
33 results
Almost exact recovery in noisy semi-supervised learning
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 November 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Maximum likelihood estimation for spinal-structured trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 October 2024, pp. 234-268
- Print publication:
- March 2025
-
- Article
-
- You have access
- HTML
- Export citation
-
We investigate some aspects of the problem of the estimation of birth distributions (BDs) in multi-type Galton–Watson trees (MGWs) with unobserved types. More precisely, we consider two-type MGWs called spinal-structured trees. This kind of tree is characterized by a spine of special individuals whose BD
 $\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by
$\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by 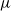 $\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate
$\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate 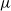 $\mu$ and
$\mu$ and  $\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of
$\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of 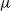 $\mu$ and
$\mu$ and  $\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if
$\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if 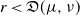 $r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and
$r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and 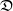 $\mathfrak{D}$ is a divergence measuring the dissimilarity between
$\mathfrak{D}$ is a divergence measuring the dissimilarity between 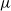 $\mu$ and
$\mu$ and  $\nu$.
$\nu$.

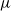
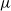

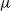

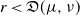
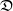
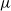

Exact recovery of community detection in k-community Gaussian mixture models
- Part of
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 18 September 2024, pp. 1-33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the community detection problem on a Gaussian mixture model, in which vertices are divided into
 $k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
$k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.

Trajectory fitting estimation for reflected stochastic linear differential equations of a large signal
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 31 October 2023, pp. 741-754
- Print publication:
- September 2024
-
- Article
-
- You have access
- HTML
- Export citation
Self-normalized Cramér moderate deviations for a supercritical Galton–Watson process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1281-1292
- Print publication:
- December 2023
-
- Article
- Export citation
-
Let
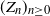 $(Z_n)_{n\geq0}$ be a supercritical Galton–Watson process. Consider the Lotka–Nagaev estimator for the offspring mean. In this paper we establish self-normalized Cramér-type moderate deviations and Berry–Esseen bounds for the Lotka–Nagaev estimator. The results are believed to be optimal or near-optimal.
$(Z_n)_{n\geq0}$ be a supercritical Galton–Watson process. Consider the Lotka–Nagaev estimator for the offspring mean. In this paper we establish self-normalized Cramér-type moderate deviations and Berry–Esseen bounds for the Lotka–Nagaev estimator. The results are believed to be optimal or near-optimal.
Central limit theorem for bifurcating markov chains under L2-ergodic conditions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 15 June 2022, pp. 999-1031
- Print publication:
- December 2022
-
- Article
- Export citation
-
Bifurcating Markov chains (BMCs) are Markov chains indexed by a full binary tree representing the evolution of a trait along a population where each individual has two children. We provide a central limit theorem for additive functionals of BMCs under
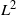 $L^2$
-ergodic conditions with three different regimes. This completes the pointwise approach developed in a previous work. As an application, we study the elementary case of a symmetric bifurcating autoregressive process, which justifies the nontrivial hypothesis considered on the kernel transition of the BMCs. We illustrate in this example the phase transition observed in the fluctuations.
$L^2$
-ergodic conditions with three different regimes. This completes the pointwise approach developed in a previous work. As an application, we study the elementary case of a symmetric bifurcating autoregressive process, which justifies the nontrivial hypothesis considered on the kernel transition of the BMCs. We illustrate in this example the phase transition observed in the fluctuations.
STOCHASTIC MODELLING AND STATISTICAL ANALYSIS OF SPATIAL AND LONG-RANGE DEPENDENT DATA
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 106 / Issue 1 / August 2022
- Published online by Cambridge University Press:
- 10 June 2022, pp. 170-173
- Print publication:
- August 2022
-
- Article
-
- You have access
- HTML
- Export citation
STATISTICAL ANALYSIS OF LONG-RANGE DEPENDENT RANDOM PROCESSES AND FIELDS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 101 / Issue 2 / April 2020
- Published online by Cambridge University Press:
- 08 January 2020, pp. 345-347
- Print publication:
- April 2020
-
- Article
-
- You have access
- Export citation
ASYMPTOTIC BEHAVIORS FOR CORRELATED BERNOULLI MODEL
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 34 / Issue 4 / October 2020
- Published online by Cambridge University Press:
- 11 July 2019, pp. 570-582
-
- Article
- Export citation
-
We consider a class of correlated Bernoulli variables, which have the following form: for some 0 < p < 1,
where 0 ≤ θj ≤ 1,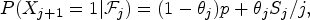 $$\begin{align}{P(X_{j+1}=1 \vert {\cal F}_{j})= (1-\theta_j)p+\theta_jS_j/j,}\end{align}$$
$$\begin{align}{P(X_{j+1}=1 \vert {\cal F}_{j})= (1-\theta_j)p+\theta_jS_j/j,}\end{align}$$ $S_n=\sum _{j=1}^nX_j$ and
$S_n=\sum _{j=1}^nX_j$ and 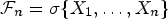 ${\cal F}_n=\sigma \{X_1,\ldots , X_n\}$. The aim of this paper is to establish the strong law of large numbers which extend some known results, and prove the moderate deviation principle for the correlated Bernoulli model.
${\cal F}_n=\sigma \{X_1,\ldots , X_n\}$. The aim of this paper is to establish the strong law of large numbers which extend some known results, and prove the moderate deviation principle for the correlated Bernoulli model.

NONSTANDARD ESTIMATION FOR THE VON MISES FISHER DISTRIBUTION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 97 / Issue 3 / June 2018
- Published online by Cambridge University Press:
- 07 March 2018, pp. 520-522
- Print publication:
- June 2018
-
- Article
-
- You have access
- Export citation
Large deviations for the Ornstein-Uhlenbeck process with shift
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 47 / Issue 3 / September 2015
- Published online by Cambridge University Press:
- 21 March 2016, pp. 880-901
- Print publication:
- September 2015
-
- Article
-
- You have access
- Export citation
Inference for a Nonstationary Self-Exciting Point Process with an Application in Ultra-High Frequency Financial Data Modeling
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 50 / Issue 4 / December 2013
- Published online by Cambridge University Press:
- 30 January 2018, pp. 1006-1024
- Print publication:
- December 2013
-
- Article
-
- You have access
- Export citation
Recursive Identification of Wiener-Hammerstein Systems with Nonparametric Nonlinearity
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 3 / Issue 4 / November 2013
- Published online by Cambridge University Press:
- 28 May 2015, pp. 311-332
- Print publication:
- November 2013
-
- Article
- Export citation
Consistency of Sample Estimates of Risk Averse Stochastic Programs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 50 / Issue 2 / June 2013
- Published online by Cambridge University Press:
- 30 January 2018, pp. 533-541
- Print publication:
- June 2013
-
- Article
-
- You have access
- Export citation
Central Limit Theorems for Law-Invariant Coherent Risk Measures
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 1 / March 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 1-21
- Print publication:
- March 2012
-
- Article
-
- You have access
- Export citation
Efficient Solution of Ordinary Differential Equations with High-Dimensional Parametrized Uncertainty
-
- Journal:
- Communications in Computational Physics / Volume 10 / Issue 2 / August 2011
- Published online by Cambridge University Press:
- 20 August 2015, pp. 253-278
- Print publication:
- August 2011
-
- Article
- Export citation
Asymptotic normality of M-estimators in nonhomogeneous hidden Markov models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue A / August 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 295-306
- Print publication:
- August 2011
-
- Article
-
- You have access
- Export citation
Functional limit theorems for critical processes with immigration
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 39 / Issue 4 / December 2007
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1054-1069
- Print publication:
- December 2007
-
- Article
-
- You have access
- Export citation
-
We consider a critical discrete-time branching process with generation dependent immigration. For the case in which the mean number of immigrating individuals tends to ∞ with the generation number, we prove functional limit theorems for centered and normalized processes. The limiting processes are deterministically time-changed Wiener, with three different covariance functions depending on the behavior of the mean and variance of the number of immigrants. As an application, we prove that the conditional least-squares estimator of the offspring mean is asymptotically normal, which demonstrates an alternative case of normality of the estimator for the process with nondegenerate offspring distribution. The norming factor is
 where α(n) denotes the mean number of immigrating individuals in the nth generation.
where α(n) denotes the mean number of immigrating individuals in the nth generation.
 where α(
where α(Estimation in branching processes with restricted observations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 38 / Issue 4 / December 2006
- Published online by Cambridge University Press:
- 08 September 2016, pp. 1098-1115
- Print publication:
- December 2006
-
- Article
-
- You have access
- Export citation
Fluctuation limit of branching processes with immigration and estimation of the means
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 37 / Issue 2 / June 2005
- Published online by Cambridge University Press:
- 01 July 2016, pp. 523-538
- Print publication:
- June 2005
-
- Article
-
- You have access
- Export citation
