (F(5, 3010.8) = 1.32, p = .253). The impact of the factor Language indicates that L2 speakers (658.0 ms) generally showed slower reaction times than L1 speakers (615.8 ms).
To further investigate the main effect of Prime condition, differences between the six levels of this factor were analyzed by computing multiple comparisons of estimated means with adjusted p-values (Tukey). Results are summarized in Table 3 (for details see the Appendix at the end of this article).
TABLE 3. Reaction times to target phrases for all participants (L1 and L2), p-values for pairwise contrasts
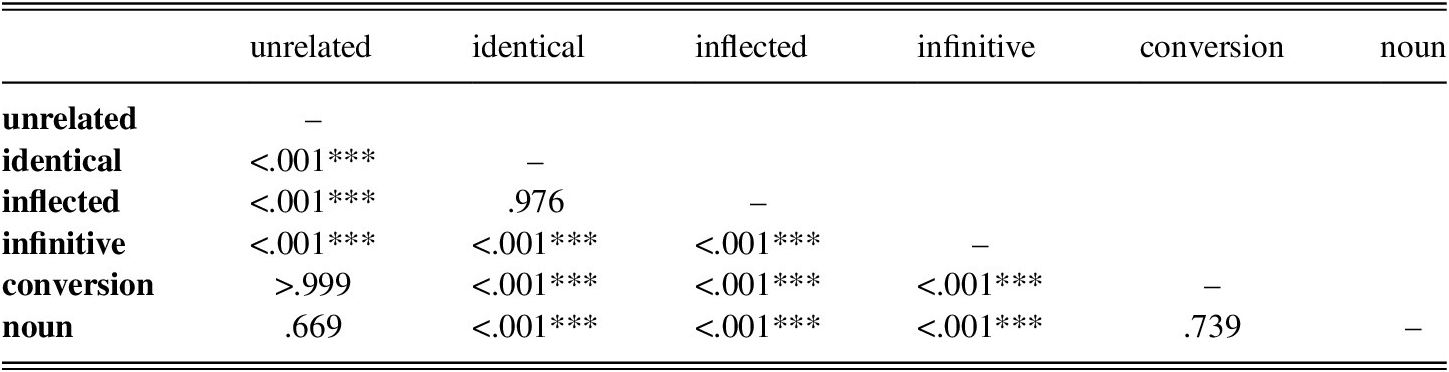
Note: p value adjustment: Tukey method for comparing a family of six estimates. Significance codes: *** p<.001; ** p<.01; * p<.05
Only four of these comparisons yielded no significant differences. The six conditions formed three distinct subgroups. The first group, yielding the slowest responses, was formed by three conditions: the unrelated (665.9 ms), the countable noun (686.3 ms), and the conversion condition (668.2 ms). The fastest responses were observed for a group comprising the identical (588.7 ms) and inflected (581.2 ms) conditions. The third group comprised only the infinitive condition, which scored between the fastest and slowest groups (631.5 ms).
Thus, the results almost mirror those reported in the former study (Bordag & Opitz, Reference Bordag and Opitz2021) except that responses to the critical conversion condition no longer cluster with the intermediate infinitive condition. Instead, they now cluster together with the group of slowest responses (i.e., the unrelated and the countable noun condition).
Figure 1 illustrates the main effect of Condition of the current study and compares it with the results of the previous study. Besides the very similar pattern for most of the conditions, the divergent status of the conversion conditions is apparent. This was also confirmed by additional inferential statistics using an adequate lme model.Footnote 7 Results revealed, beyond significant main effects for Language (F(1, 272.4) = 9.62, p =.002) and Condition (F(5, 5930.2) = 91.3, p <.001), crucially a significant interaction of Condition:Experiment (F(5, 5929.2) = 3.79, p = .002), and the absence of any interaction involving the factor Language (all p’s > .290). Given the very similar pattern of results observed within each study—except for the conversion condition—this significant interaction of Condition:Experiment confirms our inferred assumption that the conversion condition behaves differently in the two experiments by showing slower latencies for targets (i.e., no priming effect) when the orthographic cue is present. Additionally, the lack of any significant interaction involving Language furthermore gives no indication that L1 and L2 speakers process these forms differently. Thus, in both studies, no fundamental differences between L1 and L2 processing were obtained, except for generally slower responses of the nonnative participants.
However, to investigate potential differences within the L2 population, an explorative post-hoc analysis was carried out for the L2 participants, who were split into two groups. The lower proficiency group included 21 participants who self-assessed as B2 level and also scored at B2 level in at least one of the two language tests administered. The higher proficiency group comprised the other 51 participants. Given the low number of participants (especially in the lower proficiency group) and the unbalanced distribution of the six experimental lists among them, no significant differences between the two proficiency levels were expected, which was confirmed by the analyses: Proficiency (F(1, 70.23) = 1.93, p = .169); Proficiency: Condition (F(5, 1463.9) = 0.75, p = .622). Descriptively, however, the numerical pattern that surfaced suggests that the effect of capitalization in the conversion condition was driven primarily by the more advanced learners, who showed the same pattern as the German native participants (i.e., the conversion condition clusters together with the unrelated and countable noun conditions) (see Table 4 and Figure 2). In contrast, the lower proficiency group showed no difference between the conversion and infinitive conditions. Instead, they mirrored the pattern observed in Bordag and Opitz (Reference Bordag and Opitz2021) where no orthographic cues for word class were present. This suggests that participants with a relatively lower proficiency level (below C1) could not efficiently employ the orthographic marking for word-class disambiguation. Further research is, however, necessary to confirm this observation statistically.
TABLE 4. Mean reaction times to target phrases for L2 participants only (in ms)


FIGURE 2. Mean reaction times to target phrases for L2 participants; separate for each proficiency level.
DISCUSSION
The results of the present study reveal that orthographic cues, that is, capitalization of nouns, affect the processing of word-class information in German. This is manifested primarily in the pattern observed for conversion nouns: The orthographic cue distinctly marks the conversion form in the prime as nouns and emphasizes the difference to the word class of the inflected target verb. Interestingly, the capitalization cue has a similar effect on L1 and (advanced) L2 processing.
Bordag and Opitz (Reference Bordag and Opitz2021) presents evidence supporting the hypothesis that converted nouns are represented as subnodes in a complex lexical entry, which they share with representations of verbal forms. The idea of hierarchically structured entries was first suggested in theoretical linguistics (cf. default inheritance networks, Corbett & Fraser, Reference Corbett and Fraser1993; for German: Wunderlich & Fabri, Reference Wunderlich and Fabri1995). Psycholinguistic evidence that relates the access to various parts of a hierarchical lexical entry to partial (or full) priming comes, for example, from priming studies on stem variants (Bosch et al., Reference Bosch, Veríssimo and Clahsen2019; Clahsen et al., Reference Clahsen, Eisenbeiss, Hadler and Sonnenstuhl2001).
The results of the current priming experiments allow to further specify the structure of the complex lexical entry and the processing mechanism. We assume that the highest layer of the entry (or the mother/base node) is grammatically underspecified, that is, it does not comprise any word-class-specific features and is thus category neutral. When word-class-specific features need to be processed, a corresponding verbal or nominal subnode is accessed. This notion parallels formal morphological accounts like, for instance, Distributed Morphology (Halle & Marantz, Reference Halle, Marantz, Hale and Keyser1993; Harley & Noyer, Reference Harley and Noyer1999) by assuming category-neutral stem entries for words. In Distributed Morphology, however, a word’s category status is determined by features of the syntactic context in which it is inserted. In our account, a category-neutral base node mediates access to category-marked subnodes.
Thus, when participants read a phrase with an inflected verb, the verbal subnode is accessed through the neutral base node, so that the verbal features like person or number can be interpreted. The same structure (the base node and the verbal subnode) is then accessed when processing of the target phrase comprises the same or another inflected verbal form, which leads to full priming.
When an infinitive verb is presented in the prime, it is sufficient to access only the underspecified base node because no specific verbal features need to be interpreted for nonfinites. The same base form is then accessed at the presentation of the target inflected (verbal) form. However, the preactivated base node is only a part of the target structure. For the inflected target verb, new, not previously activated parts of the entry (i.e., the verbal subnode) need to be accessed. Therefore, only partial priming is observed. It is a question for further research, whether the representation of infinitives can suffice with the underspecified neutral base node, or whether infinitives also have their specific subnode similarly to conversion and under which conditions it is accessed.
For conversion nouns, we obtained a different pattern depending on the orthographic properties of the presented items. Because conversion nouns belong to the same group of nonfinites like infinitives, the processing of the prime and target would be, in principle, the same as described in the preceding text for the infinitive forms and should result in partial priming. This was the case in the former study when primes and targets were consistently presented in uppercase, and thus there was no reliable orthographic cue for the word class in the input—which is presumably also the case with auditory input. However, when a conversion noun is presented with an additional orthographic cue specifying its word class (i.e., capitalization of the first letter), noun-specific features are activated and thus the noun-specific subnode is accessed.Footnote 8 Therefore, the prime activates a (nominal) subnode of the entry that is in conflict with the (verbal) subnode of the target. The preactivated conversion noun subnode thus needs to be inhibited, so that the intended verb subnode can be selected for the target. The partial priming that would have arisen due to activating the same base node is thus cancelled out by the inhibition due to the competition between the two subnodes (noun and verb). It follows from this reasoning that the (nominal) subnode can be activated or coactivated directly by the corresponding orthographic form.
In the case of the countable noun condition in both studies, two semantically related but presumably distinct lexical entries (with identical forms) are involved in the processing of the prime and target. After the countable noun is interpreted as such at the prime presentation (it carries noun-information using both the orthographic and case/number marking), the same form appears again as target, but with a different (i.e., verbal) function. The preactivated representation needs to be inhibited, so that the reanalysis of the new form is possible to access the intended lexical entry. The potential priming effect based on the formal and/or semantic overlap of the two representations (as observed, e.g., in studies on polysemy) is thus cancelled out due to the necessary inhibition of the nonintended, preactivated node.
Our interpretation of the observed patterns of results assumes that the access to complex lexical entries can be “superficial” if accessing the full representational structure is dispensable for the interpretation of a given form. If it is sufficient to only access the neutral base entry, for example, for the processing of conversion forms or infinitives, and no other features (morphosyntactic or orthographic) trigger a more specific reading, more specific subentries do not have to be retrieved. The notion that processing of ambiguous utterances (or in this case forms) may not involve full specifications when only partial access (here to the underspecified head of the complex lexical entry) is sufficient for the interpretation complies with theories like the Shallow Structure Hypothesis (Clahsen & Felser, Reference Clahsen and Felser2006, Reference Clahsen and Felser2018) or “Good Enough” processing (Ferreira & Patson, Reference Ferreira and Patson2007; Sanford & Sturt, Reference Sanford and Sturt2002). These approaches argue that the goal of language comprehension is to establish representations that are merely “good enough” to suit the needs of a listener or reader in a given situation. The comparison between the experiments that did or did not involve explicit specification of word class on target forms indicates that orthographic cues similarly to morphological cues (in the form of word-class-specific inflectional endings) can trigger a deeper processing that is necessary to interpret these overt features both in L1 and L2.
The results of our study are in line with those of Bock and colleagues (especially Bock, Reference Bock1989) as they demonstrate that the capitalization has a function that goes beyond identification of stored written word shapes. They also confirm that L2 learners can acquire this property of the German language system similar to native German readers even though their native language does not involve word-class-specific orthographic cues. In addition, our study shows that the orthographic cues—at least in the case of homonymous forms—affect L1 and advanced L2 processing in the same way and that they can modulate the access to lexical entries. However, the analyses of the small subset of participants in our data with the lowest proficiency within the advanced (B2-C1) spectrum yielded a numerical trend that may be suggesting that nativelike processing of the capital initials of nouns is acquired relatively late in the acquisition process. More research to address the development of orthographic sensitivity to morphosyntactic processing is clearly needed, which would apply linguistic material that is more suitable for learners of lower proficiency levels.
CONCLUSION
In line with previous research, the results of the present study indicate that readers may resort to both deep and shallow processing during reading comprehension tasks, depending on contextual requirements and the availability of morphosyntactic cues. More importantly, we show that orthography shares its functions with morphosyntax in that it can trigger deeper processing and disambiguate word senses, a resource that both L1 and advanced L2 German speakers make use of to a similar extent. In conclusion, we assume that these findings point to a lexical entry consisting of an underspecified top layer, hosting word-class-independent semantic content, which then branches into word-class-specific subnodes that are activated during lexical retrieval when matching morphosyntactic or orthographic cues are encountered. Further research should address, for example, the precise representation of infinitives, or the developmental aspects of the emerging ability to use capitalization as a morphosyntactic cue in both the L1 and the L2. This could be done, for example, by also testing children learning to read and L2 populations at different proficiency levels.
Appendix
TABLE A1. Reaction times to target phrases: Estimated means and pair-wise contrast for levels of condition (averaged over both groups of participants)
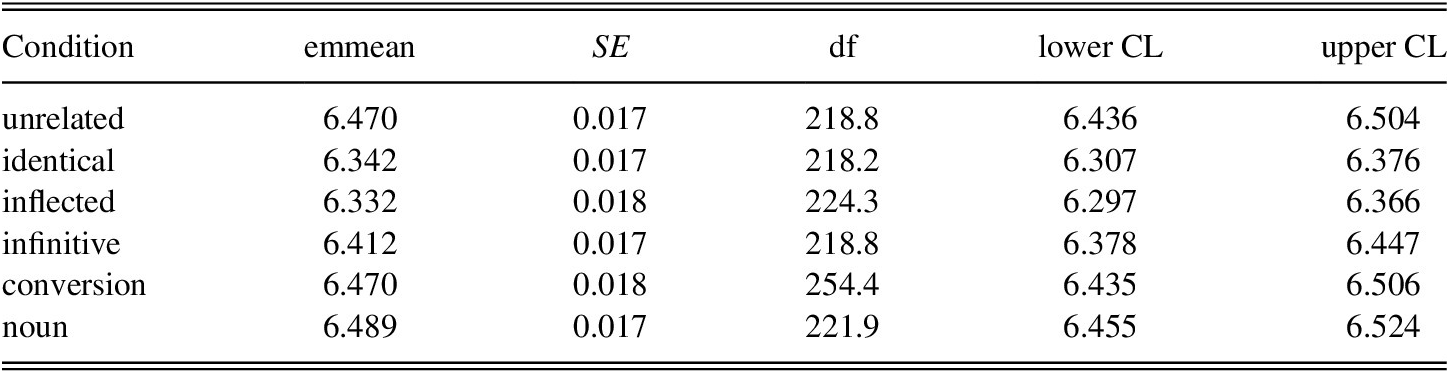
Note: Degrees-of-freedom method: Kenward–Roger; confidence level used: 0.95; Conf-level adjustment: Sidak method for six estimates.
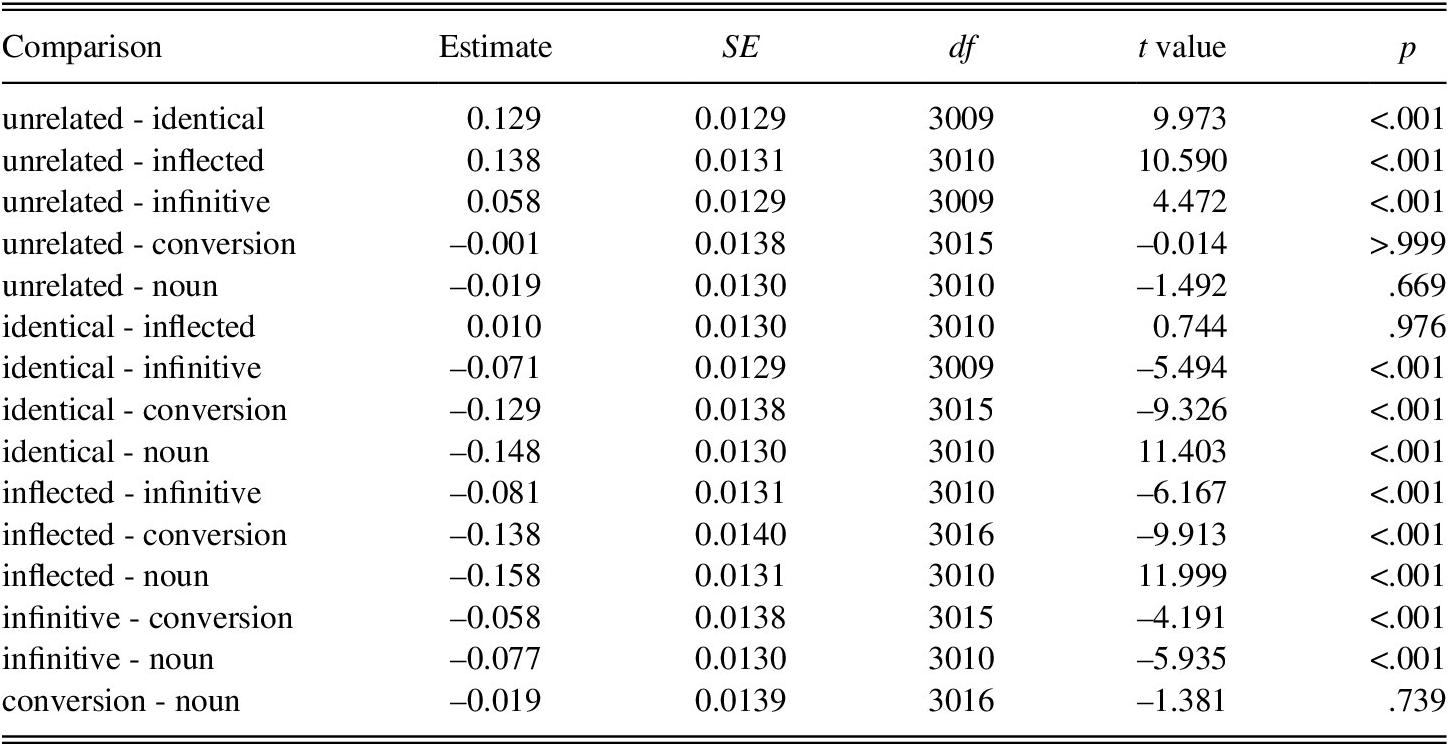
Note: Degrees-of-freedom method: Kenward–Roger; p value adjustment: Tukey method for comparing a family of six estimates.








 Open access
Open access