
2 results
Sample mean based index policies by O(log n) regret for the multi-armed bandit problem
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 27 / Issue 4 / December 1995
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1054-1078
- Print publication:
- December 1995
-
- Article
- Export citation
Minimizing the learning loss in adaptive control of Markov chains under the weak accessibility condition
-
- Journal:
- Journal of Applied Probability / Volume 28 / Issue 4 / December 1991
- Published online by Cambridge University Press:
- 14 July 2016, pp. 779-790
- Print publication:
- December 1991
-
- Article
- Export citation
-
We consider the adaptive control of Markov chains under the weak accessibility condition with a view to minimizing the learning loss. A certainty equivalence control with a forcing scheme is constructed. We use a stationary randomized control scheme for forcing and compute a maximum likelihood estimate of the unknown parameter from the resulting observations. We obtain an exponential upper bound on the rate of decay of the probability of error. This allows us to choose the rate of forcing appropriately, whereby we achieve a o(f(n) log n) learning loss for any function
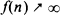 as
as  .
.
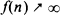 as
as  .
.