
180 results
First-passage time for Sinai’s random walk in a random environment
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 29 November 2024, pp. 1-19
-
- Article
-
- You have access
- HTML
- Export citation
3 - Influential Observations
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 54-87
-
- Chapter
- Export citation
7 - Spurious Relations
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 161-185
-
- Chapter
- Export citation
Random walks on groups and superlinear-divergent geodesics
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems , First View
- Published online by Cambridge University Press:
- 21 November 2024, pp. 1-41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - Topics in representation theory of finite groups
-
-
- Book:
- Groups and Graphs, Designs and Dynamics
- Published online:
- 11 May 2024
- Print publication:
- 30 May 2024, pp 1-86
-
- Chapter
- Export citation

Harmonic Functions and Random Walks on Groups
-
- Published online:
- 16 May 2024
- Print publication:
- 23 May 2024
Scaling limit of the local time of random walks conditioned to stay positive
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 13 February 2024, pp. 1060-1074
- Print publication:
- September 2024
-
- Article
-
- You have access
- HTML
- Export citation
Diffusion of H2O in Smectite Gels: Obstruction Effects of Bound H2O Layers
-
- Journal:
- Clays and Clay Minerals / Volume 51 / Issue 1 / February 2003
- Published online by Cambridge University Press:
- 01 January 2024, pp. 9-22
-
- Article
-
- You have access
- Export citation
LINEAR GROWTH OF TRANSLATION LENGTHS OF RANDOM ISOMETRIES ON GROMOV HYPERBOLIC SPACES AND TEICHMÜLLER SPACES
- Part of
-
- Journal:
- Journal of the Institute of Mathematics of Jussieu / Volume 23 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 06 November 2023, pp. 1751-1795
- Print publication:
- July 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate the translation lengths of group elements that arise in random walks on the isometry groups of Gromov hyperbolic spaces. In particular, without any moment condition, we prove that non-elementary random walks exhibit at least linear growth of translation lengths. As a corollary, almost every random walk on mapping class groups eventually becomes pseudo-Anosov, and almost every random walk on
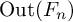 $\mathrm {Out}(F_n)$ eventually becomes fully irreducible. If the underlying measure further has finite first moment, then the growth rate of translation lengths is equal to the drift, the escape rate of the random walk.
$\mathrm {Out}(F_n)$ eventually becomes fully irreducible. If the underlying measure further has finite first moment, then the growth rate of translation lengths is equal to the drift, the escape rate of the random walk.We then apply our technique to investigate the random walks induced by the action of mapping class groups on Teichmüller spaces. In particular, we prove the spectral theorem under finite first moment condition, generalizing a result of Dahmani and Horbez.
Strong convergence of an epidemic model with mixing groups
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 01 September 2023, pp. 430-463
- Print publication:
- June 2024
-
- Article
-
- You have access
- HTML
- Export citation
-
We consider an SIR (susceptible
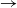 $\to$ infective
$\to$ infective 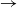 $\to$ recovered) epidemic in a closed population of size n, in which infection spreads via mixing events, comprising individuals chosen uniformly at random from the population, which occur at the points of a Poisson process. This contrasts sharply with most epidemic models, in which infection is spread purely by pairwise interaction. A sequence of epidemic processes, indexed by n, and an approximating branching process are constructed on a common probability space via embedded random walks. We show that under suitable conditions the process of infectives in the epidemic process converges almost surely to the branching process. This leads to a threshold theorem for the epidemic process, where a major outbreak is defined as one that infects at least
$\to$ recovered) epidemic in a closed population of size n, in which infection spreads via mixing events, comprising individuals chosen uniformly at random from the population, which occur at the points of a Poisson process. This contrasts sharply with most epidemic models, in which infection is spread purely by pairwise interaction. A sequence of epidemic processes, indexed by n, and an approximating branching process are constructed on a common probability space via embedded random walks. We show that under suitable conditions the process of infectives in the epidemic process converges almost surely to the branching process. This leads to a threshold theorem for the epidemic process, where a major outbreak is defined as one that infects at least 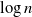 $\log n$ individuals. We show further that there exists
$\log n$ individuals. We show further that there exists 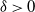 $\delta \gt 0$, depending on the model parameters, such that the probability that a major outbreak has size at least
$\delta \gt 0$, depending on the model parameters, such that the probability that a major outbreak has size at least 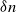 $\delta n$ tends to one as
$\delta n$ tends to one as 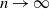 $n \to \infty$.
$n \to \infty$.
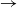
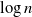
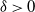
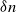
4 - Molecular Diffusion
-
- Book:
- An Introduction to Solute Transport in Heterogeneous Geologic Media
- Published online:
- 02 February 2023
- Print publication:
- 09 February 2023, pp 93-122
-
- Chapter
- Export citation
Toward random walk-based clustering of variable-order networks
-
- Journal:
- Network Science / Volume 10 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 22 December 2022, pp. 381-399
-
- Article
- Export citation
-
Higher-order networks aim at improving the classical network representation of trajectories data as memory-less order
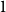 $1$
Markov models. To do so, locations are associated with different representations or “memory nodes” representing indirect dependencies between visited places as direct relations. One promising area of investigation in this context is variable-order network models as it was suggested by Xu et al. that random walk-based mining tools can be directly applied on such networks. In this paper, we focus on clustering algorithms and show that doing so leads to biases due to the number of nodes representing each location. To address them, we introduce a representation aggregation algorithm that produces smaller yet still accurate network models of the input sequences. We empirically compare the clustering found with multiple network representations of real-world mobility datasets. As our model is limited to a maximum order of
$1$
Markov models. To do so, locations are associated with different representations or “memory nodes” representing indirect dependencies between visited places as direct relations. One promising area of investigation in this context is variable-order network models as it was suggested by Xu et al. that random walk-based mining tools can be directly applied on such networks. In this paper, we focus on clustering algorithms and show that doing so leads to biases due to the number of nodes representing each location. To address them, we introduce a representation aggregation algorithm that produces smaller yet still accurate network models of the input sequences. We empirically compare the clustering found with multiple network representations of real-world mobility datasets. As our model is limited to a maximum order of
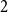 $2$
, we discuss further generalizations of our method to higher orders.
$2$
, we discuss further generalizations of our method to higher orders.
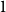
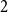
An elementary approach to component sizes in critical random graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 11 November 2022, pp. 1228-1242
- Print publication:
- December 2022
-
- Article
- Export citation
John’s walk
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 10 November 2022, pp. 473-491
- Print publication:
- June 2023
-
- Article
- Export citation
-
We present an affine-invariant random walk for drawing uniform random samples from a convex body
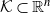 $\mathcal{K} \subset \mathbb{R}^n$
that uses maximum-volume inscribed ellipsoids, known as John’s ellipsoids, for the proposal distribution. Our algorithm makes steps using uniform sampling from the John’s ellipsoid of the symmetrization of
$\mathcal{K} \subset \mathbb{R}^n$
that uses maximum-volume inscribed ellipsoids, known as John’s ellipsoids, for the proposal distribution. Our algorithm makes steps using uniform sampling from the John’s ellipsoid of the symmetrization of
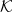 $\mathcal{K}$
at the current point. We show that from a warm start, the random walk mixes in
$\mathcal{K}$
at the current point. We show that from a warm start, the random walk mixes in
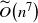 ${\widetilde{O}}\!\left(n^7\right)$
steps, where the log factors hidden in the
${\widetilde{O}}\!\left(n^7\right)$
steps, where the log factors hidden in the
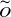 ${\widetilde{O}}$
depend only on constants associated with the warm start and desired total variation distance to uniformity. We also prove polynomial mixing bounds starting from any fixed point x such that for any chord pq of
${\widetilde{O}}$
depend only on constants associated with the warm start and desired total variation distance to uniformity. We also prove polynomial mixing bounds starting from any fixed point x such that for any chord pq of
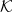 $\mathcal{K}$
containing x,
$\mathcal{K}$
containing x,
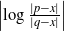 $\left|\log \frac{|p-x|}{|q-x|}\right|$
is bounded above by a polynomial in n.
$\left|\log \frac{|p-x|}{|q-x|}\right|$
is bounded above by a polynomial in n.
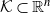
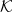
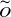
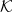
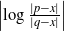
Central limit theorems for counting measures in coarse negative curvature
- Part of
-
- Journal:
- Compositio Mathematica / Volume 158 / Issue 10 / October 2022
- Published online by Cambridge University Press:
- 03 November 2022, pp. 1980-2013
- Print publication:
- October 2022
-
- Article
- Export citation
-
We establish central limit theorems for an action of a group
 $G$ on a hyperbolic space
$G$ on a hyperbolic space 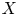 $X$ with respect to the counting measure on a Cayley graph of
$X$ with respect to the counting measure on a Cayley graph of  $G$. Our techniques allow us to remove the usual assumptions of properness and smoothness of the space, or cocompactness of the action. We provide several applications which require our general framework, including to lengths of geodesics in geometrically finite manifolds and to intersection numbers with submanifolds.
$G$. Our techniques allow us to remove the usual assumptions of properness and smoothness of the space, or cocompactness of the action. We provide several applications which require our general framework, including to lengths of geodesics in geometrically finite manifolds and to intersection numbers with submanifolds.


Coexistence of lazy frogs on
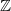 ${\mathbb{Z}}$
${\mathbb{Z}}$
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 28 June 2022, pp. 702-713
- Print publication:
- September 2022
-
- Article
- Export citation
-
We study the so-called frog model on
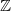 ${\mathbb{Z}}$
with two types of lazy frogs, with parameters
${\mathbb{Z}}$
with two types of lazy frogs, with parameters 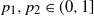 $p_1,p_2\in (0,1]$
respectively, and a finite expected number of dormant frogs per site. We show that for any such
$p_1,p_2\in (0,1]$
respectively, and a finite expected number of dormant frogs per site. We show that for any such 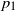 $p_1$
and
$p_1$
and 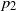 $p_2$
there is positive probability that the two types coexist (i.e. that both types activate infinitely many frogs). This answers a question of Deijfen, Hirscher, and Lopes in dimension one.
$p_2$
there is positive probability that the two types coexist (i.e. that both types activate infinitely many frogs). This answers a question of Deijfen, Hirscher, and Lopes in dimension one.
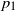
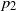
Unusually large components in near-critical Erdős–Rényi graphs via ballot theorems
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 5 / September 2022
- Published online by Cambridge University Press:
- 11 February 2022, pp. 840-869
-
- Article
- Export citation
-
We consider the near-critical Erdős–Rényi random graph G(n, p) and provide a new probabilistic proof of the fact that, when p is of the form
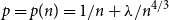 $p=p(n)=1/n+\lambda/n^{4/3}$
and A is large,
where
$p=p(n)=1/n+\lambda/n^{4/3}$
and A is large,
where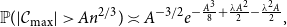 \begin{equation*}\mathbb{P}(|\mathcal{C}_{\max}|>An^{2/3})\asymp A^{-3/2}e^{-\frac{A^3}{8}+\frac{\lambda A^2}{2}-\frac{\lambda^2A}{2}},\end{equation*}
\begin{equation*}\mathbb{P}(|\mathcal{C}_{\max}|>An^{2/3})\asymp A^{-3/2}e^{-\frac{A^3}{8}+\frac{\lambda A^2}{2}-\frac{\lambda^2A}{2}},\end{equation*}
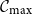 $\mathcal{C}_{\max}$
is the largest connected component of the graph. Our result allows A and
$\mathcal{C}_{\max}$
is the largest connected component of the graph. Our result allows A and 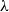 $\lambda$
to depend on n. While this result is already known, our proof relies only on conceptual and adaptable tools such as ballot theorems, whereas the existing proof relies on a combinatorial formula specific to Erdős–Rényi graphs, together with analytic estimates.
$\lambda$
to depend on n. While this result is already known, our proof relies only on conceptual and adaptable tools such as ballot theorems, whereas the existing proof relies on a combinatorial formula specific to Erdős–Rényi graphs, together with analytic estimates.
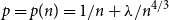
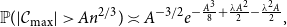
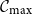
8 - Applications
- from Part III - Discrete Functional Analysis
-
- Book:
- Classical and Discrete Functional Analysis with Measure Theory
- Published online:
- 06 January 2022
- Print publication:
- 20 January 2022, pp 333-402
-
- Chapter
- Export citation
4 - Overview of Mathematical Tools
- from Part I - Fundamentals
-
- Book:
- Electronic Sensor Design Principles
- Published online:
- 23 December 2021
- Print publication:
- 06 January 2022, pp 189-235
-
- Chapter
- Export citation
INTERACTING QUARTER-PLANE LATTICE WALK PROBLEMS: SOLUTIONS AND PROOFS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 105 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 05 November 2021, pp. 339-340
- Print publication:
- April 2022
-
- Article
-
- You have access
- HTML
- Export citation
