Refine search
Actions for selected content:
1038 results
2 - Study Design, Statistics, and Open Science
- from Part I - Philosophical Foundations
-
- Book:
- Fundamentals of Biological Psychology
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026, pp 35-64
-
- Chapter
- Export citation

A Hands-On Introduction to Data Science with Python
- Coming soon
-
- Expected online publication date:
- February 2026
- Print publication:
- 22 January 2026
-
- Textbook
- Export citation

A Hands-On Introduction to Data Science with R
- Coming soon
-
- Expected online publication date:
- February 2026
- Print publication:
- 22 January 2026
-
- Textbook
- Export citation

Introduction to Machine Learning
- From Math to Code
- Coming soon
-
- Expected online publication date:
- February 2026
- Print publication:
- 18 December 2025
-
- Textbook
- Export citation
Potential and Pitfalls of Audio as Data for Political Research: Alignment, Features, and Classification Models
-
- Journal:
- Political Analysis , First View
- Published online by Cambridge University Press:
- 30 January 2026, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessment of non-intrusive sensing in wall-bounded turbulence through explainable deep learning
-
- Journal:
- Journal of Fluid Mechanics / Volume 1028 / 10 February 2026
- Published online by Cambridge University Press:
- 30 January 2026, A19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this work we present a framework to explain the prediction of the velocity fluctuation at a certain wall-normal distance from wall measurements with a deep-learning model. For this purpose, we apply the deep-SHAP (deep Shapley additive explanations) method to explain the velocity fluctuation prediction in wall-parallel planes in a turbulent open channel at a friction Reynolds number
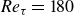 ${\textit{Re}}_\tau =180$. The explainable-deep-learning methodology comprises two stages. The first stage consists of training the estimator. In this case, the velocity fluctuation at a wall-normal distance of 15 wall units is predicted from the wall-shear stress and wall-pressure. In the second stage, the deep-SHAP algorithm is applied to estimate the impact each single grid point has on the output. This analysis calculates an importance field, and then, correlates the high-importance regions calculated through the deep-SHAP algorithm with the wall-pressure and wall-shear stress distributions. The grid points are then clustered to define structures according to their importance. We find that the high-importance clusters exhibit large pressure and shear-stress fluctuations, although generally not corresponding to the highest intensities in the input datasets. Their typical values averaged among these clusters are equal to one to two times their standard deviation and are associated with streak-like regions. These high-importance clusters present a size between 20 and 120 wall units, corresponding to approximately 100 and 600
${\textit{Re}}_\tau =180$. The explainable-deep-learning methodology comprises two stages. The first stage consists of training the estimator. In this case, the velocity fluctuation at a wall-normal distance of 15 wall units is predicted from the wall-shear stress and wall-pressure. In the second stage, the deep-SHAP algorithm is applied to estimate the impact each single grid point has on the output. This analysis calculates an importance field, and then, correlates the high-importance regions calculated through the deep-SHAP algorithm with the wall-pressure and wall-shear stress distributions. The grid points are then clustered to define structures according to their importance. We find that the high-importance clusters exhibit large pressure and shear-stress fluctuations, although generally not corresponding to the highest intensities in the input datasets. Their typical values averaged among these clusters are equal to one to two times their standard deviation and are associated with streak-like regions. These high-importance clusters present a size between 20 and 120 wall units, corresponding to approximately 100 and 600 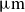 $\unicode{x03BC} \textrm {m}$ for the case of a commercial aircraft.
$\unicode{x03BC} \textrm {m}$ for the case of a commercial aircraft.
Dual evaluation of performance and fairness from machine learning models for non-life insurance pricing
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 29 January 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A machine learning approach using autoencoders to perform quality control on meteorological data
-
- Journal:
- Environmental Data Science / Volume 5 / 2026
- Published online by Cambridge University Press:
- 26 January 2026, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using optimal transport aligned latent embeddings for separated flow analysis
-
- Journal:
- Journal of Fluid Mechanics / Volume 1027 / 25 January 2026
- Published online by Cambridge University Press:
- 16 January 2026, A24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Quantifying differences between flow fields is a key challenge in fluid mechanics, particularly when evaluating the effectiveness of flow control or other problem parameters. Traditional vector metrics, such as the Euclidean distance, provide straightforward pointwise comparisons but can fail to distinguish distributional changes in flow fields. To address this limitation, we employ optimal transport (OT) theory, which is a mathematical framework built on probability and measure theory. By aligning Euclidean distances between flow fields in a latent space learned by an autoencoder with the corresponding OT geodesics, we seek to learn low-dimensional representations of flow fields that are interpretable from the perspective of unbalanced OT. As a demonstration, we utilise this OT-based analysis on separated flows past a NACA 0012 airfoil with periodic heat flux actuation near the leading edge. The cases considered are at a chord-based Reynolds number of 23 000 and a free-stream Mach number of 0.3 for two angles of attack (AoA) of
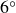 $6^\circ$ and
$6^\circ$ and 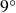 $9^\circ$. For each angle of attack, we identify a two-dimensional embedding that succinctly captures the different effective regimes of flow responses and control performance, characterised by the degree of suppression of the separation bubble and secondary effects from laminarisation and trailing-edge separation. The interpretation of the latent representation was found to be consistent across the two AoA, suggesting that the OT-based latent encoding was capable of extracting physical relationships that are common across the different suites of cases. This study demonstrates the potential utility of optimal transport in the analysis and interpretation of complex flow fields.
$9^\circ$. For each angle of attack, we identify a two-dimensional embedding that succinctly captures the different effective regimes of flow responses and control performance, characterised by the degree of suppression of the separation bubble and secondary effects from laminarisation and trailing-edge separation. The interpretation of the latent representation was found to be consistent across the two AoA, suggesting that the OT-based latent encoding was capable of extracting physical relationships that are common across the different suites of cases. This study demonstrates the potential utility of optimal transport in the analysis and interpretation of complex flow fields.
Efficient reduced-order modelling based on HODMD to predict intraventricular flow dynamics
-
- Journal:
- Flow: Applications of Fluid Mechanics / Volume 6 / 2026
- Published online by Cambridge University Press:
- 15 January 2026, E2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Accurate and efficient modelling of cardiac blood flow is crucial for advancing data-driven tools in cardiovascular research and clinical applications. Recently, the accuracy and availability of computational fluid dynamics methodologies for simulating intraventricular flow have increased. However, these methods remain complex and computationally costly. This study presents a reduced-order model (ROM) based on higher-order dynamic mode decomposition (HODMD). The proposed approach enables accurate reconstruction and long-term prediction of left ventricle flow fields. The method is tested on two idealized ventricular geometries exhibiting distinct flow regimes to assess its robustness under different hemodynamic conditions. By leveraging a small number of training snapshots and focusing on the dominant periodic components representing the physics of the system, the HODMD-based model accurately reconstructs the flow field over entire cardiac cycles and provides reliable long-term predictions beyond the training window. The reconstruction and prediction errors remain below 5 % for the first geometry and below 10 % for the second, even when using as few as the first three cycles of simulated data, representing the transitory regime. Additionally, the approach reduces computational costs with a speed-up factor of at least
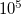 $10^{5}$ compared with full-order simulations, enabling fast surrogate modelling of complex cardiac flows. These results highlight the potential of spectrally constrained HODMD as a robust and interpretable ROM for simulating intraventricular hemodynamics. This approach shows promise for integration in real-time analysis and patient specific models.
$10^{5}$ compared with full-order simulations, enabling fast surrogate modelling of complex cardiac flows. These results highlight the potential of spectrally constrained HODMD as a robust and interpretable ROM for simulating intraventricular hemodynamics. This approach shows promise for integration in real-time analysis and patient specific models.
Super-resolution reconstruction of turbulent flows from a single Lagrangian trajectory
-
- Journal:
- Journal of Fluid Mechanics / Volume 1026 / 10 January 2026
- Published online by Cambridge University Press:
- 12 January 2026, A46
-
- Article
- Export citation
-
We studied the reconstruction of turbulent flow fields from trajectory data recorded by actively migrating Lagrangian agents. We propose a deep-learning model, track-to-flow (T2F), which employs a vision transformer as the encoder to capture the spatiotemporal features of a single agent trajectory, and a convolutional neural network as the decoder to reconstruct the flow field. To enhance the physical consistency of the T2F model, we further incorporate a physics-informed loss function inspired by the framework of physics-informed neural network (PINN), yielding a variant model referred to as T2F+PINN. We first evaluate both models in a laminar cylinder wake flow at a Reynolds number of
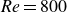 $\textit{Re} = 800$ as a proof of concept. The results show that the T2F model achieves velocity reconstruction accuracy comparable to that of existing flow reconstruction methods, while the T2F+PINN model reduces the normalised error in vorticity reconstruction relative to the T2F model. We then apply the models in turbulent Rayleigh–Bénard convection at a Rayleigh number of
$\textit{Re} = 800$ as a proof of concept. The results show that the T2F model achieves velocity reconstruction accuracy comparable to that of existing flow reconstruction methods, while the T2F+PINN model reduces the normalised error in vorticity reconstruction relative to the T2F model. We then apply the models in turbulent Rayleigh–Bénard convection at a Rayleigh number of 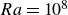 $Ra = 10^{8}$ and a Prandtl number of
$Ra = 10^{8}$ and a Prandtl number of 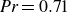 $\textit{Pr} = 0.71$. The results show that the T2F model accurately reconstructs both the velocity and temperature fields, whereas the T2F+PINN model further improves the reconstruction accuracy of gradient-related physical quantities, such as temperature gradients, vorticity and the
$\textit{Pr} = 0.71$. The results show that the T2F model accurately reconstructs both the velocity and temperature fields, whereas the T2F+PINN model further improves the reconstruction accuracy of gradient-related physical quantities, such as temperature gradients, vorticity and the 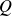 $Q$ value, with a maximum improvement of approximately 60 % compared to the T2F model. Overall, the T2F model is better suited for reconstructing primitive flow variables, while the T2F+PINN model provides advantages in reconstructing gradient-related quantities. Our models open a promising avenue for accurate flow reconstruction from a single Lagrangian trajectory.
$Q$ value, with a maximum improvement of approximately 60 % compared to the T2F model. Overall, the T2F model is better suited for reconstructing primitive flow variables, while the T2F+PINN model provides advantages in reconstructing gradient-related quantities. Our models open a promising avenue for accurate flow reconstruction from a single Lagrangian trajectory.
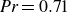
Data-driven detached-eddy simulations based on explicit algebraic stress expressions for turbulent flows
-
- Journal:
- Journal of Fluid Mechanics / Volume 1027 / 25 January 2026
- Published online by Cambridge University Press:
- 12 January 2026, A5
-
- Article
- Export citation
-
This work proposes a data-driven explicit algebraic stress-based detached-eddy simulation (DES) method. Despite the widespread use of data-driven methods in model development for both Reynolds-averaged Navier–Stokes (RANS) and large-eddy simulations (LES), their applications to DES remain limited. The challenge mainly lies in the absence of modelled stress data, the requirement for proper length scales in RANS and LES branches, and the maintenance of a reasonable switching behaviour. The data-driven DES method is constructed based on the algebraic stress equation. The control of RANS/LES switching is achieved through the eddy viscosity in the linear part of the modelled stress, under the
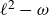 $\ell ^2-\omega$ DES framework. Three model coefficients associated with the pressure–strain terms and the LES length scale are represented by a neural network as functions of scalar invariants of velocity gradient. The neural network is trained using velocity data with the ensemble Kalman method, thereby circumventing the requirement for modelled stress data. Moreover, the baseline coefficient values are incorporated as additional reference data to ensure reasonable switching behaviour. The proposed approach is evaluated on two challenging turbulent flows, i.e. the secondary flow in a square duct and the separated flow over a bump. The trained model achieves significant improvements in predicting mean flow statistics compared with the baseline model. This is attributed to improved predictions of the modelled stress. The trained model also exhibits reasonable switching behaviour, enlarging the LES region to resolve more turbulent structures. Furthermore, the model shows satisfactory generalization capabilities for both cases in similar flow configurations.
$\ell ^2-\omega$ DES framework. Three model coefficients associated with the pressure–strain terms and the LES length scale are represented by a neural network as functions of scalar invariants of velocity gradient. The neural network is trained using velocity data with the ensemble Kalman method, thereby circumventing the requirement for modelled stress data. Moreover, the baseline coefficient values are incorporated as additional reference data to ensure reasonable switching behaviour. The proposed approach is evaluated on two challenging turbulent flows, i.e. the secondary flow in a square duct and the separated flow over a bump. The trained model achieves significant improvements in predicting mean flow statistics compared with the baseline model. This is attributed to improved predictions of the modelled stress. The trained model also exhibits reasonable switching behaviour, enlarging the LES region to resolve more turbulent structures. Furthermore, the model shows satisfactory generalization capabilities for both cases in similar flow configurations.
The role of technology and machine learning to monitor diet in older adults; learning lessons to develop a new prototype
-
- Journal:
- Proceedings of the Nutrition Society , First View
- Published online by Cambridge University Press:
- 07 January 2026, pp. 1-7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Are party families in Europe ideologically coherent today?
-
- Journal:
- European Journal of Political Research / Volume 63 / Issue 3 / August 2024
- Published online by Cambridge University Press:
- 02 January 2026, pp. 1208-1226
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Male and female politicians on Twitter: A machine learning approach
-
- Journal:
- European Journal of Political Research / Volume 60 / Issue 1 / February 2021
- Published online by Cambridge University Press:
- 02 January 2026, pp. 239-251
-
- Article
- Export citation
The Wells-Du Bois Protocol for Machine Learning Bias: Building Critical Quantitative Foundations for Third Sector Scholarship
-
- Journal:
- Voluntas: International Journal of Voluntary and Nonprofit Organizations / Volume 34 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 01 January 2026, pp. 170-184
-
- Article
- Export citation
Terrorists or Persecuted? The Portrayal of Islamic Nonprofits in US Newspapers Post 9/11
-
- Journal:
- Voluntas: International Journal of Voluntary and Nonprofit Organizations / Volume 32 / Issue 5 / October 2021
- Published online by Cambridge University Press:
- 01 January 2026, pp. 1139-1153
-
- Article
- Export citation
Why are the affluent better represented around the world?
-
- Journal:
- European Journal of Political Research / Volume 61 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 01 January 2026, pp. 67-85
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Infrared nanoscopy for subcellular chemical imaging
-
- Journal:
- QRB Discovery / Volume 7 / 2026
- Published online by Cambridge University Press:
- 19 January 2026, e2
- Print publication:
- 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
