Given a spectrally negative Lévy process, we predict, in an
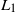 $L_1$
sense, the last passage time of the process below zero before an independent exponential time. This optimal prediction problem generalises [2], where the infinite-horizon problem is solved. Using a similar argument as that in [24], we show that this optimal prediction problem is equivalent to solving an optimal prediction problem in a finite-horizon setting. Surprisingly (unlike the infinite-horizon problem), an optimal stopping time is based on a curve that is killed at the moment the mean of the exponential time is reached. That is, an optimal stopping time is the first time the process crosses above a non-negative, continuous, and non-increasing curve depending on time. This curve and the value function are characterised as a solution of a system of nonlinear integral equations which can be understood as a generalisation of the free boundary equations (see e.g. [21, Chapter IV.14.1]) in the presence of jumps. As an example, we numerically calculate this curve in the Brownian motion case and for a compound Poisson process with exponential-sized jumps perturbed by a Brownian motion.
$L_1$
sense, the last passage time of the process below zero before an independent exponential time. This optimal prediction problem generalises [2], where the infinite-horizon problem is solved. Using a similar argument as that in [24], we show that this optimal prediction problem is equivalent to solving an optimal prediction problem in a finite-horizon setting. Surprisingly (unlike the infinite-horizon problem), an optimal stopping time is based on a curve that is killed at the moment the mean of the exponential time is reached. That is, an optimal stopping time is the first time the process crosses above a non-negative, continuous, and non-increasing curve depending on time. This curve and the value function are characterised as a solution of a system of nonlinear integral equations which can be understood as a generalisation of the free boundary equations (see e.g. [21, Chapter IV.14.1]) in the presence of jumps. As an example, we numerically calculate this curve in the Brownian motion case and for a compound Poisson process with exponential-sized jumps perturbed by a Brownian motion.
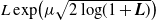 ${L}\exp\bigl(\mu\sqrt{2\log\!(1+\textbf{L})}\bigr)$
-integrable reward process
${L}\exp\bigl(\mu\sqrt{2\log\!(1+\textbf{L})}\bigr)$
-integrable reward process
In this paper we study a class of optimal stopping problems under g-expectation, that is, the cost function is described by the solution of backward stochastic differential equations (BSDEs). Primarily, we assume that the reward process is
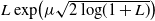 $L\exp\bigl(\mu\sqrt{2\log\!(1+L)}\bigr)$
-integrable with
$L\exp\bigl(\mu\sqrt{2\log\!(1+L)}\bigr)$
-integrable with
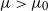 $\mu>\mu_0$
for some critical value
$\mu>\mu_0$
for some critical value
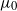 $\mu_0$
. This integrability is weaker than
$\mu_0$
. This integrability is weaker than
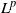 $L^p$
-integrability for any
$L^p$
-integrability for any
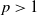 $p>1$
, so it covers a comparatively wide class of optimal stopping problems. To reach our goal, we introduce a class of reflected backward stochastic differential equations (RBSDEs) with
$p>1$
, so it covers a comparatively wide class of optimal stopping problems. To reach our goal, we introduce a class of reflected backward stochastic differential equations (RBSDEs) with
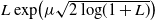 $L\exp\bigl(\mu\sqrt{2\log\!(1+L)}\bigr)$
-integrable parameters. We prove the existence, uniqueness, and comparison theorem for these RBSDEs under Lipschitz-type assumptions on the coefficients. This allows us to characterize the value function of our optimal stopping problem as the unique solution of such RBSDEs.
$L\exp\bigl(\mu\sqrt{2\log\!(1+L)}\bigr)$
-integrable parameters. We prove the existence, uniqueness, and comparison theorem for these RBSDEs under Lipschitz-type assumptions on the coefficients. This allows us to characterize the value function of our optimal stopping problem as the unique solution of such RBSDEs.
The Chow–Robbins game is a classical, still partly unsolved, stopping problem introduced by Chow and Robbins in 1965. You repeatedly toss a fair coin. After each toss, you decide whether you take the fraction of heads up to now as a payoff, otherwise you continue. As a more general stopping problem this reads 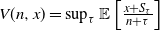 $V(n,x) = \sup_{\tau }\mathbb{E} \left [ \frac{x + S_\tau}{n+\tau}\right]$
, where S is a random walk. We give a tight upper bound for V when S has sub-Gaussian increments by using the analogous time-continuous problem with a standard Brownian motion as the driving process. For the Chow–Robbins game we also give a tight lower bound and use these to calculate, on the integers, the complete continuation and the stopping set of the problem for
$V(n,x) = \sup_{\tau }\mathbb{E} \left [ \frac{x + S_\tau}{n+\tau}\right]$
, where S is a random walk. We give a tight upper bound for V when S has sub-Gaussian increments by using the analogous time-continuous problem with a standard Brownian motion as the driving process. For the Chow–Robbins game we also give a tight lower bound and use these to calculate, on the integers, the complete continuation and the stopping set of the problem for 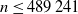 $n\leq 489\,241$
.
$n\leq 489\,241$
.
We consider the optimal prediction problem of stopping a spectrally negative Lévy process as close as possible to a given distance 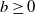 $b \geq 0$ from its ultimate supremum, under a squared-error penalty function. Under some mild conditions, the solution is fully and explicitly characterised in terms of scale functions. We find that the solution has an interesting non-trivial structure: if b is larger than a certain threshold then it is optimal to stop as soon as the difference between the running supremum and the position of the process exceeds a certain level (less than b), while if b is smaller than this threshold then it is optimal to stop immediately (independent of the running supremum and position of the process). We also present some examples.
$b \geq 0$ from its ultimate supremum, under a squared-error penalty function. Under some mild conditions, the solution is fully and explicitly characterised in terms of scale functions. We find that the solution has an interesting non-trivial structure: if b is larger than a certain threshold then it is optimal to stop as soon as the difference between the running supremum and the position of the process exceeds a certain level (less than b), while if b is smaller than this threshold then it is optimal to stop immediately (independent of the running supremum and position of the process). We also present some examples.
We present a discrete-type approximation scheme to solve continuous-time optimal stopping problems based on fully non-Markovian continuous processes adapted to the Brownian motion filtration. The approximations satisfy suitable variational inequalities which allow us to construct  $\varepsilon$
-optimal stopping times and optimal values in full generality. Explicit rates of convergence are presented for optimal values based on reward functionals of path-dependent stochastic differential equations driven by fractional Brownian motion. In particular, the methodology allows us to design concrete Monte Carlo schemes for non-Markovian optimal stopping time problems as demonstrated in the companion paper by Bezerra et al.
$\varepsilon$
-optimal stopping times and optimal values in full generality. Explicit rates of convergence are presented for optimal values based on reward functionals of path-dependent stochastic differential equations driven by fractional Brownian motion. In particular, the methodology allows us to design concrete Monte Carlo schemes for non-Markovian optimal stopping time problems as demonstrated in the companion paper by Bezerra et al.

