Refine search
Actions for selected content:
46 results
A supervised machine learning approach for the decision-making process on data-based culling in dairy farms
-
- Journal:
- Journal of Dairy Research , First View
- Published online by Cambridge University Press:
- 18 September 2025, pp. 1-10
-
- Article
- Export citation
Identifying optimal microwave frequencies to detect floating macroplastic litter using machine learning
-
- Journal:
- International Journal of Microwave and Wireless Technologies / Volume 17 / Issue 5 / June 2025
- Published online by Cambridge University Press:
- 05 August 2025, pp. 804-818
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Deep learning and similarity-based models for predicting turbofan engine remaining useful life: insights from the CMAPSS dataset
-
- Journal:
- The Aeronautical Journal / Volume 129 / Issue 1337 / July 2025
- Published online by Cambridge University Press:
- 14 April 2025, pp. 2004-2035
-
- Article
- Export citation
A Deep Learning Algorithm for High-Dimensional Exploratory Item Factor Analysis
-
- Journal:
- Psychometrika / Volume 86 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1-29
-
- Article
- Export citation
Transfer learning for predicting source terms of principal component transport in chemically reactive flow
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 13 December 2024, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
12 - Algorithms
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 269-280
-
- Chapter
- Export citation
11 - Big Data
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 248-268
-
- Chapter
- Export citation
A novel morphing soft robot design to minimize deviations
-
- Article
- Export citation
-
Soft robotics is rapidly advancing, particularly in medical device applications. A particular miniaturized manipulator design that offers high dexterity, multiple degrees-of-freedom, and better lateral force rendering than competing designs, has great potential for minimally invasive surgery. However, it faces challenges such as the tendency to suddenly and unpredictably deviate in bending plane orientation at higher pressures. In this work, we identified the cause of this deviation as the buckling of the partition wall and proposed design alternatives along with their manufacturing process to address the problem without compromising the original design features. In both simulation and experiment, the novel design managed to achieve a better bending performance in terms of stiffness and reduced deviation of the bending plane. We also developed an artificial neural network-based inverse kinematics model to further improve the performance of the prototype during vectorization. This approach yielded mean absolute errors in orientation of the bending plane below
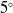 $5^{\circ }$.
$5^{\circ }$.
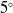
Modeling of multicomponent adsorption equilibria of phenol and ciprofloxacin on pristine, acid-modified and thermo-oxidatively-aged polyethylene terephthalate microplastics
-
- Journal:
- Cambridge Prisms: Plastics / Volume 2 / 2024
- Published online by Cambridge University Press:
- 07 October 2024, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Artificial neural network-based control of powered knee exoskeletons for lifting tasks: design and experimental validation
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Monthly rainfall prediction using artificial neural network (case study: Republic of Benin)
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 02 May 2024, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
End-to-end deep learning-based framework for path planning and collision checking: bin-picking application
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Neural representation of the stratospheric ozone chemistry
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 04 December 2023, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing Triage and Management in Earthquake-Related Injuries: The SAFE-QUAKE Scoring System for Predicting Dialysis Requirements
-
- Journal:
- Prehospital and Disaster Medicine / Volume 38 / Issue 6 / December 2023
- Published online by Cambridge University Press:
- 04 October 2023, pp. 716-724
- Print publication:
- December 2023
-
- Article
- Export citation
Hydroinformatics: A review and future outlook
-
- Journal:
- Cambridge Prisms: Water / Volume 1 / 2023
- Published online by Cambridge University Press:
- 26 September 2023, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Case Studies on Superalloy Design
-
- Book:
- Computational Design of Engineering Materials
- Published online:
- 29 June 2023
- Print publication:
- 29 June 2023, pp 323-341
-
- Chapter
- Export citation
6 - Neural Networks
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 173-215
-
- Chapter
- Export citation
A robust and efficient wall parameter estimation approach for through wall radar
-
- Journal:
- International Journal of Microwave and Wireless Technologies / Volume 15 / Issue 7 / September 2023
- Published online by Cambridge University Press:
- 17 October 2022, pp. 1147-1153
-
- Article
- Export citation
