Refine search
Actions for selected content:
24 results
Bounds on some geometric functionals of high dimensional Brownian convex hulls and their inverse processes
- Part of
-
- Journal:
- Canadian Mathematical Bulletin , First View
- Published online by Cambridge University Press:
- 27 August 2025, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove two-sided bounds on the expected values of several geometric functionals of the convex hull of Brownian motion in
 $\mathbb {R}^n$ and their inverse processes. This extends some recent results of McRedmond and Xu (2017), Jovalekić (2021), and Cygan, Šebek, and the first author (2023) from the plane to higher dimensions. Our main result shows that the average time required for the convex hull in
$\mathbb {R}^n$ and their inverse processes. This extends some recent results of McRedmond and Xu (2017), Jovalekić (2021), and Cygan, Šebek, and the first author (2023) from the plane to higher dimensions. Our main result shows that the average time required for the convex hull in  $\mathbb {R}^n$ to attain unit volume is at most
$\mathbb {R}^n$ to attain unit volume is at most  $n\sqrt [n]{n!}$. The proof relies on a novel procedure that embeds an n-simplex of prescribed volume within the convex hull of the Brownian path run up to a certain stopping time. All of our bounds capture the correct order of asymptotic growth or decay in the dimension n.
$n\sqrt [n]{n!}$. The proof relies on a novel procedure that embeds an n-simplex of prescribed volume within the convex hull of the Brownian path run up to a certain stopping time. All of our bounds capture the correct order of asymptotic growth or decay in the dimension n.



10 - Excursion: Problems in Machine Learning
-
- Book:
- Advanced Linear Algebra
- Published online:
- 27 May 2025
- Print publication:
- 12 June 2025, pp 272-302
-
- Chapter
- Export citation
23 - Multiplicative weights update method
- from Part II - Quantum algorithmic primitives
-
- Book:
- Quantum Algorithms
- Published online:
- 03 May 2025
- Print publication:
- 24 April 2025, pp 299-304
-
- Chapter
-
- You have access
- Open access
- Export citation
5 - Continuous optimization
- from Part I - Areas of application
-
- Book:
- Quantum Algorithms
- Published online:
- 03 May 2025
- Print publication:
- 24 April 2025, pp 78-97
-
- Chapter
-
- You have access
- Open access
- Export citation
22 - Quantum interior point methods
- from Part II - Quantum algorithmic primitives
-
- Book:
- Quantum Algorithms
- Published online:
- 03 May 2025
- Print publication:
- 24 April 2025, pp 291-298
-
- Chapter
-
- You have access
- Open access
- Export citation
Global Convergence of the EM Algorithm for Unconstrained Latent Variable Models with Categorical Indicators
-
- Journal:
- Psychometrika / Volume 78 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 01 January 2025, pp. 134-153
-
- Article
- Export citation
The art of interconnections: Achieving maximum algebraic connectivity in multilayer networks
-
- Journal:
- Network Science / Volume 12 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 24 September 2024, pp. 261-288
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal transport through a toll station
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 36 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 18 September 2024, pp. 613-637
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stochastic linearized generalized alternating direction method of multipliers: Expected convergence rates and large deviation properties
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 3 / March 2024
- Published online by Cambridge University Press:
- 14 March 2023, pp. 162-179
-
- Article
- Export citation
-
Alternating direction method of multipliers (ADMM) receives much attention in the field of optimization and computer science, etc. The generalized ADMM (G-ADMM) proposed by Eckstein and Bertsekas incorporates an acceleration factor and is more efficient than the original ADMM. However, G-ADMM is not applicable in some models where the objective function value (or its gradient) is computationally costly or even impossible to compute. In this paper, we consider the two-block separable convex optimization problem with linear constraints, where only noisy estimations of the gradient of the objective function are accessible. Under this setting, we propose a stochastic linearized generalized ADMM (called SLG-ADMM) where two subproblems are approximated by some linearization strategies. And in theory, we analyze the expected convergence rates and large deviation properties of SLG-ADMM. In particular, we show that the worst-case expected convergence rates of SLG-ADMM are
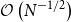 $\mathcal{O}\left( {{N}^{-1/2}}\right)$ and
$\mathcal{O}\left( {{N}^{-1/2}}\right)$ and 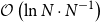 $\mathcal{O}\left({\ln N} \cdot {N}^{-1}\right)$ for solving general convex and strongly convex problems, respectively, where N is the iteration number, similarly hereinafter, and with high probability, SLG-ADMM has
$\mathcal{O}\left({\ln N} \cdot {N}^{-1}\right)$ for solving general convex and strongly convex problems, respectively, where N is the iteration number, similarly hereinafter, and with high probability, SLG-ADMM has 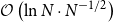 $\mathcal{O}\left ( \ln N \cdot N^{-1/2} \right ) $ and
$\mathcal{O}\left ( \ln N \cdot N^{-1/2} \right ) $ and 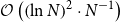 $\mathcal{O}\left ( \left ( \ln N \right )^{2} \cdot N^{-1} \right ) $ constraint violation bounds and objective error bounds for general convex and strongly convex problems, respectively.
$\mathcal{O}\left ( \left ( \ln N \right )^{2} \cdot N^{-1} \right ) $ constraint violation bounds and objective error bounds for general convex and strongly convex problems, respectively.
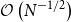
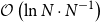
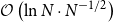
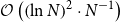
3 - Descent Methods
-
- Book:
- Optimization for Data Analysis
- Published online:
- 31 March 2022
- Print publication:
- 21 April 2022, pp 26-54
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Compressive Imaging: Structure, Sampling, Learning
- Published online:
- 16 July 2021
- Print publication:
- 16 September 2021, pp 1-26
-
- Chapter
- Export citation
Compressive Imaging: Structure, Sampling, Learning
-
- Published online:
- 16 July 2021
- Print publication:
- 16 September 2021
4 - Information-Theoretic Bounds on Sketching
-
-
- Book:
- Information-Theoretic Methods in Data Science
- Published online:
- 22 March 2021
- Print publication:
- 08 April 2021, pp 104-133
-
- Chapter
- Export citation
Convex optimization of coil spacing in cascaded multi-coil wireless power transfer
-
- Journal:
- Wireless Power Transfer / Volume 7 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 19 February 2020, pp. 42-50
- Print publication:
- March 2020
-
- Article
- Export citation
Discreteness and group sparsity aware detection for uplink overloaded MU-MIMO systems
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 06 October 2020, e21
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Noise masking method based on an effective ratio mask estimation in Gammatone channels
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 7 / 2018
- Published online by Cambridge University Press:
- 15 May 2018, e5
- Print publication:
- 2018
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
DISTRIBUTED PROXIMAL-GRADIENT METHOD FOR CONVEX OPTIMIZATION WITH INEQUALITY CONSTRAINTS
-
- Journal:
- The ANZIAM Journal / Volume 56 / Issue 2 / October 2014
- Published online by Cambridge University Press:
- 18 November 2014, pp. 160-178
-
- Article
-
- You have access
- Export citation
-
We consider a distributed optimization problem over a multi-agent network, in which the sum of several local convex objective functions is minimized subject to global convex inequality constraints. We first transform the constrained optimization problem to an unconstrained one, using the exact penalty function method. Our transformed problem has a smaller number of variables and a simpler structure than the existing distributed primal–dual subgradient methods for constrained distributed optimization problems. Using the special structure of this problem, we then propose a distributed proximal-gradient algorithm over a time-changing connectivity network, and establish a convergence rate depending on the number of iterations, the network topology and the number of agents. Although the transformed problem is nonsmooth by nature, our method can still achieve a convergence rate,
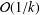 ${\mathcal{O}}(1/k)$, after
${\mathcal{O}}(1/k)$, after 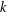 $k$ iterations, which is faster than the rate,
$k$ iterations, which is faster than the rate, 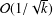 ${\mathcal{O}}(1/\sqrt{k})$, of existing distributed subgradient-based methods. Simulation experiments on a distributed state estimation problem illustrate the excellent performance of our proposed method.
${\mathcal{O}}(1/\sqrt{k})$, of existing distributed subgradient-based methods. Simulation experiments on a distributed state estimation problem illustrate the excellent performance of our proposed method.
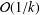
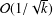
Efficient Convex Optimization Approaches to Variational Image Fusion
-
- Journal:
- Numerical Mathematics: Theory, Methods and Applications / Volume 7 / Issue 2 / May 2014
- Published online by Cambridge University Press:
- 28 May 2015, pp. 234-250
- Print publication:
- May 2014
-
- Article
- Export citation
-
Image fusion is an imaging technique to visualize information from multiple imaging sources in one single image, which is widely used in remote sensing, medical imaging etc. In this work, we study two variational approaches to image fusion which are closely related to the standard TV-L 2 and TV-L 1 image approximation methods. We investigate their convex optimization formulations, under the perspective of primal and dual, and propose their associated new image decomposition models. In addition, we consider the TV-L 1 based image fusion approach and study the specified problem of fusing two discrete-constrained images
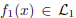 and
and 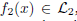 where
where 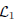 and
and 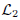 are the sets of linearly-ordered discrete values. We prove that the TV-L 1 based image fusion actually gives rise to the exact convex relaxation to the corresponding nonconvex image fusion constrained by the discrete-valued set
are the sets of linearly-ordered discrete values. We prove that the TV-L 1 based image fusion actually gives rise to the exact convex relaxation to the corresponding nonconvex image fusion constrained by the discrete-valued set 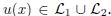 This extends the results for the global optimization of the discrete-constrained TV-L 1 image approximation [8, 36] to the case of image fusion. As a big numerical advantage of the two proposed dual models, we show both of them directly lead to new fast and reliable algorithms, based on modern convex optimization techniques. Experiments with medical images, remote sensing images and multi-focus images visibly show the qualitative differences between the two studied variational models of image fusion. We also apply the new variational approaches to fusing 3D medical images.
This extends the results for the global optimization of the discrete-constrained TV-L 1 image approximation [8, 36] to the case of image fusion. As a big numerical advantage of the two proposed dual models, we show both of them directly lead to new fast and reliable algorithms, based on modern convex optimization techniques. Experiments with medical images, remote sensing images and multi-focus images visibly show the qualitative differences between the two studied variational models of image fusion. We also apply the new variational approaches to fusing 3D medical images.
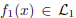 and
and 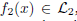 where
where 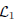 and
and 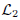 are the sets of linearly-ordered discrete values. We prove that the TV-
are the sets of linearly-ordered discrete values. We prove that the TV-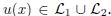 This extends the results for the global optimization of the discrete-constrained TV-
This extends the results for the global optimization of the discrete-constrained TV-