It is understood that ensuring equation balance is a necessary condition for a valid model of times series data. Yet, the definition of balance provided so far has been incomplete and there has not been a consistent understanding of exactly why balance is important or how it can be applied. The discussion to date has focused on the estimates produced by the general error correction model (GECM). In this paper, we go beyond the GECM and beyond model estimates. We treat equation balance as a theoretical matter, not merely an empirical one, and describe how to use the concept of balance to test theoretical propositions before longitudinal data have been gathered. We explain how equation balance can be used to check if your theoretical or empirical model is either wrong or incomplete in a way that will prevent a meaningful interpretation of the model. We also raise the issue of “
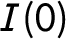 $I(0)$
balance” and its importance.
$I(0)$
balance” and its importance.

