Many screening tests dichotomize a measurement to classify subjects. Typically a cut-off value is chosen in a way that allows identification of an acceptable number of cases relative to a reference procedure, but does not produce too many false positives at the same time. Thus for the same sample many pairs of sensitivities and false positive rates result as the cut-off is varied. The curve of these points is called the receiver operating characteristic (ROC) curve. One goal of diagnostic meta-analysis is to integrate ROC curves and arrive at a summary ROC (SROC) curve. Holling, Böhning, and Böhning (Psychometrika 77:106–126, 2012a) demonstrated that finite semiparametric mixtures can describe the heterogeneity in a sample of Lehmann ROC curves well; this approach leads to clusters of SROC curves of a particular shape. We extend this work with the help of the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$t_{\alpha }$$\end{document}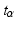 transformation, a flexible family of transformations for proportions. A collection of SROC curves is constructed that approximately contains the Lehmann family but in addition allows the modeling of shapes beyond the Lehmann ROC curves. We introduce two rationales for determining the shape from the data. Using the fact that each curve corresponds to a natural univariate measure of diagnostic accuracy, we show how covariate adjusted mixtures lead to a meta-regression on SROC curves. Three worked examples illustrate the method.
transformation, a flexible family of transformations for proportions. A collection of SROC curves is constructed that approximately contains the Lehmann family but in addition allows the modeling of shapes beyond the Lehmann ROC curves. We introduce two rationales for determining the shape from the data. Using the fact that each curve corresponds to a natural univariate measure of diagnostic accuracy, we show how covariate adjusted mixtures lead to a meta-regression on SROC curves. Three worked examples illustrate the method.
A scaled difference test statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\tilde{T}{}_{d}$\end{document}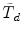 that can be computed from standard software of structural equation models (SEM) by hand calculations was proposed in Satorra and Bentler (Psychometrika 66:507–514, 2001). The statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\tilde{T}_{d}$\end{document}
that can be computed from standard software of structural equation models (SEM) by hand calculations was proposed in Satorra and Bentler (Psychometrika 66:507–514, 2001). The statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\tilde{T}_{d}$\end{document}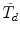 is asymptotically equivalent to the scaled difference test statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\bar{T}_{d}$\end{document}
is asymptotically equivalent to the scaled difference test statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\bar{T}_{d}$\end{document}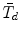 introduced in Satorra (Innovations in Multivariate Statistical Analysis: A Festschrift for Heinz Neudecker, pp. 233–247, 2000), which requires more involved computations beyond standard output of SEM software. The test statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\tilde{T}_{d}$\end{document}
introduced in Satorra (Innovations in Multivariate Statistical Analysis: A Festschrift for Heinz Neudecker, pp. 233–247, 2000), which requires more involved computations beyond standard output of SEM software. The test statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\tilde{T}_{d}$\end{document}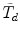 has been widely used in practice, but in some applications it is negative due to negativity of its associated scaling correction. Using the implicit function theorem, this note develops an improved scaling correction leading to a new scaled difference statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\bar{T}_{d}$\end{document}
has been widely used in practice, but in some applications it is negative due to negativity of its associated scaling correction. Using the implicit function theorem, this note develops an improved scaling correction leading to a new scaled difference statistic \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\bar{T}_{d}$\end{document}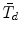 that avoids negative chi-square values.
that avoids negative chi-square values.

