Let  ${\mathbb K}$ be an algebraically bounded structure, and let T be its theory. If T is model complete, then the theory of
${\mathbb K}$ be an algebraically bounded structure, and let T be its theory. If T is model complete, then the theory of  ${\mathbb K}$ endowed with a derivation, denoted by
${\mathbb K}$ endowed with a derivation, denoted by  $T^{\delta }$, has a model completion. Additionally, we prove that if the theory T is stable/NIP then the model completion of
$T^{\delta }$, has a model completion. Additionally, we prove that if the theory T is stable/NIP then the model completion of  $T^{\delta }$ is also stable/NIP. Similar results hold for the theory with several derivations, either commuting or non-commuting.
$T^{\delta }$ is also stable/NIP. Similar results hold for the theory with several derivations, either commuting or non-commuting.
In this paper, we apply the theory of algebraic cohomology to study the amenability of Thompson’s group 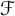 $\mathcal {F}$. We introduce the notion of unique factorization semigroup which contains Thompson’s semigroup
$\mathcal {F}$. We introduce the notion of unique factorization semigroup which contains Thompson’s semigroup 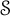 $\mathcal {S}$ and the free semigroup
$\mathcal {S}$ and the free semigroup 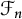 $\mathcal {F}_n$ on n (
$\mathcal {F}_n$ on n (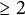 $\geq 2$) generators. Let
$\geq 2$) generators. Let 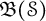 $\mathfrak {B}(\mathcal {S})$ and
$\mathfrak {B}(\mathcal {S})$ and 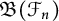 $\mathfrak {B}(\mathcal {F}_n)$ be the Banach algebras generated by the left regular representations of
$\mathfrak {B}(\mathcal {F}_n)$ be the Banach algebras generated by the left regular representations of 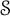 $\mathcal {S}$ and
$\mathcal {S}$ and 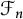 $\mathcal {F}_n$, respectively. We prove that all derivations on
$\mathcal {F}_n$, respectively. We prove that all derivations on 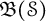 $\mathfrak {B}(\mathcal {S})$ and
$\mathfrak {B}(\mathcal {S})$ and 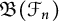 $\mathfrak {B}(\mathcal {F}_n)$ are automatically continuous, and every derivation on
$\mathfrak {B}(\mathcal {F}_n)$ are automatically continuous, and every derivation on 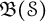 $\mathfrak {B}(\mathcal {S})$ is induced by a bounded linear operator in
$\mathfrak {B}(\mathcal {S})$ is induced by a bounded linear operator in 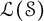 $\mathcal {L}(\mathcal {S})$, the weak-operator closed Banach algebra consisting of all bounded left convolution operators on
$\mathcal {L}(\mathcal {S})$, the weak-operator closed Banach algebra consisting of all bounded left convolution operators on 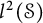 $l^2(\mathcal {S})$. Moreover, we prove that the first continuous Hochschild cohomology group of
$l^2(\mathcal {S})$. Moreover, we prove that the first continuous Hochschild cohomology group of 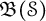 $\mathfrak {B}(\mathcal {S})$ with coefficients in
$\mathfrak {B}(\mathcal {S})$ with coefficients in 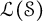 $\mathcal {L}(\mathcal {S})$ vanishes. These conclusions provide positive indications for the left amenability of Thompson’s semigroup.
$\mathcal {L}(\mathcal {S})$ vanishes. These conclusions provide positive indications for the left amenability of Thompson’s semigroup.



