In this article, we propose to use the character theory of compact Lie groups and their orthogonality relations for the study of Frobenius distribution and Sato–Tate groups. The results show the advantages of this new approach in several aspects. With samples of Frobenius ranging in size much smaller than the moment statistic approach, we obtain very good approximation to the expected values of these orthogonality relations, which give useful information about the underlying Sato–Tate groups and strong evidence of the correctness of the generalized Sato–Tate conjecture. In fact, 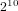 $2^{10}$ to
$2^{10}$ to 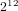 $2^{12}$ points provide satisfactory convergence. Even for
$2^{12}$ points provide satisfactory convergence. Even for 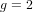 $g=2$, the classical approach using moment statistics requires about
$g=2$, the classical approach using moment statistics requires about 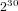 $2^{30}$ sample points to obtain such information.
$2^{30}$ sample points to obtain such information.
In this paper we describe how to compute smallest monic polynomials that define a given number field 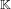 $\mathbb{K}$. We make use of the one-to-one correspondence between monic defining polynomials of
$\mathbb{K}$. We make use of the one-to-one correspondence between monic defining polynomials of 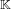 $\mathbb{K}$ and algebraic integers that generate
$\mathbb{K}$ and algebraic integers that generate 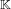 $\mathbb{K}$. Thus, a smallest polynomial corresponds to a vector in the lattice of integers of
$\mathbb{K}$. Thus, a smallest polynomial corresponds to a vector in the lattice of integers of 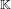 $\mathbb{K}$ and this vector is short in some sense. The main idea is to consider weighted coordinates for the vectors of the lattice of integers of
$\mathbb{K}$ and this vector is short in some sense. The main idea is to consider weighted coordinates for the vectors of the lattice of integers of 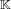 $\mathbb{K}$. This allows us to find the desired polynomial by enumerating short vectors in these weighted lattices. In the context of the subexponential algorithm of Biasse and Fieker for computing class groups, this algorithm can be used as a precomputation step that speeds up the rest of the computation. It also widens the applicability of their faster conditional method, which requires a defining polynomial of small height, to a much larger set of number field descriptions.
$\mathbb{K}$. This allows us to find the desired polynomial by enumerating short vectors in these weighted lattices. In the context of the subexponential algorithm of Biasse and Fieker for computing class groups, this algorithm can be used as a precomputation step that speeds up the rest of the computation. It also widens the applicability of their faster conditional method, which requires a defining polynomial of small height, to a much larger set of number field descriptions.
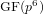 $\text{GF}(p^{6})$
$\text{GF}(p^{6})$
In order to assess the security of cryptosystems based on the discrete logarithm problem in non-prime finite fields, as are the torus-based or pairing-based ones, we investigate thoroughly the case in 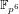 $\mathbb{F}_{p^{6}}$ with the number field sieve. We provide new insights, improvements, and comparisons between different methods to select polynomials intended for a sieve in dimension 3 using a special-
$\mathbb{F}_{p^{6}}$ with the number field sieve. We provide new insights, improvements, and comparisons between different methods to select polynomials intended for a sieve in dimension 3 using a special-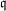 $\mathfrak{q}$ strategy. We also take into account the Galois action to increase the relation productivity of the sieving phase. To validate our results, we ran several experiments and real computations for various polynomial selection methods and field sizes with our publicly available implementation of the sieve in dimension 3, with special-
$\mathfrak{q}$ strategy. We also take into account the Galois action to increase the relation productivity of the sieving phase. To validate our results, we ran several experiments and real computations for various polynomial selection methods and field sizes with our publicly available implementation of the sieve in dimension 3, with special-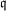 $\mathfrak{q}$ and various enumeration strategies.
$\mathfrak{q}$ and various enumeration strategies.
Most systematic tables of data associated to ranks of elliptic curves order the curves by conductor. Recent developments, led by work of Bhargava and Shankar studying the average sizes of  $n$-Selmer groups, have given new upper bounds on the average algebraic rank in families of elliptic curves over
$n$-Selmer groups, have given new upper bounds on the average algebraic rank in families of elliptic curves over 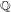 $\mathbb{Q}$, ordered by height. We describe databases of elliptic curves over
$\mathbb{Q}$, ordered by height. We describe databases of elliptic curves over 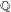 $\mathbb{Q}$, ordered by height, in which we compute ranks and
$\mathbb{Q}$, ordered by height, in which we compute ranks and  $2$-Selmer group sizes, the distributions of which may also be compared to these theoretical results. A striking new phenomenon that we observe in our database is that the average rank eventually decreases as height increases.
$2$-Selmer group sizes, the distributions of which may also be compared to these theoretical results. A striking new phenomenon that we observe in our database is that the average rank eventually decreases as height increases.
