This article examines large-time behaviour of finite-state mean-field interacting particle systems. Our first main result is a sharp estimate (in the exponential scale) of the time required for convergence of the empirical measure process of the N-particle system to its invariant measure; we show that when time is of the order
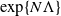 $\exp\{N\Lambda\}$
for a suitable constant
$\exp\{N\Lambda\}$
for a suitable constant
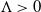 $\Lambda > 0$
, the process has mixed well and it is close to its invariant measure. We then obtain large-N asymptotics of the second-largest eigenvalue of the generator associated with the empirical measure process when it is reversible with respect to its invariant measure. We show that its absolute value scales as
$\Lambda > 0$
, the process has mixed well and it is close to its invariant measure. We then obtain large-N asymptotics of the second-largest eigenvalue of the generator associated with the empirical measure process when it is reversible with respect to its invariant measure. We show that its absolute value scales as
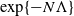 $\exp\{{-}N\Lambda\}$
. The main tools used in establishing our results are the large deviation properties of the empirical measure process from its large-N limit. As an application of the study of large-time behaviour, we also show convergence of the empirical measure of the system of particles to a global minimum of a certain ‘entropy’ function when particles are added over time in a controlled fashion. The controlled addition of particles is analogous to the cooling schedule associated with the search for a global minimum of a function using the simulated annealing algorithm.
$\exp\{{-}N\Lambda\}$
. The main tools used in establishing our results are the large deviation properties of the empirical measure process from its large-N limit. As an application of the study of large-time behaviour, we also show convergence of the empirical measure of the system of particles to a global minimum of a certain ‘entropy’ function when particles are added over time in a controlled fashion. The controlled addition of particles is analogous to the cooling schedule associated with the search for a global minimum of a function using the simulated annealing algorithm.
Let M be acomplete Riemannian manifold, M ∈ ℕ andp ≥ 1. Weprove that almost everywhere on x = (x1,...,xN) ∈ MNfor Lebesgue measure in MN, the measure \hbox{$\di \mu(x)=\f1N\sum_{k=1}^N\d_{x_k}$}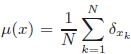 has a unique p–mean ep(x).As a consequence, if X = (X1,...,XN)is a MN-valued randomvariable with absolutely continuous law, then almost surely μ(X(ω)) has aunique p–mean. In particular if (Xn)n ≥ 1is an independent sample of an absolutely continuous law in M, then the processep,n(ω) = ep(X1(ω),...,Xn(ω))is well-defined. Assume M is compact and consider a probability measureν inM. Usingpartial simulated annealing, we define a continuous semimartingale which converges inprobability to the set of minimizers of the integral of distance at power p with respect toν. When theset is a singleton, it converges to the p–mean.
has a unique p–mean ep(x).As a consequence, if X = (X1,...,XN)is a MN-valued randomvariable with absolutely continuous law, then almost surely μ(X(ω)) has aunique p–mean. In particular if (Xn)n ≥ 1is an independent sample of an absolutely continuous law in M, then the processep,n(ω) = ep(X1(ω),...,Xn(ω))is well-defined. Assume M is compact and consider a probability measureν inM. Usingpartial simulated annealing, we define a continuous semimartingale which converges inprobability to the set of minimizers of the integral of distance at power p with respect toν. When theset is a singleton, it converges to the p–mean.

