
22 results
11 - Nonparametric Methods and Machine Learning
-
- Book:
- Time Series for Economics and Finance
- Published online:
- 19 December 2024
- Print publication:
- 19 December 2024, pp 303-346
-
- Chapter
- Export citation
Comparative proteomic analysis of hybrid maize MR2008 and its parental lines
-
- Journal:
- The Journal of Agricultural Science / Volume 159 / Issue 7-8 / September 2021
- Published online by Cambridge University Press:
- 12 January 2022, pp. 570-579
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
6 - Appendix
-
- Book:
- Singularly Perturbed Methods for Nonlinear Elliptic Problems
- Published online:
- 28 January 2021
- Print publication:
- 18 February 2021, pp 205-239
-
- Chapter
- Export citation
11 - Linear Maps between Normed Spaces
- from Part III - Hilbert Spaces
-
- Book:
- An Introduction to Functional Analysis
- Published online:
- 21 March 2020
- Print publication:
- 12 March 2020, pp 137-152
-
- Chapter
- Export citation
17 - Gaussian Measures, Cylinder Measures, and Fields on B
- from Part IV - Game Theoretic Approach on Banach Spaces
-
- Book:
- Operator-Adapted Wavelets, Fast Solvers, and Numerical Homogenization
- Published online:
- 10 October 2019
- Print publication:
- 24 October 2019, pp 347-359
-
- Chapter
- Export citation
10 - Hierarchical Games
- from Part II - The Game Theoretic Approach
-
- Book:
- Operator-Adapted Wavelets, Fast Solvers, and Numerical Homogenization
- Published online:
- 10 October 2019
- Print publication:
- 24 October 2019, pp 137-148
-
- Chapter
- Export citation
24 - Dense Kernel Matrices
- from Part V - Applications, Developments, and Open Problems
-
- Book:
- Operator-Adapted Wavelets, Fast Solvers, and Numerical Homogenization
- Published online:
- 10 October 2019
- Print publication:
- 24 October 2019, pp 421-426
-
- Chapter
- Export citation
13 - Other methods of estimation
- from Part B - Estimation And Inference
-
- Book:
- Statistics
- Published online:
- 11 June 2020
- Print publication:
- 08 November 2018, pp 551-604
-
- Chapter
- Export citation
Coaxer Lattices
-
- Journal:
- Canadian Mathematical Bulletin / Volume 60 / Issue 2 / 01 June 2017
- Published online by Cambridge University Press:
- 20 November 2018, pp. 372-380
- Print publication:
- 01 June 2017
-
- Article
-
- You have access
- Export citation
Recursive bias estimation for multivariate regressionsmoothers
-
- Journal:
- ESAIM: Probability and Statistics / Volume 18 / 2014
- Published online by Cambridge University Press:
- 10 October 2014, pp. 483-502
- Print publication:
- 2014
-
- Article
- Export citation
STRONGLY ORTHODOX CONGRUENCES ON AN
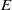 $E$-INVERSIVE SEMIGROUP
$E$-INVERSIVE SEMIGROUP
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 96 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 216-230
- Print publication:
- April 2014
-
- Article
-
- You have access
- Export citation
-
In this paper we investigate some subclasses of strongly regular congruences on an
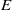 $E$-inversive semigroup
$E$-inversive semigroup 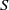 $S$. We describe the minimum and the maximum strongly orthodox congruences on
$S$. We describe the minimum and the maximum strongly orthodox congruences on 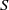 $S$ whose characteristic trace coincides with the characteristic trace of given congruences and, in each case, we present an alternative characterization for them. A description of all strongly orthodox congruences on
$S$ whose characteristic trace coincides with the characteristic trace of given congruences and, in each case, we present an alternative characterization for them. A description of all strongly orthodox congruences on 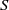 $S$ with characteristic trace
$S$ with characteristic trace  $\tau $ is given. Further, we investigate the kernel relation of strongly orthodox congruences on an
$\tau $ is given. Further, we investigate the kernel relation of strongly orthodox congruences on an 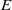 $E$-inversive semigroup and give the least and the greatest element in the class of the same kernel with a given congruence.
$E$-inversive semigroup and give the least and the greatest element in the class of the same kernel with a given congruence.
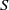
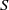
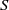

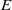
REGULAR CONGRUENCES ON AN IDEMPOTENT-REGULAR-SURJECTIVE SEMIGROUP
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 88 / Issue 2 / October 2013
- Published online by Cambridge University Press:
- 30 July 2013, pp. 190-196
- Print publication:
- October 2013
-
- Article
-
- You have access
- Export citation
-
A semigroup
 $S$ is called idempotent-surjective (respectively, regular-surjective) if whenever
$S$ is called idempotent-surjective (respectively, regular-surjective) if whenever 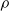 $\rho $ is a congruence on
$\rho $ is a congruence on 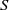 $S$ and
$S$ and 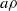 $a\rho $ is idempotent (respectively, regular) in
$a\rho $ is idempotent (respectively, regular) in 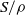 $S/ \rho $, then there is
$S/ \rho $, then there is 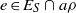 $e\in {E}_{S} \cap a\rho $ (respectively,
$e\in {E}_{S} \cap a\rho $ (respectively, 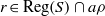 $r\in \mathrm{Reg} (S)\cap a\rho $), where
$r\in \mathrm{Reg} (S)\cap a\rho $), where 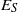 ${E}_{S} $ (respectively,
${E}_{S} $ (respectively, 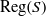 $\mathrm{Reg} (S)$) denotes the set of all idempotents (respectively, regular elements) of
$\mathrm{Reg} (S)$) denotes the set of all idempotents (respectively, regular elements) of 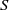 $S$. Moreover, a semigroup
$S$. Moreover, a semigroup 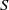 $S$ is said to be idempotent-regular-surjective if it is both idempotent-surjective and regular-surjective. We show that any regular congruence on an idempotent-regular-surjective (respectively, regular-surjective) semigroup is uniquely determined by its kernel and trace (respectively, the set of equivalence classes containing idempotents). Finally, we prove that all structurally regular semigroups are idempotent-regular-surjective.
$S$ is said to be idempotent-regular-surjective if it is both idempotent-surjective and regular-surjective. We show that any regular congruence on an idempotent-regular-surjective (respectively, regular-surjective) semigroup is uniquely determined by its kernel and trace (respectively, the set of equivalence classes containing idempotents). Finally, we prove that all structurally regular semigroups are idempotent-regular-surjective.

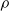
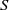
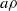
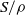
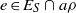
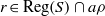
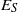
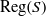
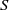
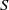
PRESENTATIONS OF INVERSE SEMIGROUPS, THEIR KERNELS AND EXTENSIONS
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 90 / Issue 3 / June 2011
- Published online by Cambridge University Press:
- 08 July 2011, pp. 289-316
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
A Hilbert inequality and an Euler-Maclaurin summation formula
-
- Journal:
- The ANZIAM Journal / Volume 48 / Issue 3 / January 2007
- Published online by Cambridge University Press:
- 17 February 2009, pp. 419-431
-
- Article
-
- You have access
- Export citation
Pre-harvest stress cracks in maize (Zea mays L.) kernels as characterized by visual, X-ray and low temperature scanning electron microscopical analysis: effect on kernel quality
-
- Journal:
- Seed Science Research / Volume 9 / Issue 3 / March 1999
- Published online by Cambridge University Press:
- 22 February 2007, pp. 227-236
-
- Article
- Export citation
Asymptotics for the Lp -deviation of the variance estimator under diffusion
-
- Journal:
- ESAIM: Probability and Statistics / Volume 8 / August 2004
- Published online by Cambridge University Press:
- 15 September 2004, pp. 132-149
- Print publication:
- August 2004
-
- Article
- Export citation
-
We consider a diffusion process X t smoothed with (small)sampling parameter ε. As in Berzin, León and Ortega(2001), we consider a kernel estimate $\widehat{\alpha}_{\varepsilon}$
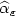 with window h(ε) of afunction α of its variance. In order to exhibit globaltests of hypothesis, we derive here central limit theorems forthe Lp deviations such as \[ \frac1{\sqrt{h}}\left(\frac{h}\varepsilon\right)^{\frac{p}2}\left(\left\|\widehat{\alpha}_{\varepsilon}-{\alpha}\right\|_p^p-\mbox{I E}\left\|\widehat{\alpha}_{\varepsilon}-{\alpha}\right\|_p^p\right).\]
with window h(ε) of afunction α of its variance. In order to exhibit globaltests of hypothesis, we derive here central limit theorems forthe Lp deviations such as \[ \frac1{\sqrt{h}}\left(\frac{h}\varepsilon\right)^{\frac{p}2}\left(\left\|\widehat{\alpha}_{\varepsilon}-{\alpha}\right\|_p^p-\mbox{I E}\left\|\widehat{\alpha}_{\varepsilon}-{\alpha}\right\|_p^p\right).\] 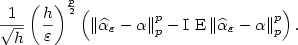
Narrating in protective order interviews: A source of interactional trouble
-
- Journal:
- Language in Society / Volume 31 / Issue 3 / July 2002
- Published online by Cambridge University Press:
- 06 September 2002, pp. 383-418
- Print publication:
- July 2002
-
- Article
- Export citation
Super-Efficient Prediction Based on High-Quality Marker Information
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 30 / Issue 2 / November 2000
- Published online by Cambridge University Press:
- 29 August 2014, pp. 295-303
- Print publication:
- November 2000
-
- Article
-
- You have access
- Export citation
-
Nielsen (1999) showed the surprising fact that a nonparametric one-dimensional hazard as a function of time can be estimated
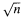 -consistently if a high quality marker is observed. In this paper we show that the hazard relevant for predicting remaining duration time, given the current status of a high quality marker, can be estimated -consistently if a Markov type property holds for the high quality marker.
-consistently if a high quality marker is observed. In this paper we show that the hazard relevant for predicting remaining duration time, given the current status of a high quality marker, can be estimated -consistently if a Markov type property holds for the high quality marker.
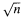 -consistently if a high quality marker is observed. In this paper we show that the hazard relevant for predicting remaining duration time, given the current status of a high quality marker, can be estimated
-consistently if a high quality marker is observed. In this paper we show that the hazard relevant for predicting remaining duration time, given the current status of a high quality marker, can be estimated Selection of nest trees by southern flying squirrels (Sciuridae: Glaucomys volans) in Arkansas
-
- Journal:
- Journal of Zoology / Volume 248 / Issue 3 / July 1999
- Published online by Cambridge University Press:
- 01 July 1999, pp. 369-377
- Print publication:
- July 1999
-
- Article
- Export citation
Resolvent operators of Markov processes and their applications in the control of a finite dam
-
- Journal:
- Journal of Applied Probability / Volume 26 / Issue 2 / June 1989
- Published online by Cambridge University Press:
- 14 July 2016, pp. 314-324
- Print publication:
- June 1989
-
- Article
- Export citation
-
The resolvent operators of the following two processes are obtained: (a) the bivariate Markov process W = (X, Y), where Y(t) is an irreducible Markov chain and X(t) is its integral, and (b) the geometric Wiener process G(t) = exp{B(t} where B(t) is a Wiener process with non-negative drift μ and variance parameter σ2. These results are then used via a limiting procedure to determine the long-run average cost per unit time of operating a finite dam where the input process is either X(t) or G(t). The system is controlled by a
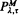 policy (Attia [1], Lam [6]).
policy (Attia [1], Lam [6]).
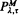 policy (Attia [1], Lam [6]).
policy (Attia [1], Lam [6]).