The convex hull of a sample is used to approximate the support of the underlying distribution. This approximation has many practical implications in real life. To approximate the distribution of the functionals of convex hulls, asymptotic theory plays a crucial role. Unfortunately most of the asymptotic results are computationally intractable. To address this computational intractability, we consider consistent bootstrapping schemes for certain cases. Let 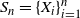 $S_n=\{X_i\}_{i=1}^{n}$ be a sequence of independent and identically distributed random points uniformly distributed on an unknown convex set in
$S_n=\{X_i\}_{i=1}^{n}$ be a sequence of independent and identically distributed random points uniformly distributed on an unknown convex set in 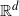 $\mathbb{R}^{d}$
(
$\mathbb{R}^{d}$
(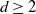 $d\ge 2$
). We suggest a bootstrapping scheme that relies on resampling uniformly from the convex hull of
$d\ge 2$
). We suggest a bootstrapping scheme that relies on resampling uniformly from the convex hull of 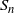 $S_n$
. Moreover, the resampling asymptotic consistency of certain functionals of convex hulls is derived under this bootstrapping scheme. In particular, we apply our bootstrapping technique to the Hausdorff distance between the actual convex set and its estimator. For
$S_n$
. Moreover, the resampling asymptotic consistency of certain functionals of convex hulls is derived under this bootstrapping scheme. In particular, we apply our bootstrapping technique to the Hausdorff distance between the actual convex set and its estimator. For 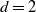 $d=2$
, we investigate the asymptotic consistency of the suggested bootstrapping scheme for the area of the symmetric difference and the perimeter difference between the actual convex set and its estimate. In all cases the consistency allows us to rely on the suggested resampling scheme to study the actual distributions, which are not computationally tractable.
$d=2$
, we investigate the asymptotic consistency of the suggested bootstrapping scheme for the area of the symmetric difference and the perimeter difference between the actual convex set and its estimate. In all cases the consistency allows us to rely on the suggested resampling scheme to study the actual distributions, which are not computationally tractable.

