Refine search
Actions for selected content:
33 results
Deep learning–based automated weed coverage estimation for herbicide efficacy assessment and turfgrass management
-
- Journal:
- Weed Science / Volume 73 / Issue 1 / 2025
- Published online by Cambridge University Press:
- 28 July 2025, e60
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
2 - Basics of machine learning
-
- Book:
- Machine Learning in Quantum Sciences
- Published online:
- 13 June 2025
- Print publication:
- 12 June 2025, pp 14-46
-
- Chapter
- Export citation
Wireless propagation parameter estimation with convolutional neural networks
-
- Journal:
- International Journal of Microwave and Wireless Technologies / Volume 17 / Issue 5 / June 2025
- Published online by Cambridge University Press:
- 09 April 2025, pp. 892-899
-
- Article
- Export citation
DPD-v2: Generalised deep particle diffusometry for varied particle shapes and experimental conditions
- Part of
-
- Journal:
- Flow: Applications of Fluid Mechanics / Volume 5 / 2025
- Published online by Cambridge University Press:
- 31 March 2025, E6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Particle diffusometry (PD) is a technique of measuring the diffusion coefficient of a fluid sample by seeding it with tracer particles and observing their motion under a microscope. In microfluidic set-ups, the observed particles are often defocused and their motion is affected by factors such as fluid flow, which leads to high errors for conventional and deep learning-based PD (DPD) algorithms. This work improves the performance of DPD models by updating their architecture, avoiding temporal averaging in the input, and exploring the impact of various choices during training. These models provide state-of-the-art performance for generalised datasets regardless of particle shapes, concentration, flow or image noise and are called DPD-v2. These models provide a mean absolute error of 0.09
 $\unicode{x03BC}$m2s−1 for Gaussian particles and 0.07
$\unicode{x03BC}$m2s−1 for Gaussian particles and 0.07 $\unicode{x03BC}$m2s−1 for defocused particles, which is 2x–4x lower errors as compared with the two following best methods. The performance of DPD-v2 models increases with crop size and the use of multiple stacks of images. The outputs of the DPD-v2 models were compared against the outputs from conventional algorithms on Gaussianised experimental no flow datasets, which provided < 0.5
$\unicode{x03BC}$m2s−1 for defocused particles, which is 2x–4x lower errors as compared with the two following best methods. The performance of DPD-v2 models increases with crop size and the use of multiple stacks of images. The outputs of the DPD-v2 models were compared against the outputs from conventional algorithms on Gaussianised experimental no flow datasets, which provided < 0.5 $\unicode{x03BC}$m2s−1 mean absolute difference. Hence, the DPD-v2 models can be used in real-world scenarios.
$\unicode{x03BC}$m2s−1 mean absolute difference. Hence, the DPD-v2 models can be used in real-world scenarios.



Physics-constrained convolutional neural networks for inverse problems in spatiotemporal partial differential equations
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 20 December 2024, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Three-dimensional optical microrobot orientation estimation and tracking using deep learning
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Optical microrobots are activated by a laser in a liquid medium using optical tweezers. To create visual control loops for robotic automation, this work describes a deep learning-based method for orientation estimation of optical microrobots, focusing on detecting 3-D rotational movements and localizing microrobots and trapping points (TPs). We integrated and fine-tuned You Only Look Once (YOLOv7) and Deep Simple Online Real-time Tracking (DeepSORT) algorithms, improving microrobot and TP detection accuracy by
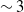 $\sim 3$% and
$\sim 3$% and 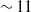 $\sim 11$%, respectively, at the 0.95 Intersection over Union (IoU) threshold in our test set. Additionally, it increased mean average precision (mAP) by 3% at the 0.5:0.95 IoU threshold during training. Our results showed a 99% success rate in trapping events with no false-positive detection. We introduced a model that employs EfficientNet as a feature extractor combined with custom convolutional neural networks (CNNs) and feature fusion layers. To demonstrate its generalization ability, we evaluated the model on an independent in-house dataset comprising 4,757 image frames, where microrobots executed simultaneous rotations across all three axes. Our method provided mean rotation angle errors of
$\sim 11$%, respectively, at the 0.95 Intersection over Union (IoU) threshold in our test set. Additionally, it increased mean average precision (mAP) by 3% at the 0.5:0.95 IoU threshold during training. Our results showed a 99% success rate in trapping events with no false-positive detection. We introduced a model that employs EfficientNet as a feature extractor combined with custom convolutional neural networks (CNNs) and feature fusion layers. To demonstrate its generalization ability, we evaluated the model on an independent in-house dataset comprising 4,757 image frames, where microrobots executed simultaneous rotations across all three axes. Our method provided mean rotation angle errors of 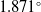 $1.871^\circ$,
$1.871^\circ$, 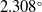 $2.308^\circ$, and
$2.308^\circ$, and 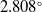 $2.808^\circ$ for X (yaw), Y (roll), and Z (pitch) axes, respectively. Compared to pre-trained models, our model provided the lowest error in the Y and Z axes while offering competitive results for X-axis. Finally, we demonstrated the explainability and transparency of the model’s decision-making process. Our work contributes to the field of microrobotics by providing an efficient 3-axis orientation estimation pipeline, with a clear focus on automation.
$2.808^\circ$ for X (yaw), Y (roll), and Z (pitch) axes, respectively. Compared to pre-trained models, our model provided the lowest error in the Y and Z axes while offering competitive results for X-axis. Finally, we demonstrated the explainability and transparency of the model’s decision-making process. Our work contributes to the field of microrobotics by providing an efficient 3-axis orientation estimation pipeline, with a clear focus on automation.
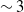
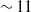
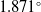
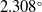
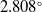
Classification of compact radio sources in the Galactic plane with supervised machine learning
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e029
-
- Article
- Export citation
-
Generation of science-ready data from processed data products is one of the major challenges in next-generation radio continuum surveys with the Square Kilometre Array (SKA) and its precursors, due to the expected data volume and the need to achieve a high degree of automated processing. Source extraction, characterization, and classification are the major stages involved in this process. In this work we focus on the classification of compact radio sources in the Galactic plane using both radio and infrared images as inputs. To this aim, we produced a curated dataset of
 $\sim$20 000 images of compact sources of different astronomical classes, obtained from past radio and infrared surveys, and novel radio data from pilot surveys carried out with the Australian SKA Pathfinder. Radio spectral index information was also obtained for a subset of the data. We then trained two different classifiers on the produced dataset. The first model uses gradient-boosted decision trees and is trained on a set of pre-computed features derived from the data, which include radio-infrared colour indices and the radio spectral index. The second model is trained directly on multi-channel images, employing convolutional neural networks. Using a completely supervised procedure, we obtained a high classification accuracy (F1-score > 90%) for separating Galactic objects from the extragalactic background. Individual class discrimination performances, ranging from 60% to 75%, increased by 10% when adding far-infrared and spectral index information, with extragalactic objects, PNe and Hii regions identified with higher accuracies. The implemented tools and trained models were publicly released and made available to the radioastronomical community for future application on new radio data.
$\sim$20 000 images of compact sources of different astronomical classes, obtained from past radio and infrared surveys, and novel radio data from pilot surveys carried out with the Australian SKA Pathfinder. Radio spectral index information was also obtained for a subset of the data. We then trained two different classifiers on the produced dataset. The first model uses gradient-boosted decision trees and is trained on a set of pre-computed features derived from the data, which include radio-infrared colour indices and the radio spectral index. The second model is trained directly on multi-channel images, employing convolutional neural networks. Using a completely supervised procedure, we obtained a high classification accuracy (F1-score > 90%) for separating Galactic objects from the extragalactic background. Individual class discrimination performances, ranging from 60% to 75%, increased by 10% when adding far-infrared and spectral index information, with extragalactic objects, PNe and Hii regions identified with higher accuracies. The implemented tools and trained models were publicly released and made available to the radioastronomical community for future application on new radio data.
6 - Learning for Robots
- from Part two - Representation and Planning
-
- Book:
- Computational Principles of Mobile Robotics
- Published online:
- 19 March 2024
- Print publication:
- 08 February 2024, pp 161-184
-
- Chapter
- Export citation
Simulation-based nozzle density optimization for maximized efficacy of a machine vision–based weed control system for applications in turfgrass settings
-
- Journal:
- Weed Technology / Volume 38 / 2024
- Published online by Cambridge University Press:
- 06 February 2024, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Towards learned emulation of interannual water isotopologue variations in General Circulation Models
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 04 October 2023, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identifying climate models based on their daily output using machine learning
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 03 July 2023, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Calibrated river-level estimation from river cameras using convolutional neural networks
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 04 May 2023, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Learning the spatiotemporal relationship between wind and significant wave height using deep learning
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 15 February 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Ocean wave climate has a significant impact on near-shore and off-shore human activities, and its characterization can help in the design of ocean structures such as wave energy converters and sea dikes. Therefore, engineers need long time series of ocean wave parameters. Numerical models are a valuable source of ocean wave data; however, they are computationally expensive. Consequently, statistical and data-driven approaches have gained increasing interest in recent decades. This work investigates the spatiotemporal relationship between North Atlantic wind and significant wave height (
 $ {H}_s $) at an off-shore location in the Bay of Biscay, using a two-stage deep learning model. The first step uses convolutional neural networks to extract the spatial features that contribute to
$ {H}_s $) at an off-shore location in the Bay of Biscay, using a two-stage deep learning model. The first step uses convolutional neural networks to extract the spatial features that contribute to  $ {H}_s $. Then, long short-term memory is used to learn the long-term temporal dependencies between wind and waves.
$ {H}_s $. Then, long short-term memory is used to learn the long-term temporal dependencies between wind and waves.


Chapter 12 - Machine Learning: From Expert Systems to Deep Learning
- from Part III - Applications
-
- Book:
- Cognitive Science
- Published online:
- 10 November 2022
- Print publication:
- 10 November 2022, pp 231-250
-
- Chapter
- Export citation
Weed detection to weed recognition: reviewing 50 years of research to identify constraints and opportunities for large-scale cropping systems
-
- Journal:
- Weed Technology / Volume 36 / Issue 6 / December 2022
- Published online by Cambridge University Press:
- 02 November 2022, pp. 741-757
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predicting years with extremely low gross primary production from daily weather data using Convolutional Neural Networks
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 13 April 2022, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Understanding the meteorological drivers of extreme impacts in social or environmental systems is important to better quantify current and project future climate risks. Impacts are typically an aggregated response to many different interacting drivers at various temporal scales, rendering such driver identification a challenging task. Machine learning–based approaches, such as deep neural networks, may be able to address this task but require large training datasets. Here, we explore the ability of Convolutional Neural Networks (CNNs) to predict years with extremely low gross primary production (GPP) from daily weather data in three different vegetation types. To circumvent data limitations in observations, we simulate 100,000 years of daily weather with a weather generator for three different geographical sites and subsequently simulate vegetation dynamics with a complex vegetation model. For each resulting vegetation distribution, we then train two different CNNs to classify daily weather data (temperature, precipitation, and radiation) into years with extremely low GPP and normal years. Overall, prediction accuracy is very good if the monthly or yearly GPP values are used as an intermediate training target (area under the precision-recall curve AUC
 $ \ge $ 0.9). The best prediction accuracy is found in tropical forests, with temperate grasslands and boreal forests leading to comparable results. Prediction accuracy is strongly reduced when binary classification is used directly. Furthermore, using daily GPP during training does not improve the predictive power. We conclude that CNNs are able to predict extreme impacts from complex meteorological drivers if sufficient data are available.
$ \ge $ 0.9). The best prediction accuracy is found in tropical forests, with temperate grasslands and boreal forests leading to comparable results. Prediction accuracy is strongly reduced when binary classification is used directly. Furthermore, using daily GPP during training does not improve the predictive power. We conclude that CNNs are able to predict extreme impacts from complex meteorological drivers if sufficient data are available.
POINT AND INTERVAL FORECASTS OF DEATH RATES USING NEURAL NETWORKS
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 03 December 2021, pp. 333-360
- Print publication:
- January 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NEIGHBOURING PREDICTION FOR MORTALITY
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 12 May 2021, pp. 689-718
- Print publication:
- September 2021
-
- Article
- Export citation
Automatic analysis of insurance reports through deep neural networks to identify severe claims
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 09 March 2021, pp. 42-67
-
- Article
- Export citation
