
This study was an approximate replication of Rothman (2011),examining the determiner phrase syntax of a large sample (n = 211) of L3 learners of Portuguese who spoke English and Spanish. Rothman (2011) investigated whether L3 Italian or Brazilian Portuguese speakers are differently impacted by another known Romance Language, if it was their L1 or L2. The original study concluded that groups did not perform differently on experimental tasks on the basis of a null effect, and that the typological similarity of Spanish, Portuguese, or Italian predicts transfer in the initial stages of L3 acquisition. The present replication recreated all materials, which were unavailable, and examined the same population and questions. However, rather than examining L3 Italian and L3 Brazilian Portuguese, the present work maintained a constant L3 Portuguese. Learners were divided into two groups in a mirror-image design (n = 96 L1 English-L2 Spanish, n = 115 L1 Spanish-L2 English), and data were collected online. Like the original study, there was no main effect of group in any of the two-way analyses of variance. However, results show that it should not be assumed that experimental groups behave equivalently based on a null effect: Of the four total post hoc tests of equivalence, only two were significant when the equivalence bounds were set at a small effect size (d = 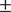 $ \pm $ .4). Ultimately, it is argued that determining the smallest effect size of interest and subsequent equivalence testing are necessary to answer key questions in the field of L3 acquisition.
$ \pm $ .4). Ultimately, it is argued that determining the smallest effect size of interest and subsequent equivalence testing are necessary to answer key questions in the field of L3 acquisition.

