
Optical microrobots are activated by a laser in a liquid medium using optical tweezers. To create visual control loops for robotic automation, this work describes a deep learning-based method for orientation estimation of optical microrobots, focusing on detecting 3-D rotational movements and localizing microrobots and trapping points (TPs). We integrated and fine-tuned You Only Look Once (YOLOv7) and Deep Simple Online Real-time Tracking (DeepSORT) algorithms, improving microrobot and TP detection accuracy by 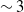 $\sim 3$% and
$\sim 3$% and 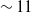 $\sim 11$%, respectively, at the 0.95 Intersection over Union (IoU) threshold in our test set. Additionally, it increased mean average precision (mAP) by 3% at the 0.5:0.95 IoU threshold during training. Our results showed a 99% success rate in trapping events with no false-positive detection. We introduced a model that employs EfficientNet as a feature extractor combined with custom convolutional neural networks (CNNs) and feature fusion layers. To demonstrate its generalization ability, we evaluated the model on an independent in-house dataset comprising 4,757 image frames, where microrobots executed simultaneous rotations across all three axes. Our method provided mean rotation angle errors of
$\sim 11$%, respectively, at the 0.95 Intersection over Union (IoU) threshold in our test set. Additionally, it increased mean average precision (mAP) by 3% at the 0.5:0.95 IoU threshold during training. Our results showed a 99% success rate in trapping events with no false-positive detection. We introduced a model that employs EfficientNet as a feature extractor combined with custom convolutional neural networks (CNNs) and feature fusion layers. To demonstrate its generalization ability, we evaluated the model on an independent in-house dataset comprising 4,757 image frames, where microrobots executed simultaneous rotations across all three axes. Our method provided mean rotation angle errors of 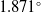 $1.871^\circ$,
$1.871^\circ$, 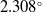 $2.308^\circ$, and
$2.308^\circ$, and 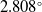 $2.808^\circ$ for X (yaw), Y (roll), and Z (pitch) axes, respectively. Compared to pre-trained models, our model provided the lowest error in the Y and Z axes while offering competitive results for X-axis. Finally, we demonstrated the explainability and transparency of the model’s decision-making process. Our work contributes to the field of microrobotics by providing an efficient 3-axis orientation estimation pipeline, with a clear focus on automation.
$2.808^\circ$ for X (yaw), Y (roll), and Z (pitch) axes, respectively. Compared to pre-trained models, our model provided the lowest error in the Y and Z axes while offering competitive results for X-axis. Finally, we demonstrated the explainability and transparency of the model’s decision-making process. Our work contributes to the field of microrobotics by providing an efficient 3-axis orientation estimation pipeline, with a clear focus on automation.
We propose a neural network architecture and a training procedure to estimate blurring operators and deblur images from a single degraded image. Our key assumption is that the forward operators can be parameterized by a low-dimensional vector. The models we consider include a description of the point spread function with Zernike polynomials in the pupil plane or product-convolution expansions, which incorporate space-varying operators. Numerical experiments show that the proposed method can accurately and robustly recover the blur parameters even for large noise levels. For a convolution model, the average signal-to-noise ratio of the recovered point spread function ranges from 13 dB in the noiseless regime to 8 dB in the high-noise regime. In comparison, the tested alternatives yield negative values. This operator estimate can then be used as an input for an unrolled neural network to deblur the image. Quantitative experiments on synthetic data demonstrate that this method outperforms other commonly used methods both perceptually and in terms of SSIM. The algorithm can process a 512  $ \times $ 512 image under a second on a consumer graphics card and does not require any human interaction once the operator parameterization has been set up.1
$ \times $ 512 image under a second on a consumer graphics card and does not require any human interaction once the operator parameterization has been set up.1

