
200 results
Exponential turnpike property for particle systems and mean-field limit
- Part of
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 27 January 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The turnpike property for mean-field optimal control problems
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 35 / Issue 6 / December 2024
- Published online by Cambridge University Press:
- 12 February 2024, pp. 733-747
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the turnpike phenomenon for optimal control problems with mean-field dynamics that are obtained as the limit
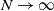 $N\rightarrow \infty$ of systems governed by a large number
$N\rightarrow \infty$ of systems governed by a large number 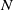 $N$ of ordinary differential equations. We show that the optimal control problems with large time horizons give rise to a turnpike structure of the optimal state and the optimal control. For the proof, we use the fact that the turnpike structure for the problems on the level of ordinary differential equations is preserved under the corresponding mean-field limit.
$N$ of ordinary differential equations. We show that the optimal control problems with large time horizons give rise to a turnpike structure of the optimal state and the optimal control. For the proof, we use the fact that the turnpike structure for the problems on the level of ordinary differential equations is preserved under the corresponding mean-field limit.
From NeurODEs to AutoencODEs: A mean-field control framework for width-varying neural networks
- Part of
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 08 February 2024, pp. 1-43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hybrid impedance and admittance control for optimal robot–environment interaction
-
- Article
-
- You have access
- HTML
- Export citation
Linear quadratic approximation of rationally inattentive control problems
-
- Journal:
- Macroeconomic Dynamics / Volume 28 / Issue 6 / September 2024
- Published online by Cambridge University Press:
- 08 November 2023, pp. 1371-1393
-
- Article
-
- You have access
- HTML
- Export citation
On the joint survival probability of two collaborating firms
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 01 August 2023, pp. 369-384
- Print publication:
- June 2024
-
- Article
-
- You have access
- HTML
- Export citation
Subject specific optimal control of powered knee exoskeleton to assist human lifting tasks under controlled environment
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multistage approach for trajectory optimization for a wheeled inverted pendulum passing under an obstacle
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Invariant ideals and their applications to the turnpike theory
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 66 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 12 January 2023, pp. 959-975
- Print publication:
- September 2023
-
- Article
- Export citation
Estimation of safe flight envelope considering manoeuver overload based on cost-limited reachable set
-
- Journal:
- The Aeronautical Journal / Volume 127 / Issue 1312 / June 2023
- Published online by Cambridge University Press:
- 01 December 2022, pp. 950-963
-
- Article
- Export citation
Optimal management and valuation of a natural resource: the case of optimal harvesting
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 11 March 2022, pp. 674-694
-
- Article
- Export citation
Stabilisation, tracking and disturbance rejection control design for the UAS-S45 Bálaam
-
- Journal:
- The Aeronautical Journal / Volume 126 / Issue 1303 / September 2022
- Published online by Cambridge University Press:
- 10 March 2022, pp. 1474-1496
-
- Article
- Export citation
Quaternion-based state-dependent differential Riccati equation for quadrotor drones: Regulation control problem in aerobatic flight
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparing the risk of low-back injury using model-based optimization: Improved technique versus exoskeleton assistance
- Part of
-
- Journal:
- Wearable Technologies / Volume 2 / 2021
- Published online by Cambridge University Press:
- 01 October 2021, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Structure-preserving deep learning
-
- Journal:
- European Journal of Applied Mathematics / Volume 32 / Issue 5 / October 2021
- Published online by Cambridge University Press:
- 27 May 2021, pp. 888-936
-
- Article
-
- You have access
- Open access
- Export citation
Multi-agent cooperative multi-model adaptive guidance law
-
- Journal:
- The Aeronautical Journal / Volume 125 / Issue 1288 / June 2021
- Published online by Cambridge University Press:
- 04 March 2021, pp. 1103-1129
-
- Article
- Export citation
