In practice, it is common that a best fitting structural equation model (SEM) is selected from a set of candidate SEMs and inference is conducted conditional on the selected model. Such post-selection inference ignores the model selection uncertainty and yields too optimistic inference. Using the largest candidate model avoids model selection uncertainty but introduces a large variation. Jin and Ankargren (Psychometrika 84:84–104, 2019) proposed to use frequentist model averaging in SEM with continuous data as a compromise between model selection and the full model. They assumed that the true values of the parameters depend on \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$n^{-1/2}$$\end{document}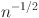 with n being the sample size, which is known as a local asymptotic framework. This paper shows that their results are not directly applicable to SEM with ordinal data. To address this issue, we prove consistency and asymptotic normality of the polychoric correlation estimators under the local asymptotic framework. Then, we propose a new frequentist model averaging estimator and a valid confidence interval that are suitable for ordinal data. Goodness-of-fit test statistics for the model averaging estimator are also derived.
with n being the sample size, which is known as a local asymptotic framework. This paper shows that their results are not directly applicable to SEM with ordinal data. To address this issue, we prove consistency and asymptotic normality of the polychoric correlation estimators under the local asymptotic framework. Then, we propose a new frequentist model averaging estimator and a valid confidence interval that are suitable for ordinal data. Goodness-of-fit test statistics for the model averaging estimator are also derived.
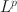 Losses and Related Inference Problems
Losses and Related Inference Problems
Researchers have widely used exploratory factor analysis (EFA) to learn the latent structure underlying multivariate data. Rotation and regularised estimation are two classes of methods in EFA that they often use to find interpretable loading matrices. In this paper, we propose a new family of oblique rotations based on component-wise \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}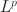 loss functions \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(0 < p\le 1)$$\end{document}
loss functions \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(0 < p\le 1)$$\end{document}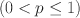 that is closely related to an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}
that is closely related to an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}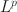 regularised estimator. We develop model selection and post-selection inference procedures based on the proposed rotation method. When the true loading matrix is sparse, the proposed method tends to outperform traditional rotation and regularised estimation methods in terms of statistical accuracy and computational cost. Since the proposed loss functions are nonsmooth, we develop an iteratively reweighted gradient projection algorithm for solving the optimisation problem. We also develop theoretical results that establish the statistical consistency of the estimation, model selection, and post-selection inference. We evaluate the proposed method and compare it with regularised estimation and traditional rotation methods via simulation studies. We further illustrate it using an application to the Big Five personality assessment.
regularised estimator. We develop model selection and post-selection inference procedures based on the proposed rotation method. When the true loading matrix is sparse, the proposed method tends to outperform traditional rotation and regularised estimation methods in terms of statistical accuracy and computational cost. Since the proposed loss functions are nonsmooth, we develop an iteratively reweighted gradient projection algorithm for solving the optimisation problem. We also develop theoretical results that establish the statistical consistency of the estimation, model selection, and post-selection inference. We evaluate the proposed method and compare it with regularised estimation and traditional rotation methods via simulation studies. We further illustrate it using an application to the Big Five personality assessment.
Establishing the invariance property of an instrument (e.g., a questionnaire or test) is a key step for establishing its measurement validity. Measurement invariance is typically assessed by differential item functioning (DIF) analysis, i.e., detecting DIF items whose response distribution depends not only on the latent trait measured by the instrument but also on the group membership. DIF analysis is confounded by the group difference in the latent trait distributions. Many DIF analyses require knowing several anchor items that are DIF-free in order to draw inferences on whether each of the rest is a DIF item, where the anchor items are used to identify the latent trait distributions. When no prior information on anchor items is available, or some anchor items are misspecified, item purification methods and regularized estimation methods can be used. The former iteratively purifies the anchor set by a stepwise model selection procedure, and the latter selects the DIF-free items by a LASSO-type regularization approach. Unfortunately, unlike the methods based on a correctly specified anchor set, these methods are not guaranteed to provide valid statistical inference (e.g., confidence intervals and p-values). In this paper, we propose a new method for DIF analysis under a multiple indicators and multiple causes (MIMIC) model for DIF. This method adopts a minimal \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L_1$$\end{document}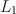 norm condition for identifying the latent trait distributions. Without requiring prior knowledge about an anchor set, it can accurately estimate the DIF effects of individual items and further draw valid statistical inferences for quantifying the uncertainty. Specifically, the inference results allow us to control the type-I error for DIF detection, which may not be possible with item purification and regularized estimation methods. We conduct simulation studies to evaluate the performance of the proposed method and compare it with the anchor-set-based likelihood ratio test approach and the LASSO approach. The proposed method is applied to analysing the three personality scales of the Eysenck personality questionnaire-revised (EPQ-R).
norm condition for identifying the latent trait distributions. Without requiring prior knowledge about an anchor set, it can accurately estimate the DIF effects of individual items and further draw valid statistical inferences for quantifying the uncertainty. Specifically, the inference results allow us to control the type-I error for DIF detection, which may not be possible with item purification and regularized estimation methods. We conduct simulation studies to evaluate the performance of the proposed method and compare it with the anchor-set-based likelihood ratio test approach and the LASSO approach. The proposed method is applied to analysing the three personality scales of the Eysenck personality questionnaire-revised (EPQ-R).

